実践的な分散処理を利用して処理を高速化
実践的な分散処理を利用して処理を高速化
GCPやAWSで膨大な計算を行う際に、オーバーヘッドを見極めて、大量のインスタンスを利用し、半自動化して、より効率的に運用するテクニックです。
Kaggle Google Landmark Recognition + Retrievalで必要となったテク
Kaggleでチームを組んで皆さんのノウハウと勢いを学ぶべく、KaggleのGoogle Landmark RecognitionとRetrievalのコンペティションにそれぞれチームで、参加しました。
メンツは、キャッシュさん、yu4uさん、私という激強のお二人に私が計算リソースの最適化で参加しました。画像のことはディープ以降の知識レベルであったので、大変勉強になったコンペです。結果は銀メダル2個です。
「ディープの特徴量」 + 「局所特徴量」の両方を取り出し、マッチングを計算するという問題で、これが大量の画像に対して適応しようとすると、とても重いものでした。
これを様々な計算リソースを投入し、並列で計算した方法がかなり極まっていたのと、これは知らないと難しいかも、、、と思い、よい機会なのでまとめました。
大量のクラウドの一時的なインスタンスをかりて、SSHFSというファイルシステムで一つのマシンをマウントし、各インスタンスに処理の命令を送り、オーバーヘッドを見極めて、アルゴリズム的改善を行い、改善した処理プロセスを行う、というPDCAのような流れをおこうなのですが、各要素について説明したいと思います。
目次
- ファイルシステム
- GCP Preemtipbleインスタンスを用いた効率的なスケールアウト
- MacBookからGCPのインスタンスに命令を送る
- Overheadを見極める
- Forkコスト最小化とメモ化
- まとめ
1. ファイルシステム:SSHFSがファイルの破損が少なくて便利
sshfsはssh経由で、ファイルシステムをマウントする仕組みですが、安定性が、他のリモート経由のファイルシステムに対して高く、一つのハードディスクに対して、sshfs経由で多くのマシンからマウントしても、問題が比較的軽微です。
また、ホストから簡単に進捗状況をチェックすこともできます。
この構造のメリットは、横展開するマシンの台数に応じて早くできることと、コードを追加で編集することなく、分散処理できます。
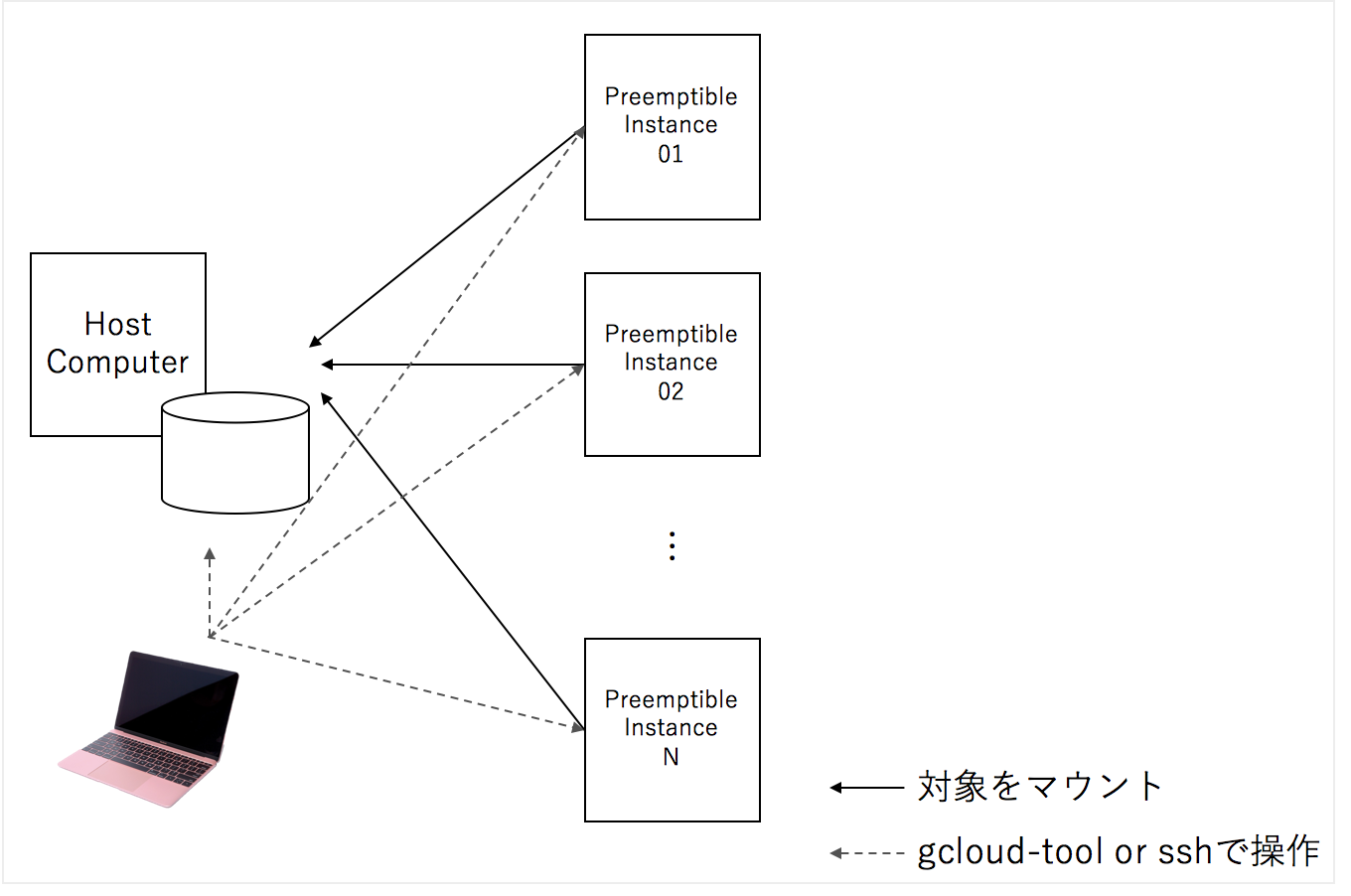
図1.
処理粒度を決定して、処理したデータはなにかキーとなる値か、なければ処理したデータのhash値でファイルが処理済みかどうかを判断することで、効率的に分散処理することtができます。
sshfs上の処理粒度に対してすでに、処理済みであれば、処理をスキップします。
(sshfs上で行ったものは二度目はファイルが共有され、二度目は、処理されないので、効率的に処理できます)
from pathlib import Path import random from concurrent.futures import ProcessPoolExecutor as PPE def deal(path): target = Path( f'target_dir/' + str(path).split('/').pop() ) if target.exists(): # do nothing return # do some heavy process target.open('w').write( 'some_heavy_output' ) paths = [path for path in Path('source_dir/').glob('*')] random.shuffle(paths) # shuffle with PPE(max_workers=64) as exe: exe.map(deal, paths)
2. GCP Preemptible Instance(AWSのSpot Instance)を用いた効率的なスケールアウト
計算ノードは、非同期で運用できるので、途中で唐突にシャットダウンされても問題がないです。そのため、安いけどクラウド運営側の都合でシャットダウンされてしまう可能性があるが、1/10~1/5の値段程度に収まるGCP PreemptibleインスタンスやAWS Spotインスタンスを用いることができます。
Preemptibleインスタンスはgcloudコマンドで一括で作成できますが、このようにPythonなどのスクリプトでラップしておくとまとめて作成できて便利です。
Preemptible インスタンスをまとめて作成
import os type = 'n1-highcpu-64' image = 'nardtree-jupyter-1' for i in range(0, 3): name = f'adhoc-preemptible-{i:03d}' ctx = f'gcloud compute instances create {name} --machine-type {type} --image {image} --preemptible' os.system(ctx)
このスクリプトは、自分で作成した必要なライブラリがインストールされた状態のイメージ(nardtree-jupyter-1)からハイパフォーマンスのインスタンスを3台作成します。
3. MacBookからGCPのインスタンスに命令を送る
google cloud toolをインストールし設定することで、GCPのインスタンスに対して命令(コマンド)を送ることができます
Premptible インスタンスに必要なソフトをインストールして、sshfs経由でマウント
クライアントマシン(手元のMacBookなど)から、コマンドを実行させることができます。
このオペレーションのなかに、手元のマシンから任意の前処理,学習のスクリプトを実行することもできます。
(GCP_NAME, GCP_KEY_NAMEは手元のパソコンの環境変数に設定しておくとよいです)
import os GCP_NAME = os.environ['GCP_NAME'] GCP_KEY_NAME = os.environ['GCP_KEY_NAME'] names = [f'adhoc-preemptible-{i:03d}' for i in range(0, 3)] # commandsのところに任意の処理を書くことができます commands = [ 'sudo apt update', \ 'sudo apt-get install sshfs', \ 'mkdir machine', \ f'sshfs 35.200.39.32:/home/{GCP_NAME} /home/{GCP_NAME}/machine -o IdentityFile=/home/{GCP_NAME}/.ssh/{GCP_KEY_NAME} -o StrictHostKeyChecking=no' ] for name in names: for command in commands: base = f'gcloud compute ssh {GCP_NAME}@{name} --command "{command}"' os.system(base)
4. Overheadを見極める
高速化の余地があるプログラムの最適化はどうされていますでしょうか
私は、以下のプロセスで全体のプロセスを最適化しています。


図2.
図2の例では、CPUは空いており、コードとこの観測結果から、DISKのアクセスが間に合ってないと分かります。オンメモリで読み込むことや、よりアクセスの速いDISKを利用することが検討されます。
5. Forkコスト最小化とメモ化
マルチプロセッシングによるリソースの最大利用は便利な方法ですが、spawn, fork, forkserverの方法が提供されています。
使っていて最もコスト安なのはforkなのですが、これでうまく動作しないことが稀にあって、spawnやforkserverに切り替えて用いることがあります。spawnが一番重いです。
forkでは親プロセスのメモリ内容をコピーしてしまうので、大きなデータを並列処理しようとすると、丸ごとコピーコストがかかり、小さい処理を行うためだけにメモリがいくら高速と言えど、細かく行いすぎるのは、かなりのコストになるので、バッチ的に処理する内容をある程度固めて行うべきです。 cent

例えば、次のランダムな値を100万回、二乗するのをマルチプロセスで行うと、おおよそ、30秒かかります。
from concurrent.futures import ProcessPoolExecutor as PPE import time import random args = [random.randint(0, 1_000) for i in range(100_000)] def normal(i): ans = i*i return ans start = time.time() with PPE(max_workers=16) as exe: exe.map(normal, args) print(f'elapsed time {time.time() - start}')
$ python3 batch.py elapsed time 32.37867593765259
では、単純にある程度、データをチャンクしてマルチプロセスにします。
すると、0.04秒程度になり、ほぼ一瞬で処理が完了します
これはおおよそ、もとの速度の800倍です
from concurrent.futures import ProcessPoolExecutor as PPE import time import random data = [random.randint(0, 1_000) for i in range(100_000)] tmp = {} for index, rint in enumerate(data): key = index%16 if tmp.get(key) is None: tmp[key] = [] tmp[key].append( rint ) args = [ rints for key, rints in tmp.items() ] def batch(rints): return [rint*rint for rint in rints ] start = time.time() with PPE(max_workers=16) as exe: exe.map(batch, args) print(f'elapsed time {time.time() - start}')
$ python3 batch2.py elapsed time 0.035398244857788086
メモ化、キャッシュを利用する
同じ内容が出現し、結果を保存できる場合、計算の多くを共通で占める箇所を、特定のキーで保存しておいて、再利用することで、高速に処理することができます。
特定の入力の値を10乗して、返すというあまりない問題ですが、わかりやすいので、これで示すと、チャンクして処理するものが、このコードになり、4秒程度かかります。
import time import random import functools data = [random.randint(0, 1_000) for i in range(10_000_000)] tmp = {} for index, rint in enumerate(data): key = index%16 if tmp.get(key) is None: tmp[key] = [] tmp[key].append( rint ) args = [ rints for key, rints in tmp.items() ] def batch(rints): return [functools.reduce(lambda y,x:y*x, [rint for i in range(10)]) for rint in rints ] start = time.time() with PPE(max_workers=16) as exe: exe.map(batch, args) print(f'elapsed time {time.time() - start}')
$ python3 batch2.py elapsed time 3.9257876873016357
これをメモ化して、ある程度の最適化を入れると、倍以上の速度になります
from concurrent.futures import ProcessPoolExecutor as PPE import time import random import itertools data = [random.randint(0, 1_000) for i in range(10_000_000)] tmp = {} for index, rint in enumerate(data): key = index%16 if tmp.get(key) is None: tmp[key] = [] tmp[key].append( rint ) args = [ rints for key, rints in tmp.items() ] def batch(rints): mem = {} result = [] for rint in rints: if mem.get(rint) is None: mem[rint] = itertools.reduce(lambda y,x:y*x, [rint for i in range(10)] ) result.append( mem[rint] ) return result start = time.time() with PPE(max_workers=16) as exe: exe.map(batch, args) print(f'elapsed time {time.time() - start}')
$ python3 batch3.py elapsed time 1.4659481048583984
5.5 コード
6. まとめ
並列処理はMapReduceという分析スタイル以外のものもたくさん存在し、微妙な勘所の最適化がないとそもそも目的に対して間に合わないということも十分にありえます。
sshfsを共通のファイルシステムとして持ち、Preemptibleインスタンスをたくさん用意して、 gcloudで任意のコマンドを送信することで、一つの問題を膨大な計算リソースで処理することができるようになります。
計算量での押し切りは、最後に粘りがちになるえる技能でもあるので、そこそこ重要なのだと思います。
Kaggleを取り掛かるまでにやったこととと、モチベーションの維持のために必要だったこと
Kaggleを取り掛かるまでにやったこととと、モチベーションの維持のために必要だったこと
わたしの経験した、最初のKaggleの一歩と、実際にKaggleに対するモチベーションがそれなりに加熱するまでにやったことと、息切れしない心の持ち方です。
KaggleがDataScienceに携わるものの価値の可視化の基軸の一つになっていますが、まだ取り掛かれない or 心が折れそう人のために、私に必要だったきっかけと、私が行ったモチベーションコントロールを含めて記します。
まだまだkaggleは弱いですが、継続的に、日々の生活の中に組み入れるまでが大変でした。
目次
既存の機械学習関連の技術者にとってのKaggleの認識のあり方
競技プログラミングは業務コーディングで役に立たないロジックが、Kaggleの業務のデータ分析との関係にも成り立つか
挑み方(ブートアップ)
挑み方(Kernelにキャッチアップし続ける)
挑み方(ツール類)
挑み方(データ構造)
挑み方(魂のあり様)
人間性を捧げよ
1. 既存の機械学習関連の技術者にとってのKaggleの認識のあり方
私が面接する側に立ったこともそれなりにあるし、面接される立場になったこともそれなりにありますが、DSに関わる人のスキルや技能は面接で完全に納得行くまで把握し切ることが、かなり困難だと感じていて、一つの客観的な指標にKaggleが強いことなどのアウトプットが重要視されることがあります。
今までそれなりにやってきたという技術者や企業の意思決定をデータ的な側面で支えてきたデータサイエンティストたちも、過去の実績の資産だけでなく、現実に何ができるかということを、積極的に可視化することが求められている流れをひしひしと感じています。
忙しいから & 自信がないからやらないという言い訳がもはや通用しない所まで来ています。
2. すでに機械学習アルゴリズム(本人の主観で十全に)を知っているがやるべきか
やるべきです。理屈や概要を知っているだけでは、使いこなせないということを嫌というほど体感できるかと思います。
また、競技に向いたデータ分析手段もあり、スピード的、精度的に、高効率なものが多く、短期集中でアウトプットを出す良い訓練にもなるでしょう。
「自分は業績を示す論文があるから」や、「マイペースでやりたい」という人も多いのは承知なのですが、Kaggle的な方法もDSの一側面です。
言い訳している暇があればやったほうがいいように思われます。
3. 競技プログラミングは業務コーディングで役に立たないロジックが、Kaggleの業務のデータ分析との関係にも成り立つか
これも度々、ツイッターやいろんなメディアで話題になる類のお話ですが、競技プログラミングのデータ構造はデータ分析に使えますし、データ分析の構造を体系的に理解させてくれるコンテンツも見たことがないので、私自身は競技プログラミング、コードパズルは一定の意味があったと考えています。
しかし、SIでの開発ではこれらの技能よりわかりやすいオブジェクトを作るとか、ライブラリを綺麗に使うなどの側面で凝ったアルゴリズム的な側面でなく別の技能の側面が求めらます。チームでウォーターフォール開発の中で一人だけ生産性マックスであっても浮いてしまうでしょう。
Kaggleの側面にもそれと似たような問題はあると思います。組織のスタイルによって受け入れられるとか、そうでもないとか。
分析イディオムみたいなものはたくさん身につくので、イディオムで勝負できる案件に昇華できるかが、一つキーポイントな気がします。
4. 挑み方(ブートアップ)
まず、最初に取り掛かるのに、一人でやろうとすると、荷が重いので、だれかを巻き込みましょう。
だれかがやってるとモチベーションがし易いと感じるし、細かいインターフェースの英語で詰まったりしても、聞けば解決するかも知れないというのは案外馬鹿にできない要素であったりします。
Kaggleの課題とは本来なんの関係もないのですが、余計なところにエネルギーをかけないで済むとなると、人間、かなり進捗します。
ネットの世界ではSNSという便利ツールがあります。このツールを利用して、情報を広く集めるのも有力な手段です。
もし御社で、誰かがKaggleをやりたいと騒ぎ出したら、白い目で見るとか、馬鹿にするとかしないで、興味がなくても見守ってあげましょう。
物事を始めるのに必要なエネルギーがそれなりに必要です。彼ら彼女らなりに工夫して、初速を出そうとしているのだと思います。
5. 挑み方(Kernelにキャッチアップし続ける)
KernelというKaggle上で動作するJupyter Notebookがあるのですが、コンペティションが開始されると、いろんな人がKernelを投稿し、精度の良い例を示します。
競技としてのその性格により、コンペ終了間際で、投稿数が増えていき、かつ、精度自体も上がっていきます。
通常のKernelの進歩を考えない、初期だけ参照する例だとこのようにすればある程度の進捗を得ることができます。

図1. Kernelの進歩を考えない進捗モデル
最初の一月ぐらいは私は以下のような戦い方にしてしまって、過剰に消耗してしまいました。
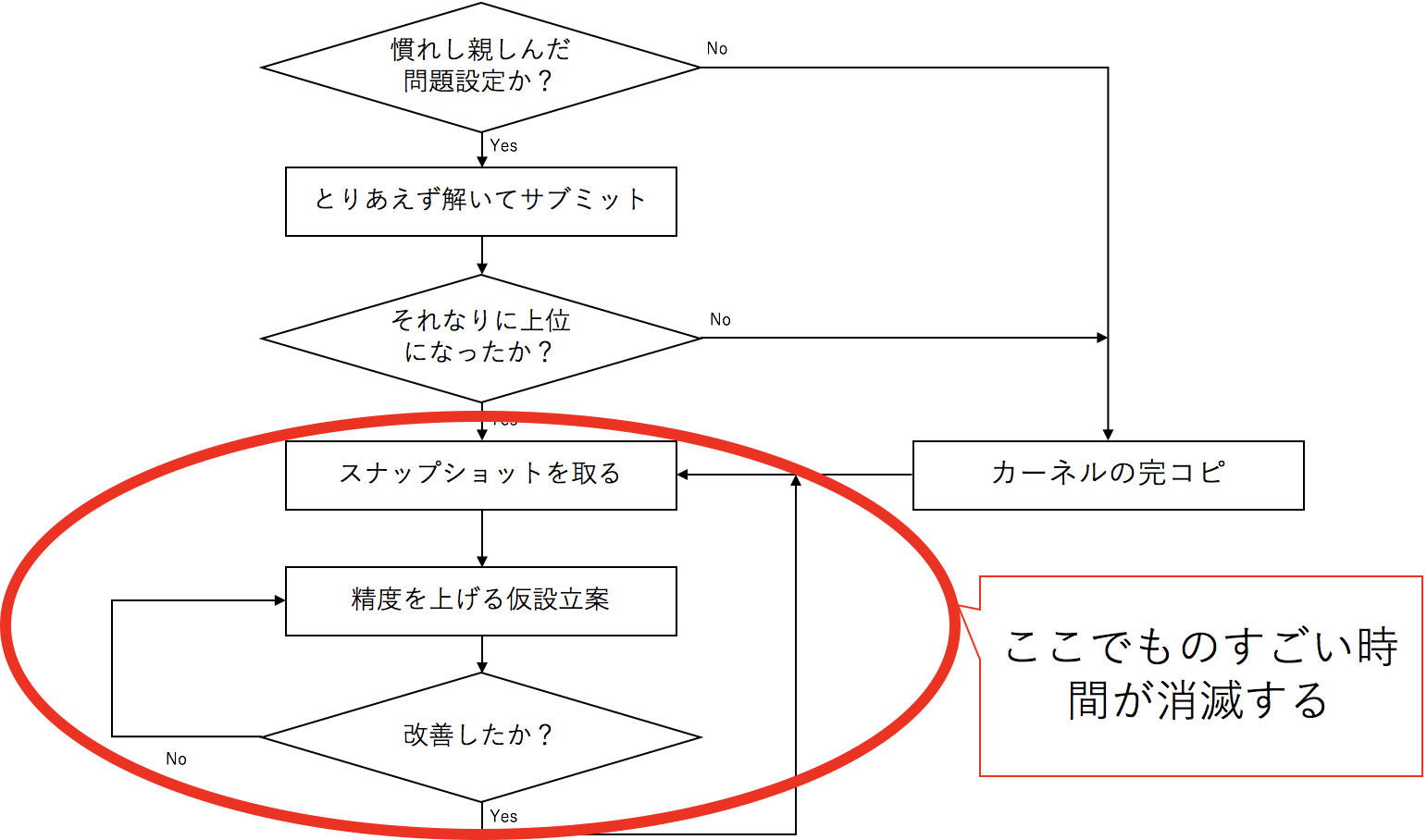
図2. 赤で囲まれたイタレーションを回しているうちに、コンペが終了してしまう
効率の悪い局所ループにハマった状態なので、なんとか、脱出しないといけません。
強化学習の知恵ですが、たまに、乱択を入れることで、ダイバーシティを維持することがあります。そんなこんなで、意識的にこのような経路に変更しました。 (α, βはコンペによって設定される 0 ~ 1の値)

図3. 例えば、外部のリソース参照の経路を確率的につくる
適切に外部の知恵を取り入れることで、進捗が出しやすく、煮詰まるということがなくなるのですが、今までの自分のリズムで進捗していくというスタイルを変更する必要があるので、ここでコストがかかります。
6. 挑み方(ツール類)
PythonかRのどちらを使うかまずは決めましょう。
Pythonでは、データ操作にPandasとNumpyが圧倒的に使われます。
以下のライブラリとソフトウェアをよく見ます
- Python3
- Pandas
- Numpy
- ScikitLearn
- lightgbm
- xgboost
- keras
また、データ量の多いコンペティションもたくさん出題されていて、普通に全量を扱おうとすると、BigQueryなどのSQLが使えるビッグデータ処理基板が必要になります。
MapReduce系のアーキテクチャとは、後述するデータ構造の関係で、行志向と列志向だと、Kernelが列志向のイメージと処理フローなので、行志向のMapReduceとはあまり相性がよくありません(Kaggle TalkinData Detectionでこれで大いに爆死しました。。)
Kernelに登場しない処理方法 - BigQuery
7. 挑み方(データ構造)
Pandasのデータ構造が列志向という方法を採用しており、この方法を理解していると、便利です。
列志向は、分散処理に向かないという側面がありますが、なんだかんだで直感的にデータを操作できて便利です。
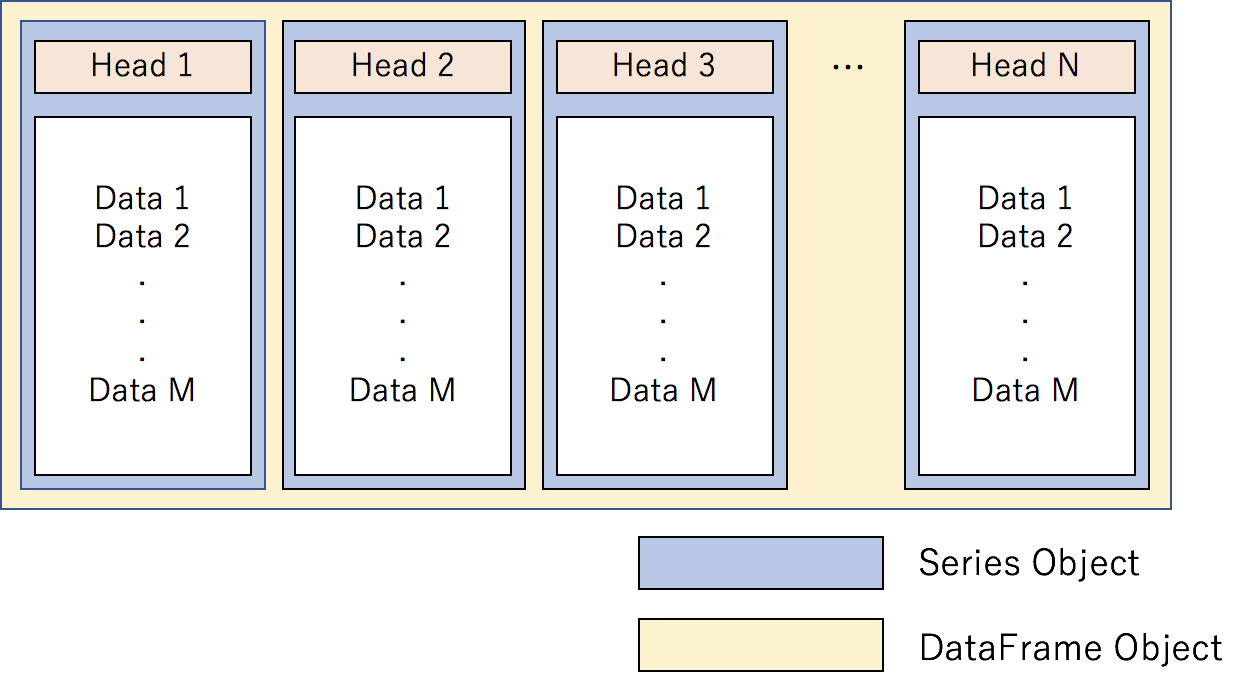
図4. PandasのDataFrameはSeriesのオブジェクトを束ねた列志向になっています
列志向は、Pandas作者のWes McKinnyがよく使う方法で、Apache Arrowなどの処理基板方式を横断したDataFrameを推進していらっしゃいます。
なんらかのKeyを必要としない処理方式なので、Map ReduceなどKeyをハッシングして、大規模分散する発想とは違ったものです。
幾つかプリミティブな動作を示します。これらの組み合わせて殆どのデータマニピュレーションが可能になります。
KaggleのOpenDataのDonorsChoose.orgのドナーのデータセットの例で示します。

図5. KaggleのDonorDataset
pandasのDataFrameをcolumn名をListで投入して、スライシングすると、DataFrame Objectが帰ります
dfslice = df[ ['Donor ID', 'Donor City'] ] # カラム名 Donor ID, Donor Cityでスライスする(スライスされたDataFrameが帰る) isinstance(dfslice, pd.DataFrame) >> True
今度はDataFrameをcolumnをstrで指定して、スライシングすると、Series Objectが帰ります
donor_series = df[ 'Donor ID' ] # カラム名 Donor IDのSeriesが帰る isinstance(donor_series, pd.Series) >> True
Seriesに対する操作は、変換関数を定義して、変換することができます。
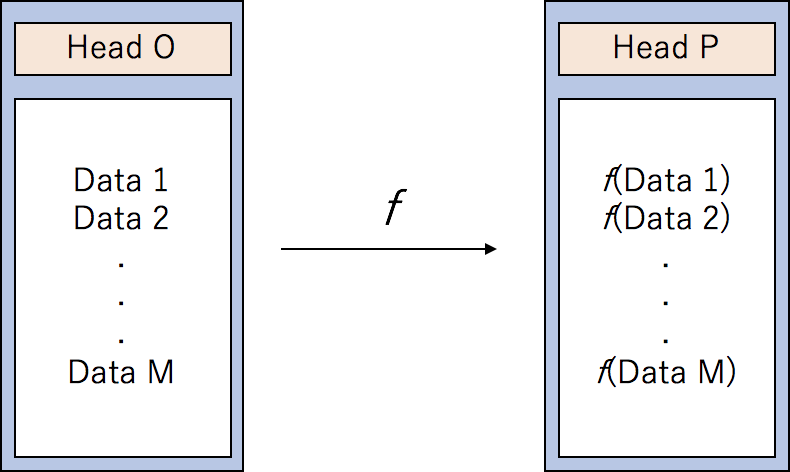
図6.
ZIP Codeをintに変換でき、かつ、偶数なら2倍し、奇数ならばそのままで、文字列ならば、-1にする例です。
def f(x): try: x = int(x) if x%2 == 0: return x*2 else: return x except Exception as ex: return -1 df['Donor Zip'] = df['Donor Zip'].fillna(0) df['Donor Zip'] = df['Donor Zip'].apply(lambda x:f(x)) df.head()
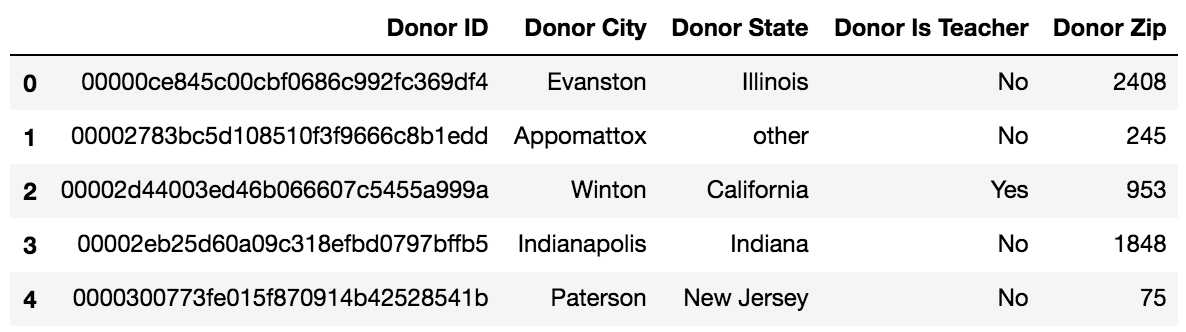
図7. 変換後のデータフレーム
Pandasドキュメントが不足しているのが、groupbyです。groupbyは特定のキーで小さなデータフレームに分割して、共通のキーの中で様々なオペレーションができます。
gp = dfslice.groupby('Donor City') isinstance(gp, pd.core.groupby.DataFrameGroupBy) # パッケージの名前空間からしてわかりにくい... >> True

図8. 設定したキーで小さいDataFrameで分割されてGroupByで更にまとめている
Pandasのgroupbyを利用して、indexで分散して、小さいDataFrameを作成して、multiprocessingを行うこともできます。
import concurrent.futures df['index'] = df.index df['distribute'] = df['index'].apply(lambda x: x%16) dfs = [ _df for key, _df in df.groupby('distribute') ] def pmap(df): # do something. pass with concurrent.futures.ProcessPoolExecutor(max_workers=16) as exe: exe.map(pmap, dfs)
8. 挑み方(魂のあり様)
多少なりとも機械学習に自己のアイデンティティを置いている人は、得意分野以外のフィールドで評価されるリスクを避けようとする心理が働くかと思います。
ここで、少し落ち着いて見ましょう。そのように評価されてあなた自身の価値は毀損しますか? 周りの人をイメージすると良いです。
少なくとも、新しいことにチャレンジしてうまくいかないことが原因で見下されるような場合、その組織は新しい必要な投機を認める文化が醸造されていません。そのような文化体系が支配的であれば、私はその組織に在籍する必要がないように思います。
また、必ず成功しようという意気込みからか、勝利を確実にするためにリソースを投下し続けるの問題でして、人間、できることには限界があり、生活のQoLが下がらないように調整する必要があります。
自己のプライドや主観的な価値の軸を、メタ的な認知である程度自由に動かせることが、必要になってきます。
メタ認知の一種を行うと良いでしょう。
9. 人間性を捧げよ
最近流行り(一部界隈だけ?)の「人間性を捧げよ」について、個人の意見の感想を述べさせてください。
私は「ダークソウル」と「ダークソウル3」のゲームが好きで、人間性という曖昧なもの(実態は何かわからない)が、この物語でキーになっています。

図9. ダークソウルでの人間性。謎の影で、アイテムであり、人間らしさ(正気度のようなパラメータでもある)
「人間性を捧げよ」は、ダークソウル1のキャッチフレーズで、ものすごい難しいゲームなのですが、ボス戦で、体力の削り合いみたいな事になってしまします。
まともにプレイしていると死にまくって、攻略ができないのですが、「人間性」というアイテムを消耗すると、HPが全回復して、ボスと殴り合いを継続できて、人間性でゴリ押しすることも可能です。
この人間性はゲーム中で限られた個数しか取得することができなくて、人間性を消耗すると、ストーリーをすすめることができなくなって、実質上、積んでしまいます。
C++を勉強してたときはものすごい勉強をして覚えたのですが、まさしく、人間性を捧げて、通常の安定した生活を遺棄して、効率のために、様々な最適化を行う努力をしました。
強い人が言う、「人間性を捧げてください」は、まさしくこのようなことだと思います。
やりすぎると病気になったり、精神がおかしくなり、人生というゲームが積んでしまうので、人間性を消費するタイミングはよく考えてください。
AWS SagemakerでJupyterを使ったり、独自機能を使う
AWS SagemakerでJupyterを使ったり、独自機能を使う
AWS SagemakerでのJupyterの使用例と、工夫すべき点を示します
また、JupyterのPythonに内蔵されているsagemakerで他のコンテナサービスと連携して、SageMakerにユニークな機能であるRandom Cut Forestによる異常検知の使用例を示します。
個人でデータサイエンスコンペとかやるのにJupyterをさくっと立てて使いたいニーズがあるのと、会社でのセキュリティを担保した環境でのJupyterを利用できるユースケースを想定して、GW中に自分の個人契約のAWSで一通りのサーベイを行いました。
目次
- AWS sagemakerとは
- anacondaにモジュールを追加する
- SageMakerのOSとusernameとpermission
- インスタンスのスケール調整
- ディスクの制限をEFSで回避する
- セキュリティグループの扱い
- ディスクの制限をS3で回避する
- Random Cut Forestの異常値検知アルゴリズム
- 論文
- アルゴリズム概要
- タクシーの乗車数の異常検知
- 想定されるユースケース
AWS sagemakerとは
EC2インスタンス等を立てることなく、JupyterNotebookやTensorFlowやSpark等を扱うことができます。
もう一つの機能として、モデルの作成と予想などの重い操作のとき、専用に、ハイパワーのコンテナを確保して行うことでリソースを必要分を動的に確保して学習する機能が備わっています(この延長線上にデプロイメントの作業も置くことができます)。
図1. SageMakerのサービスに入る

図2. JupyterNotebookのインスタンス作成&起動
図3. フルサイズのJupyterが立ち上がります

図4. 対応しているカーネルはSpark各種と、mxnet, tensorflow, anaconda
anacondaにモジュールを追加する
Jupyterはユーザ権限で動作しているので、Jupyterの中から直接、モジュールをインストールできます
%%sh conda install -c conda-forge lightgbm
import lightgbm as lgb # OK!
SageMakerのOSとusernameとpermission
JupyterNotebookなので、terminalが使えます。
Linuxの種類とversionは2018/5時点でこのようになっています。
sh-4.2$ less /etc/system-release Amazon Linux AMI release 2017.09
usernameは以下の通りでsudoする権限が与えられています
sh-4.2$ whoami ec2-user
インスタンスのスケール調整

図5. インスタンスを停止して、編集をクリックします

図6. インスタンスのサイズを変更できます
ディスクの制限をEFSで回避する
AWS SageMakerは5GByteの容量制限があるために、大規模なデータを扱う際には外部ディスクとの接続が必要になります。
オフィシャルサイトでもその手法は紹介されていますが、EFSというネットワーク経由のディスクをマウントする際に気をつけるべき点があります。
- EFSとSageMakerのセキュリティグループは同じである
これを気づかずに数時間とかしました。。。
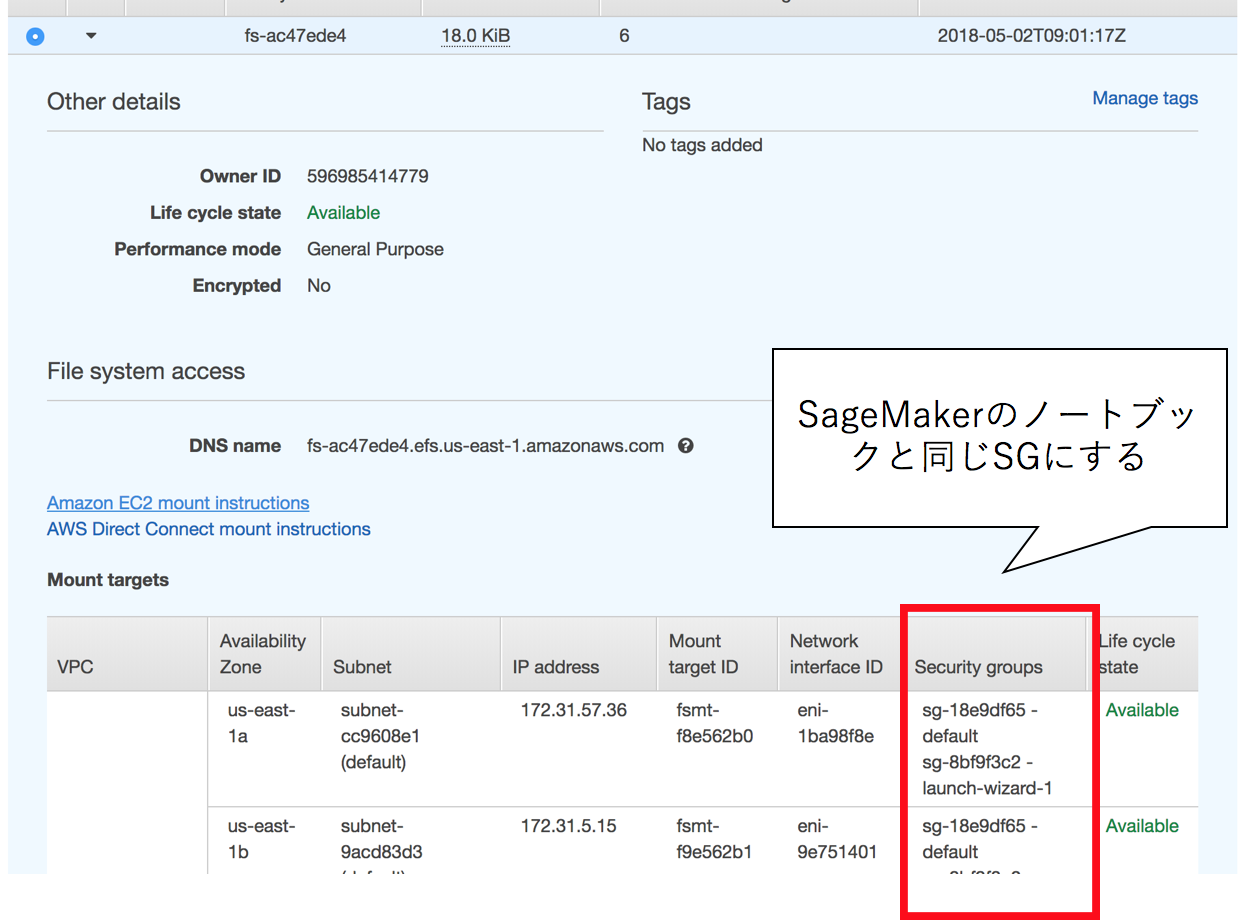
図7. EFSのセキュリティグループをSageMakerのインタンスのものと同じにしておきます
SageMakerも一旦インスタンスを作成してしまうと、セキュリティグループ等を変更できないので、要注意です。
Jupyterでshを有効にするか、terminalに入って、以下のコマンドでEFSをマウントできます。
$ cd SageMaker
$ mkdir efs
$ sudo mount -t nfs4 -o nfsvers=4.1,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2 ${MOUNT_TARGET_IP}:/ efs
$ sudo chown -R uc2-user efs
複数のインスタンスでアクセスでき、後述するS3をマウントするアプローチよりだいぶ速度的にマシだったりして、選択としてありだと思います。
ディスクの制限をS3で回避する
マウントするにはgoofysというgoでS3を透過的にマウントする仕組みが便利です。
Linux用のバイナリがすでにコンパイルされて公開されているので、それを利用します。
goofysのバイナリを設置して、credencialsを設定します
$ cd SageMaker
$ mkdir bin
$ cd bin
$ wget http://bit.ly/goofys-latest
$ chmod +x goofys-latest
$ cat ~/.aws/credencials
[default]
aws_access_key_id = ${AKID1234567890}
aws_secret_access_key = ${MY-SECRET-KEY}
必要なバイナリ、fusermountが含まれていないので、別途インストールします
$ sudo yum install fuse
マウントします
$ /bin/goofys-latest gk-sagemaker-test-01 s3
これでs3で作業するには容量制限を受けませんし、お安いのですが、遅いので、コスパ重視の設定になります
Random Cut Forestの異常値検知アルゴリズム
AWS SageMakerの売りとしてAWSのハイパワー仮想化コンテナを利用することで、JupyterNotebookが動作しているコンテナでなくても、高速に学習・予想することが可能なようです。
Random Cut Forestというあまり名前を聞かない異常検知アルゴリズムです。
ノンパラメトリックの異常値検知アルゴリズムで使い勝手は良さそうです。
論文
論文自体は2016年に発表されたもので比較的新しめです。
AWS whitepaperの中に紛れて公開されており、誰でも参照できます。
アルゴリズム概要
論文(というなのwhite paper)をよんでいった感想なのですが、やろうとしていることとしては、決定木系のアルゴリズムで、異常値を含むと、 なんらかモデルが複雑になるという発想から来ているようです。
つまり、正常な状態より、異常な状態は予想が困難で複雑であるということから、その複雑度を見ていくことで異常度を定義しようという発想に見えました。
図8. 決定木の複雑度を減らす操作

式1. 簡略化したモデルから複雑なモデルとの誤差をもとに評価を決定
お気持ちとしてはモデルの複雑度(この場合は決定木の深さ)が、しきい値を超えたら、何らかの異常値があるとみなす、という流れです。
各系列で、様々に複雑度を見ていって、これをscoreとして、scoreの平均値と標準偏差の和などをしきい値として、しきい値が偏差を超えたら異常値と定義するなどで使えます。
タクシーの乗車数の異常検知
ニューヨークの日々のタクシーの利用者数をtime seriesで格納されたデータを用いて、異常値検知を行っていますが、2018/05/01に投稿されたはずなのポストですが、動作しませんでした。
追試したところ、以下のようにコードを変更する必要がありました。
変更前
rcf.set_hyperparameters(
num_samples_per_tree=200,
num_trees=50,
feature_size=1)
変更後
rcf.set_hyperparameters(
num_samples_per_tree=200,
num_trees=50,
feature_size=1)
一通り実行した内容のjupyterがあるので、必要に応じて参照してください
感想としては、これは、パラメータ調整次第で、prophetで扱えない高次元の入力となる系列情報も対応かのうそうで、問題によっては使う意義がありそうです。
想定されるユースケース
インスタンスを建てないでJupyterで分析, MLする。
AWSと密に運用されたサービスでモデルの学習とデプロイを行う
SageMakerのモジュールのIF自体が微妙にわかりにくく、学習コストがそれなりに掛かるので、必要でなければ、ScikitLearnとかでローカルで動作させてしまったほうが楽かなと思いました。
dask.distributedで分散処理
dask.distributedで分散処理
dask.distributedの使い方と、具体例集です
dask.distributedの簡単な理解
一種の分散処理フレームワークになっており、便利です。
ドキュメントやgithubはdaskからdask.distributedは分割されており、DataFrameの取扱以外のより汎用的な分散処理を含んでいるようです。
Celeryとかでもやったことをがあるのですが、dask.distributedはRemote Procedureのそれよりまともでより整理された方法で、concurrent.futureのリモート版とも考えられます。

dask.distributedのインストール
pip経由でのdaskのインストール
$ sudo pip3 install dask $ sudo pip3 install distributed
ubuntuでのインストール
注:パッケージが微妙に古くてpip経由の方がいいです
$ sudo apt install python3-distributed
Dask SchedulerとWorkerのセットアップ
Schedulerは分析を実行するマシン、クライアントマシンなど任意のマシンでいいはずです
(今回はschedulerを起動するマシンは192.168.14.13のIPアドレスを持つとしています)
$ dask-scheduler Start scheduler at 192.168.14.13:8786
portのチェック
$ nc -v -w 1 192.168.14.13 -z 8786
Workerは命令を受け実際に計算するマシンなので、別のマシンになります
${SCHEDULER}にはschedulerを起動したマシンのIPが入ります
nprocsオプションで最大のworkerでの並列数(同時に関数が走る数)を指定できます
$ dask-worker ${SCHEDULER}:8786 --nprocs 12
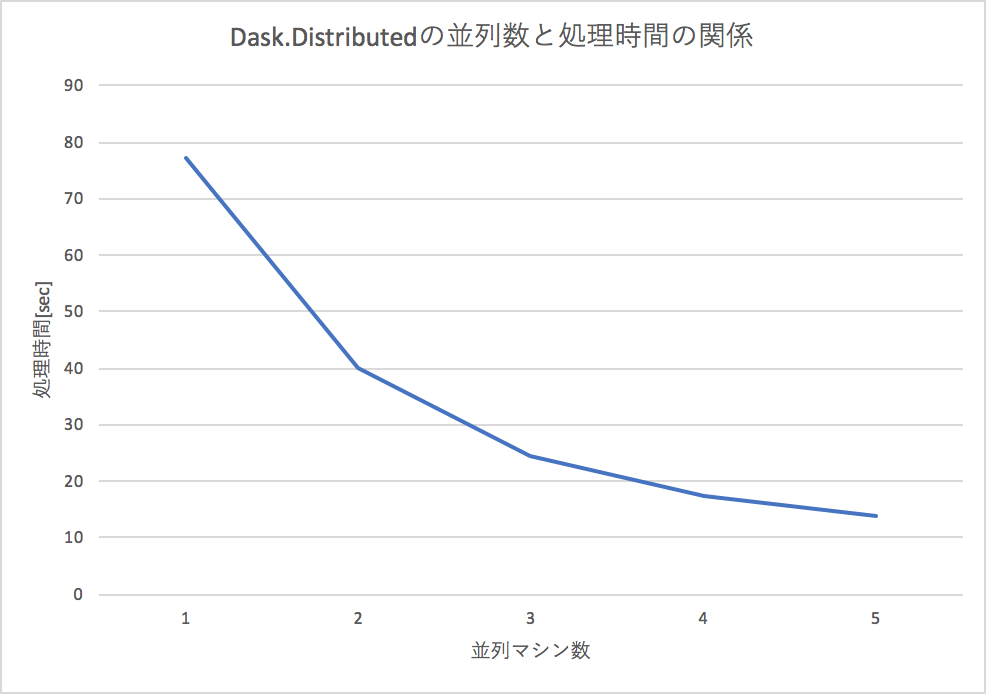
Dask.Distributedの並列マシン数と、速度の関係
下記にある簡単な足し算を並列マシン(worker数の増加)でやろうとすると、処理時間がほぼ反比例の関係で下がるので、効率的に分散処理できていることが確認できます。
分散した命令の結果を受け取る2つの方法
clientにmapされた命令はschedulerが管理して分散処理されますが、内部で、マシン台数かに分割されており、速度的には、一気に結果を見る(gather)のも、個別にみる(result)のもあまり変わりがないようです。
gatherという関数で一気に集められますが戻り値が多いときには、オンメモリにするのが難しいので、挙動が不安です。
L = client.map(inc, range(1000)) ga = client.gather(L)
resultで一個一個取っていく方法は、一件の処理結果のみ返すので、メモリ節約にはなりそうです
L = client.map(inc, args) for l in L: print(l.result())
例に用いたコード
簡単な例:数字を増やすだけ
簡単な命令で、数字を足し合わせて行くだけのプログラムですが、100回引数を変えて行おうとすると、計算時間がかかります。
今回、5台のマシンで一台あたり12並列数で行うので、合計60並列で処理します。
ClientでschedulerのIPアドレスとportを指定して、以下のようなコードを実行するだけで、複数のマシンで並列計算をすることができます。
from distributed import Client client = Client('192.168.14.13:8786') def inc(x): for i in range(10000000): x += i return x L = client.map(inc, range(1000)) ga = client.gather(L) print(ga)
複雑な例:機械学習のモデルのグリッドサーチでも便利
機械学習のパラメータを少しずつ変えながらもっとも、パフォーマンスが良いパラメータを総当りで探すグリッドサーチというものあって、マシンパワーでゴリ押ししてしまうのが都合がいいのです。
複数台のworkerでグリッドサーチさせると、そのマシンの台数分だけ減らせます
dask.mllibを使うとscikit-learnをラップして使うことができますが、任意のライブラリでも動かしたいので、特にdask.mllibは使いません
代表的なUCIのadult incomeデータセットでランダムフォレストでパラメータを2x10x10x15=3000通りという膨大なパラメータサーチであっても、割と早く終わらせることができます。
以下のコードの例では、パラメータの組み合わせを作って、分散処理で評価させています。
関数doはworkerで実行されて、ホームディレクトリ以下のデータセットを読み込んで、引数に与えられたRandomForestのパラメータを適応して学習し、テストデータでの精度を見ています。
def do(param): dataset = pickle.load(open(f'{os.environ["HOME"]}/dataset.pkl', 'rb')) Xs, ys, Xst, yst = dataset criterion, n_estimators, max_features, max_depth = param model = RandomForestClassifier(n_estimators=n_estimators, criterion=criterion, max_features=max_features, max_depth=max_depth) model.fit(Xs, ys) ysp = model.predict(Xst) acc = accuracy_score(yst, ysp) print(acc) return [acc, list(param)] params = [] for cri in ['gini', 'entropy']: for n_esti in range(5,15): for max_features in range(10,20): for max_depth in range(4, 20): params.append( (cri, n_esti, max_features, max_depth) ) L = client.map(do, params) ga = client.gather(L)
adult incomeのデータを学習可能かデータに変換
$ python3 parse-adult.py
出力されたdataset.pklを各workerのホームディレクトに配置
関数の引数に学習用のデータを含めると、遅くなったり、警告がでたりするので、大規模なデータの際はscpで転送する、S3, GCSを利用するなどが良いようです。
workerの台数で分散処理してグリッドサーチ
$ time python3 adult.py ... real 2m24.923s user 0m5.950s sys 0m0.951s
10分以上かかる処理が2分半程度に圧縮できました!
progress barの表示
client.map, client.submitをprogress関数でラップすることで、進捗を確認することができます
L = client.map(do, params) progress(L) # このようにする ga = client.gather(L)

dask.distributedで注意すべき点
dask.distributedで関数の引数に大きすぎるデータ(100MByte)を超えるものを投入すると警告が出るし、転送も早くありません。
そのため、なんらかローカルで対象となるデータを共有している必要があり、scpでファイル転送、HDFSやS3, cloudstrageなどとは相性がよい設計です。
S3とかに格納されchunkされたデータを一気に処理するときなど、便利そうです
金銭的な比較
今現在、私の個人サーバは6core 12threadのRyzen 1600Xが5台あって、30core 60threadで動作します。
2018/03現在、これはおおよそ2万円なので、10万円程度でこの仕組が購入できたことになります。
同等のスペックであるEpyc 7551pは$2100なので、おおよそ20万円で、半額程度で手に入れることができました。
もちろん、分散させないで一大のマシンで処理するメリットとかあると思うのですが、こんな大規模計算は稀だし、必要なときにdask-workerを立ち上げてクラスタに組み込めるのはメリットです。
Dask(+Dask.Distributed)の使い所
Apche Sparkと競合するような位置づけですが、Daks.Distributedのその簡単にデプロイできることと、Apache Sparkを用意するまででもないときとかよいんではないか、みたいに言われているようです。
私は、HadoopやDataFlow(Apache Beam)が結構好きで得意なので、Sparkをあんまり使わないですが、ここまで大げさに分散処理する必要が無いときにDask(+Dask.Distributed)は良さそうですね。