文章をBlockChainで管理する
文章をBlockChainで管理する
今更感がありますが、BlockChainについて、技術的な点について結構曖昧であったので、調べなおしたりしました。
P2Pの多数決の理屈ばかり強調されますが、実際のところどうなっているのか、自分で実際に実装を行いながら、ブロックチェーンを組んでみて確認してみました。
BlockChainとは
- BitCoinに代表される仮想通貨の分散データベースシステム
- ハッシュアルゴリズムにより、事実上の改竄が不可能
- ドキュメントによっては、合意形成や、ブロックチェーンが意図しない方向にチェーンが伸びてしまった場合の取扱まで含んだりする
(今回のスコープはp2pは含まず、オフラインで検証しました)
BlockChainを理解するには何を知っていると便利か
- hash関数
- hash関数を使った応用例各種
- 簡単なP2P
コンピュータにおけるhashの使い方
hashはいろいろな値(文字列やなんでも)を、特定の数値の範囲にうまくエンベッティングする技術で、この仕組を使うと、キーからバリューの引き出しがO(1)の計算量で行えます。

図1. HashMapの構造
hashによる分散化はあらゆるところで行われており、エンジニアにとって馴染みのあるものでは、hashmap, KVS, Hadoopなどがキーをハッシュ化することでうまくやっています。


図3. 国会で説明された様子[1]
BlockChainまで発展する
BlockChainはこのhashによる鎖を連ねることで、鎖が維持できるているかどうかで、データが正しいかどうかの検証が行えます。

図3. 正常系(不正がない場合)

図4. 異常系(なんらかの編集があった場合)(+電子証明が使われます)
単純なこの仕組に加えて、様々にP2Pで動作を確認と保証する仕組みをいれてBlockChainというらしいです(広義すぎるので分散台帳技術はちょっと和訳として不適切だと思う)
BitCoinにある採掘という作業
BitCoinには採掘という作業があって、GPUをゴリゴリ回してお金を得るみたいなことをやっている人たちがいます。これは、ハッシュ値の先頭が0000000〜とかになるように、データの中にnonceというフィールドを追加して調整しています。 最初に特定条件に一致するハッシュ値を計算できた人がインセンティブをもらい、次に繋がる鎖を生成します。これはマイニングしている人が、マイニングするモチベーションであり、ビットコインという通貨的特性と相性がいい理由でもあります。
P2Pでは同時に生成してしまう可能性がありますが、同時に生成してしまったら、後続に続く鎖の数が大きい方が優先されます。
国会で今話題になっている公文書偽造などの問題には転用可能でしょうか。
公文書管理におけるブロックチェーンの利用
この資料によると、費用対効果の視点でコストが嵩みすぎるという課題が挙げられていますが、それは、nonceによる採掘難易度に依存するし、衝突困難性は採掘と関係がないので、私はできると考えています。
また、直接、データをブロックチェーンに入れるのではなく、公文書のハッシュ値やフィンガープリントに該当するものをいれればいいはずだと思うのですが。
夏目漱石の小説をブロックチェーンに組み込む
このようなコードを作成しました。 前のhashの情報を記憶しつつ、データを持ち、nonceの条件を満たすものを探し、一致したら、ブロックをjsonで吐き出すものです。
def _gen_block(arg): source_host, data, prev_hash = arg now = time.time() loc = datetime.fromtimestamp(now) timestamp = loc.timestamp() while True: nonce = random.randint(0, 100000000000000) block = { \ 'timestamp':timestamp, \ 'source_host':source_host, \ 'data':data, \ 'prev_hash': prev_hash, \ 'nonce':nonce, } next_hash = hashlib.sha256(bytes(json.dumps(block),'utf8')).hexdigest() # 先頭のN字が"0"ならば、採用 size = 1 if next_hash[:size] == '0'*size: break open(f'cache/{next_hash}', 'w').write( json.dumps(block, indent=2, ensure_ascii=False) ) return block, next_hash start_block, next_hash = _gen_block(('http://localhost:1200', 'Ground Zero', hashlib.sha256(bytes('0', 'utf8')).hexdigest())) for line in open('stash/kokoro.txt'): line = line.strip() block, next_hash = _gen_block(('http://localhost:1200', line, next_hash) )
nonce値の難易度による夏目漱石の「坊っちゃん」を全部ブロックチェーン化するまでの計算時間
先頭が0一個、0二個、0三個、0四個と評価しました。
わかりきっていたことですが、だいぶ計算時間が違います。
CPU
CPU MHz: 1550.000 CPU max MHz: 3800.0000 CPU min MHz: 1550.0000AMD BogoMIPS: 7585.48en 5 1500X Quad-Core Processor
$ uname -a Linux PrintzEugen 4.13.0-32-generic #35-Ubuntu SMP Thu Jan 25 09:13:46 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux

図5. 計算の難易度ごとの必要計算時間
インセンティブが働かない公文書管理などの環境では、nonce値はないか、小さい値でいいのではないかと考えいています。
過去への遡及
BlockChainはその名の通り、鎖状になっているので、偽造されたものでない限り、最初の発行者のデータにたどり着けるような仕組みになっています。
坊っちゃんの最後のセリフから、最初データまで辿ってみましょう。
最後のセリフ
hash => 00ce7c3a81315250d7abc2d99f177b2ffb442334644044ea89f1d6e435845d86 っtimestamp': 1521708677.710969, 'source_host': 'http://localhost:1200', 'data': '私は私の過去を善悪ともに他ひとの参考に供するつもりです。しかし妻だけはた唯た一人の例外だと承知して下さい。私は妻には何にも知らせたくないのです。妻が己おのれの過去に対してもつ記憶を、なるべく純白に保存しておいてやりたいのが私の。一ゆいいつの希望なのですから、私が死んだ後あとでも、妻が生きている以上は、あなた限りに打ち明けられた私の秘密として、すべてを腹の中にしまっておいて下さい 」', 'prev_hash': '072c69c315bc6c2839122f1b5566df41dfb64f9c489b44441056bab8b0ed9104', 'nonce': 18180102876915}
最初まで遡ります
$ python3 phyllis.py 私は私の過去を善悪ともに他ひとの参考に供するつもりです。しかし妻だけはたった一人の例外だと承知して下さい。私は妻には何にも知らせたくないのです。妻が己おのれの過去に対してもつ記憶を、なるべく純白に保存しておいてやりたいのが私の唯一ゆいいつの希望なのですから、私が死んだ後あとでも、妻が生きている以上は、あなた限りに打ち明けられた私の秘密として、すべてを腹の中にしまっておいて下さい。」 しかし私は今その要求を果たしました。もう何にもする事はありません。この手紙があなたの手に落ちる頃ころには、私はもうこの世にはいないでしょう。とくに死んでいるでしょう。妻は十日ばかり前から市ヶ谷いちがやの叔母おばの所へ行きました。叔母が病気で手が足りないというから私が勧めてやったのです。私は妻の留守の間あいだに、この長いものの大部分を書きました。時々妻が帰って来ると、私はすぐそれを隠しました。 私が死のうと決心してから、もう十日以上になりますが、その大部分はあなたにこの長い自叙伝の一節を書き残すために使用されたものと思って下さい。 ... (中間の表現) ... 私わたくしはその人を常に先生と呼んでいた。だからここでもただ先生と書くだけで本名は打ち明けない。これは世間を憚はばかる遠慮というよりも、その方が私にとって自然だからである。私はその人の記憶を呼び起すごとに、すぐ「先生」といいたくなる。筆を執とっても心持は同じ事である。よそよそしい頭文字かしらもじなどはとても夏目漱石と私ない。 こころ Ground Zero
Ground Zeroとは、今回、作成したblockchainの最初の値になるシードのデータです。
様々なブロックチェーンの応用例
このように、情報が正しければ遡及を行え、すべてのレコードを引き出すことも可能になります。
改竄されていたりすると、不自然なところで遡ることができなくなったり、改竄されたデータを元にブロックチェーンをつなげてしまったと解釈できそうです。
この特徴を利用して、食品安全の仕組みに組み込むことで、肉などの偽装や、安全管理などが行えることが期待できます[3]。
またブロックチェーンの偽装が難しい問題で、戸籍などをブロックチェーン化してしまうのもあるようです[4]。
作成したコード
offline.py 単一マシンで、文章のブロックチェーンを構築します。 ハードコードされたsizeで計算の難易度を指定できます
$ python3 offline.py
phyllis.py ブロックチェーンのハッシュ値から過去のブロックを辿って、ルートまで逆引きするプログラムです
$ python3 phyllis.py
参考文献
RocksDBをさまざまな言語(C++, Rust, Kotlin, Python)で利用する
RocksDBをさまざまな言語(C++, Rust, Kotlin, Python)で利用する
InstagramのCassandraのバックエンドをJVMベースのものから、RocksDBに切り替えたというニュースが少し話題になりました。
CassandraのJVMは定期的にガーベジコレクタが走って、よろしくないようです。
P99というテストケースではデフォルトのJVMからRocksDBに張り替えたところ10倍近くのパフォーマンスが得られたとのことです。
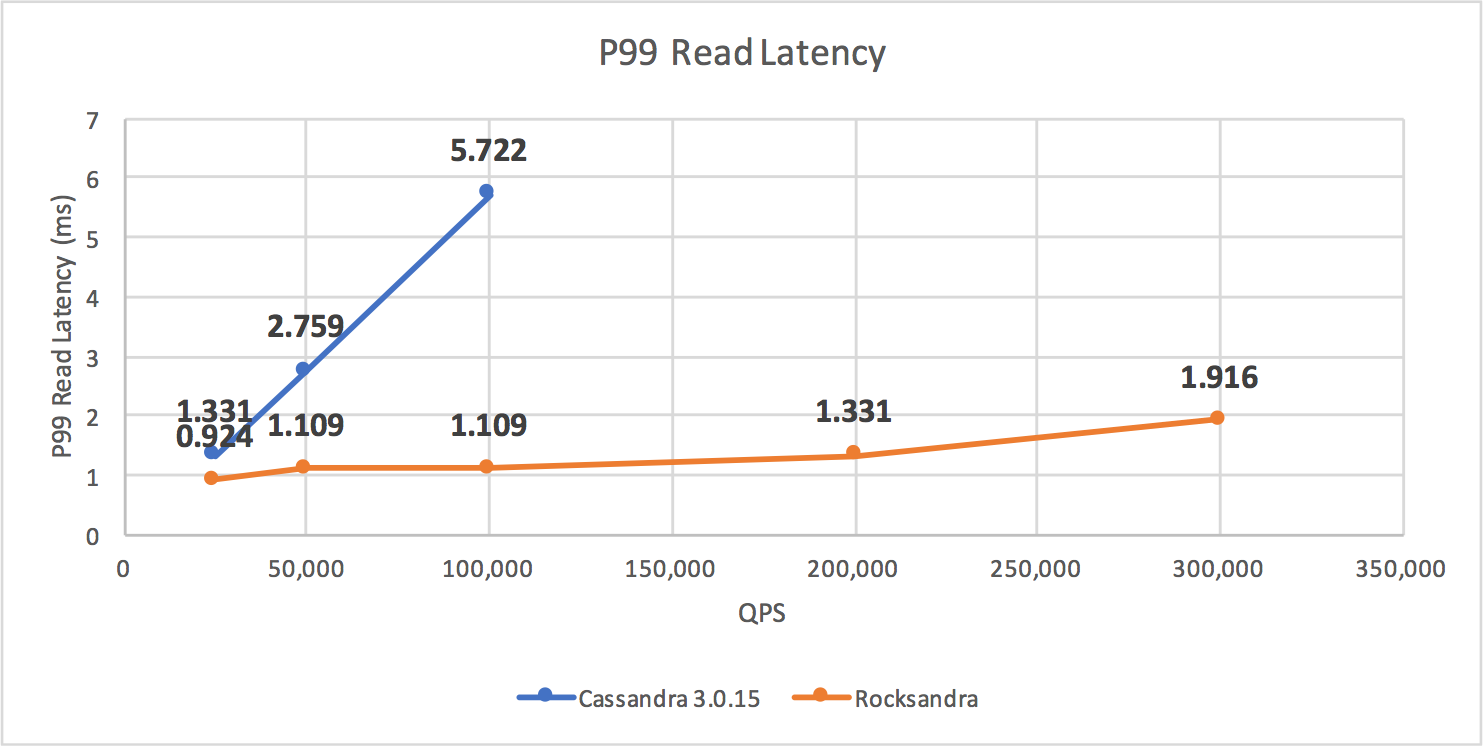
データ分析でもメモリ収まりきらないけど、Sparkのような分散システムを本格に用意する必要がない場合、NVMe上にLevelDB, RocksDBなどのKVSを用意して加工することがあります。
ローカルで動作させるには最強の速度だし、文句のつけようもない感じです。
LSMというデータ構造で動いており、比較対象としてよく現れるb-treeより書き込み時のパフォーマンスは良いようです[1]
LSMのデータ構造では挿入にO(1)の計算量が必要で、検索と削除にO(N)の計算量が必要です。
前提とやりたいこと
- RocksDBはSSDやnvmeで爆速を引き出すパーマネントKVSです
- LevelDB, RocksDBはPythonで分析するときの必勝パターンに自分のスキルの中に入っているので、ぜひともRocksDBも開拓したい
- RocksDBはC++のインターフェースが美しい形で提供さており、他言語とのBindingが簡単そう
もくじ
- 1. RocksDBのインストール(Linux)
- 2. Pure C++でのRocksDBの利用
- 3. C++ Bindingの方針
- 4. Rustでの利用
- 5. Kotlinでの利用
- 6. Python(BoostPython)での利用
これらのコードはこちらにあります。
1. RocksDBのインストール
Ubuntuですと標準レポジトリにないので、ビルドしてインストールする必要があります
(GCC >= 7.2.0, cmakeなどの基本的なbuild-toolsが必要なので、ご自身のOSに合わせて用意してください)
$ git clone git@github.com:facebook/rocksdb.git $ cd rocksdb $ mkdir build $ cd build $ cmake .. $ make -j12 $ sudo make install
2. Pure C++
注意 最新のClangでは構文エラーでコンパイラが通らないので、gcc(g++ >= 7.2.0)を利用必要があります
C++でRocksDBは記述されているので、C++でのインターフェースが最も優れています。
DBのopen, get, putはこのようなIFで提供されています
DB* db; Options options; // Optimize RocksDB. This is the easiest way to get RocksDB to perform well options.IncreaseParallelism(); // create the DB if it's not already present options.create_if_missing = true; // open DB string kDBPath = "test.rdb"; Status s = DB::Open(options, kDBPath, &db); assert(s.ok()); // Put key-value s = db->Put(WriteOptions(), "key1", "value"); assert(s.ok()); // get value string value; s = db->Get(ReadOptions(), "key1", &value); assert(s.ok()); assert(value == "value");
Pinableという考え方があり、Pinableを用いると、データのコピーが発生しない(memcpyは動作しない)ので、高速性が要求されるときなど良さそうです
PinnableSlice pinnable; s = db->Get(ReadOptions(), db->DefaultColumnFamily(), "key1", &pinnable); // メモリコピーコストが発生しない
3. C++bindings
C/C++でラッパーを書くことで任意のCのshared objectが利用できる言語とバインディングを行うことができます。
extern "C"で囲んだ範囲が外部のプログラムで見える関数になります。
extern "C" { void helloDB(const char* dbname); int putDB(const char* dbname, const char* key, const char* value); int getDB(const char* dbname, const char* key, char* value); int delDB(const char* dbname, const char* key); int keysDB(const char* dbname, char* keys); }
サンプルのshared objectを作成するコードを用意したので、参考にしていただけると幸いです。
$ cd cpp-shared
$ make
$ ls librocks.so
$ ldd librocks.so
linux-vdso.so.1 => (0x00007fff04ccd000)
librocksdb.so.5 => /usr/lib/x86_64-linux-gnu/librocksdb.so.5 (0x00007fdaf33ab000)
libstdc++.so.6 => /usr/lib/x86_64-linux-gnu/libstdc++.so.6 (0x00007fdaf3025000)
libgcc_s.so.1 => /lib/x86_64-linux-gnu/libgcc_s.so.1 (0x00007fdaf2e0e000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fdaf2a2e000)
libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0 (0x00007fdaf280f000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007fdaf24b9000)
/lib64/ld-linux-x86-64.so.2 (0x00007fdaf3e77000)
4. Rust
RustではC++のバインディングを利用してRocksDBにデータを格納したり取り出したりする方法を示します。
サンプルコードを動作させるには、以下のようにterminalを操作します。
$ cd rust $ export LD_LIBRARY_PATH=../cpp-shared/:$LD_LIBRARY_PATH $ make $ ./sample
Rustではstructで定義したものをimplで拡張していくのですが、例えば、putに関してはこのように設計しました。
C/C++などで文字の終了が示される\0が入らないため、このようなformatで文字を加工してC++に渡しています
pub struct Rocks { pub dbName:String, pub cursol:i32, } impl Rocks { pub fn new(dbName:&str) -> Rocks { let outName = format!("{}\0", dbName); unsafe { helloDB( outName.as_ptr() as *const c_char) }; Rocks{ dbName:outName.to_string(), cursol:0 } } } impl Rocks { pub fn put(&self, key:&str, value:&str) -> i32 { let dbName = format!("{}\0", &*(self.dbName)); let key = format!("{}\0", key); let value = format!("{}\0", value); let sub = unsafe { putDB( (&*dbName).as_ptr() as *const c_char, key.as_ptr() as *const c_char, value.as_ptr() as *const c_char) }; sub } }
5. Kotlin
Kotlin, JavaではGradleに追加することで簡単に利用可能になります。
compile group: 'org.rocksdb', name: 'rocksdbjni', version: '5.10.3'
Interfaceも整理されており、以下のように簡単に、put, get, iterate, deleteが行えます
import org.rocksdb.RocksDB import org.rocksdb.Options fun main(args : Array<String>) { RocksDB.loadLibrary() // DBをなければ作成して開く val options = Options().setCreateIfMissing(true) val db = RocksDB.open(options, "/tmp/kotlin.rdb") // データのput val key1 = "key1".toByteArray() val value1 = "value1".toByteArray() db.put(key1, value1) val key2 = "key2".toByteArray() val value2 = "value2".toByteArray() db.put(keygetvalue2) val bvalue = db.get(key1) println(String(bvalue)) // seek to end val iter = db.newIterator() iter.seekToFirst() while( iter.isValid() ) { println("${String(iter.key())} ${String(iter.value())}") iter.next() } // データの削除 db.delete(key1) db.delete(key2) db.close() }
実行
$ cd kotlin $ ./gradlew run -Dexec.args="" Starting a Gradle Daemon, 1 busy Daemon could not be reused, use --status for details :compileKotlin UP-TO-DATE :compileJava UP-TO-DATE :copyMainKotlinClasses UP-TO-DATE :processResources NO-SOURCE :classes UP-TO-DATE :runApp value1 key1 value1 key2 value2 BUILD SUCCESSFUL
6. Python
PythonはBoostPythonを用いると簡単にRocksDB <-> Pythonをつなぐことができます。
Python3とも問題なくBindingすることができて便利です。
ネット上のBoostPythonのドキュメントにはDeprecatedになった大量のSyntaxが入り混じっており、大変混沌としていたので、一つ確実に動く基準を設けて書くのが良さそうでした
CPPファイルの定義
CPPでRocksDBを扱うクラスを定義し、諸々実装を行います
#include <boost/python.hpp> #include <string> #include <cstdio> #include <string> #include <iostream> #include "rocksdb/db.h" #include "rocksdb/slice.h" #include "rocksdb/options.h" using namespace rocksdb; namespace py = boost::python; class RDB{ private: DB* db; public: std::string dbName; RDB(std::string dbName): dbName(dbName){ Options options; options.IncreaseParallelism(); options.create_if_missing = true; Status s = DB::Open(options, dbName, &(this->db)); }; RDB(py::list ch); void put(std::string key, std::string value); std::string get(std::string key); void dlt(std::string key); py::list keys(); }; void RDB::put(std::string key, std::string value) { this->db->Put(WriteOptions(), key, value); } ....
pythonの実装
Pythonで用いるのは簡単で、shared object名と同名のやつを読み出して、インスタンスを作成して、関数を叩くだけです(めっちゃ簡単)
from rdb import RDB # create drow instance db = RDB('/tmp/boost.rdb') # access the word and print it print( db.dbName ) db.put('key1', 'val1') val = db.get('key1') print(val) db.put('key2', 'val2') print(db.keys()) val = db.delete('key1')
NVMeとHDDとのパフォーマンスの違い
もっと決定的に処理速度の差が出ると思ったのですが、そんなに変わらないという感じでした。

まとめ
ユースケースとして、転置インデックスを巨大なデータ構造そのままで、力でゴリゴリ押ししようとしてもメモリ上に乗らなかったりするとき、KVSとしてデータをファイルに書き出すことで効率的に行えたりします。(例えばWikipediaの記事全量からtf-idfを計算するときなど)
Valueは任意のシリアライザーでシリアライズしておく必要があり、Pythonだとpickle, KotlinだとKotlinx.serialize, Rustだとserdeなどが便利です。
今まではLevelDB(RocksDBのFork元)を用いていたのですが、PythonとC++しか実用的な装系がなく、もっといろんな言語とBindingしようとすると、RocksDBのほうが便利だと思いました。
参考文献
Deep Learningによる分布推定
Deep Learningによる分布推定
例えばこのような連続する事象の確率分布がある

横軸を時系列、縦軸を例えば企業の株価上がり下がり幅などとした場合、何か大局的なトレンドど業界のトレンドと国などのトレンドが入り混じり、単純な正規分布やベータ分布などを仮定できるものではなくなります。
このとき、系列から学習して未来や未知の分布を直接求めることができ、かつ、異常値の検知などもしやすくすることなどを示したいと思います
各系列で十分サンプリングでき、かつ、連続する事象の確率分布に対して予想したい場合
例えば、この分布が日付のような連続なものとして扱われる場合、ある日のデータがサンプルできなかったり、まだサンプルが済んでない未来に対して予想しようとした場合、そういうことは可能なのでしょうか。
ベイズでも可能ですが、せっかく十分にサンプリングできているので、ディープラーニングを用いて、KL距離、mean squre error距離などの距離関数で損失を決定して、分布を仮定せず、直接、確率分布を予想可能であることを示したいと思います
上記の分布を生成する関数
正規分布2つから導かれる頻度を計算していって、最大となる点で割ることにより確率の密度を計算します
SIZEで定義される最大の値(時間)に対して、少しずつi(時間)をずらすことで、分布の中心点もまた変わっていくように、設計しました
import numpy as np SIZE = 25000 for i in range(SIZE): sample1 = np.random.normal(loc=-2*np.sin(i/10), scale=1, size=10000) sample2 = np.random.normal(loc=5*np.cos(i/10), scale=2, size=30000)
微妙に距離がある2つの分布から構成されており、i(時系列)でlocのパラメータが変化し、支配的な正規分布と非支配的な分布が入りまじります
時刻tから分布Dを予想するための距離関数
用いた損失関数は、Kullback-Leibler情報量 + 平均誤差の混合した損失関数です
確率分布のような図が、問題なく各時間tにおいてDが定義できるので、何か特別な細工をせずとも、学習が可能です。
コードで表すとこんな感じです
def custom_objective(y_true, y_pred): mse = K.mean(K.square(y_true-y_pred), axis=-1) y_true_clip = K.clip(y_true, K.epsilon(), 1) y_pred_clip = K.clip(y_pred, K.epsilon(), 1) kullback_leibler = K.sum(y_true_clip * K.log(y_true_clip / y_pred_clip), axis=-1) return mse + kullback_leibler / 1000.0
数式で表現すると以下のようになります

k:定数,0.001と今回は設定
これは、Image to Image[1]の論文と、この発表[2]に参考にしました(有効性の検証は別途必要でしょう)
問題設定1. 欠けた部分から、もとの分布を予想する
ある日のデータが何らの原因で欠けてしまった場合、周りの傾向を学習することで、欠けてしまったログから予想を試みます

ところどころ、データが欠損しています。
これに対してDeepLearningのモデルで欠けた分布の予想をしていきましょう

このように周辺の値が非常に小さくなる分布となる非常に細かいところは欠けでしまいました(多分活性化関数の工夫の次第です)が、おおよそ再現できることがわかりました。
ディープラーニングはサンプリング数が十分に多ければ、(正規分布、ベータ分布などの)分布を仮説せずとも、直接、求めることができることがわかりました。
操作方法
$ python3 distgen.py > dump.txt # 幾つかの分布からランダムに値をサンプリング $ python3 make-dataset.py --invert # dump.txtを転地する $ python3 make-dataset.py --np # numpyのアレイにする $ python3 unlimited-dimention-spectre.py --train #学習 $ python3 unlimited-dimention-spectre.py --predict #抜けた穴の予想
問題設定2. 異常値検知を行う
検定の話ですが、一般的に(95%などの)信頼区間に入るかどうかがよく使われる手法です。
信頼区間は確率密度関数が判明している必要がありますが、複雑な分布を本質的にもつようなものに当て推量で分布を仮定することが、事前に知識を外挿していることと等価であり、やらなくて済むケースが今回のケースです。


この時、この分布が仮に確率分布と定義できるようなサンプリングをした場合、異常値の検出は、あるサンプルした点から95%の全体の面積を占める範囲外であるとき、と考えられれそうです。(これはディープラーニングの出力値が、離散値なので上から順に足し算、下から順に足し算でかんたんに求まります)
例えば、上記のような端っこの方に①のポイントにサンプルされたような場合、それが異常値かどうかは、②までの積分値(足し算)に、③の全体を割って、0.05以下になるとかと定義することが可能そうです
(今回は十分に未来の確率密度までディープラーニングは学習できたので、一度作ったモデルでモデルの予想する分布から外れたところにあるものが、異常とみなせそうです)
操作方法
$ python3 distgen.py > dump.txt # 幾つかの分布からランダムに値をサンプリング $ python3 make-dataset.py --invert # dump.txtを転地する $ python3 make-dataset.py --np # numpyのアレイにする $ python3 unlimited-dimention-spectre.py --train #学習 $ python3 unlimited-dimention-spectre.py --future #未来の100系列を予想
少し細工した点
入力に対して、時系列のラベルは通常、一次元の数字なのですが、これを利用するとうまく収束しないです。(値が大きすぎるか小さすぎ、ネットワークが安定しない)
Dirty Hackっぽいですが、数字を2進数にしてN次元にします
ex) 5 -> [0, 0, 1, 0, 1]
このようにすると、今回のケースでは、うまく収束します
コード
まとめ
- 何か分布を仮定しない→知識の外挿なしなので、全く未知のこと、ドメイン知識がないことをやろうとするときなど便利です
- その代わり完全な分布を各時系列などで構築している必要があり、これはどのようにデータを集めるかが鍵なきがします
- データがそんなにないよ、ここまでパワフルな予想が必要がないよってときには、prophetがおすすめです
そもそも、DeepLearningは無限の重ね合わせによりガウス過程を構築していることと等価[3](これは感覚的に理解できます)ので、こういったタスクに実は向いているのではないでしょうか。テストデータからのハズレ具合による確信度の低さ(これはベイズの確信度の低さに該当するみたいです)みたいなのは今回利用していませんが、利用することはできそうです。つまり、もう一つのモデルの可能性として、ここまで大量の分布がサンプリングできないとき、testデータとの差を最小化するポイントを見つけることで、ガウス過程により導出したことと等価とみなせるモデルが構築可能でしょう。それでも、十分な期間とそれに該当するデータサンプル量が必要となりますが。
参考文献
pytorch-pix2pix
pytorch-pix2pix
一年ほどまえ、pix2pix系のネットワークを編集して色々おもしろいことができると言うことを示しました。当時はブログ等に何かポストする際に再現可能なコードを添付することを諸事情により十分にできなかったのですが、pytorchに元論文の実装に近いImage to Imageが登場し、かなり強力で表現力の高いネットワークであったので、いくつか再現性とデータセットを再び添付して公開したいと思います
- 白黒画像に色をつける
- 不完全な欠損した画像を復元する
- フォントのスタイル変換
Image-to-Imageのネットワークと論文とその実装系のForkのForkになります。
素晴らしい編集力と、コードの一般化を行った方々に感謝を申し上げます
A fork of PyTorch implementation of Image-to-Image Translation Using Conditional Adversarial Networks.
Based on pix2pix by Isola et al.
Update
Image to Imageの初版は2016年12月時点の論文ですが、2017年12月にもarXivにversion2が投稿されています。
学習が安定しているかつ、複雑なネットワークにも対応していて、U-netと論文中では言われていますが、コード中ではResisual Blockなどと表現されており、入力情報を忘れないように細工をする仕組みが十分に入っていることがあるようです(経験的にこのネットワークはコンピュータリソースが十分にあれば巨大なネットワークでも学習できます)

目的関数の設計については古典的な普通の表現を古典的な距離とGANでの距離のハイブリッドになっていて、古典距離はブラー(画像のボケ)を防ぐ効果が期待できます
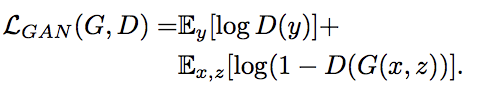
GANの距離と
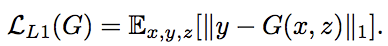
古典的な距離を
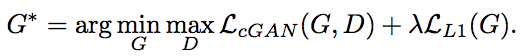
くっつけます
End2Endでラベルを用いるような学習をかなり色々試行錯誤しましたが、もう限界に達しているとも思い、これからは、学習自体に何らか意味あるような学習が優位になっていく用に思います。
requirements
- Python3 with numpy
- cuda
- pytorch
- torchvision
Getting Started
git clone
$ git clone https://github.com/GINK03/pytorch-pix2pix $ cd pix2pix-pytorch
train dataset
$ python3 train.py --dataset facades --nEpochs 100 --cuda
train dataset
$ python3 test.py --dataset facades --model checkpoint/facades/netG_model_epoch_200.pth --cuda
Examples
白黒写真に色を付ける
夏+花のデータセットを用いて、学習します Download
$ wget https://www.dropbox.com/s/yhstjhqmsy1cneb/grayscale.zip $ mv grayscale.zip dataset $ cd dataset $ unzip grayscale.zip
train dataset
$ python3 train.py --dataset grayscale --nEpochs 100 --cuda
predict dataset
$ python3 test.py --dataset grayscale --model checkpoint/grayscale/netG_model_epoch_100.pth --cuda
example output

ノイズや欠落情報を復元する
"自然"のデータセットに対して、ノイズを乗せて復元を試みます Download
$ wget https://www.dropbox.com/s/1yvr560s24sliay/random_drop.zip $ mv random_drop.zip dataset $ cd dataset $ unzip random_drop.zip
train dataset
$ python3 train.py --dataset random_drop --nEpochs 50 --cuda
predict dataset
$ python3 test.py --dataset random_drop --model checkpoint/random_drop/netG_model_epoch_50.pth --cuda
example output

フォントのスタイルの変換を行う
人間が習字で書いたデータセットに対して、Takao Fontと対応させて、新規フォントを作るという発想です
Download
$ wget https://www.dropbox.com/s/owee6hxopnr4dpo/font.zip $ mv font.zip dataset $ cd dataset $ unzip font.zip
train dataset
$ python3 train.py --dataset font --nEpochs 150 --cuda
predict dataset
$ python3 test.py --dataset font --model checkpoint/font/netG_model_epoch_150.pth --cuda
example output

コード
ご自由にご利用ください