AWS SagemakerでJupyterを使ったり、独自機能を使う
AWS SagemakerでJupyterを使ったり、独自機能を使う
AWS SagemakerでのJupyterの使用例と、工夫すべき点を示します
また、JupyterのPythonに内蔵されているsagemakerで他のコンテナサービスと連携して、SageMakerにユニークな機能であるRandom Cut Forestによる異常検知の使用例を示します。
個人でデータサイエンスコンペとかやるのにJupyterをさくっと立てて使いたいニーズがあるのと、会社でのセキュリティを担保した環境でのJupyterを利用できるユースケースを想定して、GW中に自分の個人契約のAWSで一通りのサーベイを行いました。
目次
- AWS sagemakerとは
- anacondaにモジュールを追加する
- SageMakerのOSとusernameとpermission
- インスタンスのスケール調整
- ディスクの制限をEFSで回避する
- セキュリティグループの扱い
- ディスクの制限をS3で回避する
- Random Cut Forestの異常値検知アルゴリズム
- 論文
- アルゴリズム概要
- タクシーの乗車数の異常検知
- 想定されるユースケース
AWS sagemakerとは
EC2インスタンス等を立てることなく、JupyterNotebookやTensorFlowやSpark等を扱うことができます。
もう一つの機能として、モデルの作成と予想などの重い操作のとき、専用に、ハイパワーのコンテナを確保して行うことでリソースを必要分を動的に確保して学習する機能が備わっています(この延長線上にデプロイメントの作業も置くことができます)。
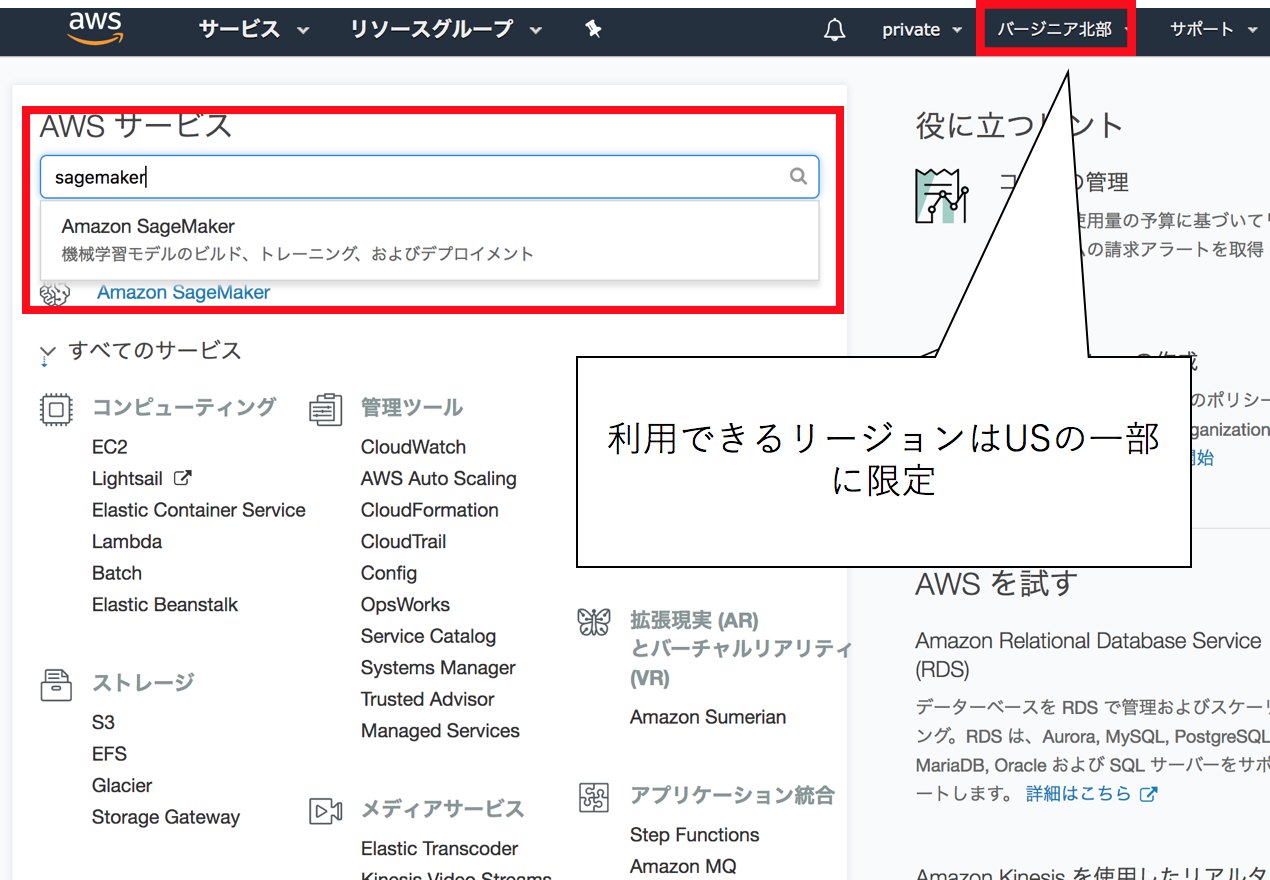
図1. SageMakerのサービスに入る

図2. JupyterNotebookのインスタンス作成&起動
図3. フルサイズのJupyterが立ち上がります

図4. 対応しているカーネルはSpark各種と、mxnet, tensorflow, anaconda
anacondaにモジュールを追加する
Jupyterはユーザ権限で動作しているので、Jupyterの中から直接、モジュールをインストールできます
%%sh conda install -c conda-forge lightgbm
import lightgbm as lgb # OK!
SageMakerのOSとusernameとpermission
JupyterNotebookなので、terminalが使えます。
Linuxの種類とversionは2018/5時点でこのようになっています。
sh-4.2$ less /etc/system-release Amazon Linux AMI release 2017.09
usernameは以下の通りでsudoする権限が与えられています
sh-4.2$ whoami ec2-user
インスタンスのスケール調整

図5. インスタンスを停止して、編集をクリックします

図6. インスタンスのサイズを変更できます
ディスクの制限をEFSで回避する
AWS SageMakerは5GByteの容量制限があるために、大規模なデータを扱う際には外部ディスクとの接続が必要になります。
オフィシャルサイトでもその手法は紹介されていますが、EFSというネットワーク経由のディスクをマウントする際に気をつけるべき点があります。
- EFSとSageMakerのセキュリティグループは同じである
これを気づかずに数時間とかしました。。。
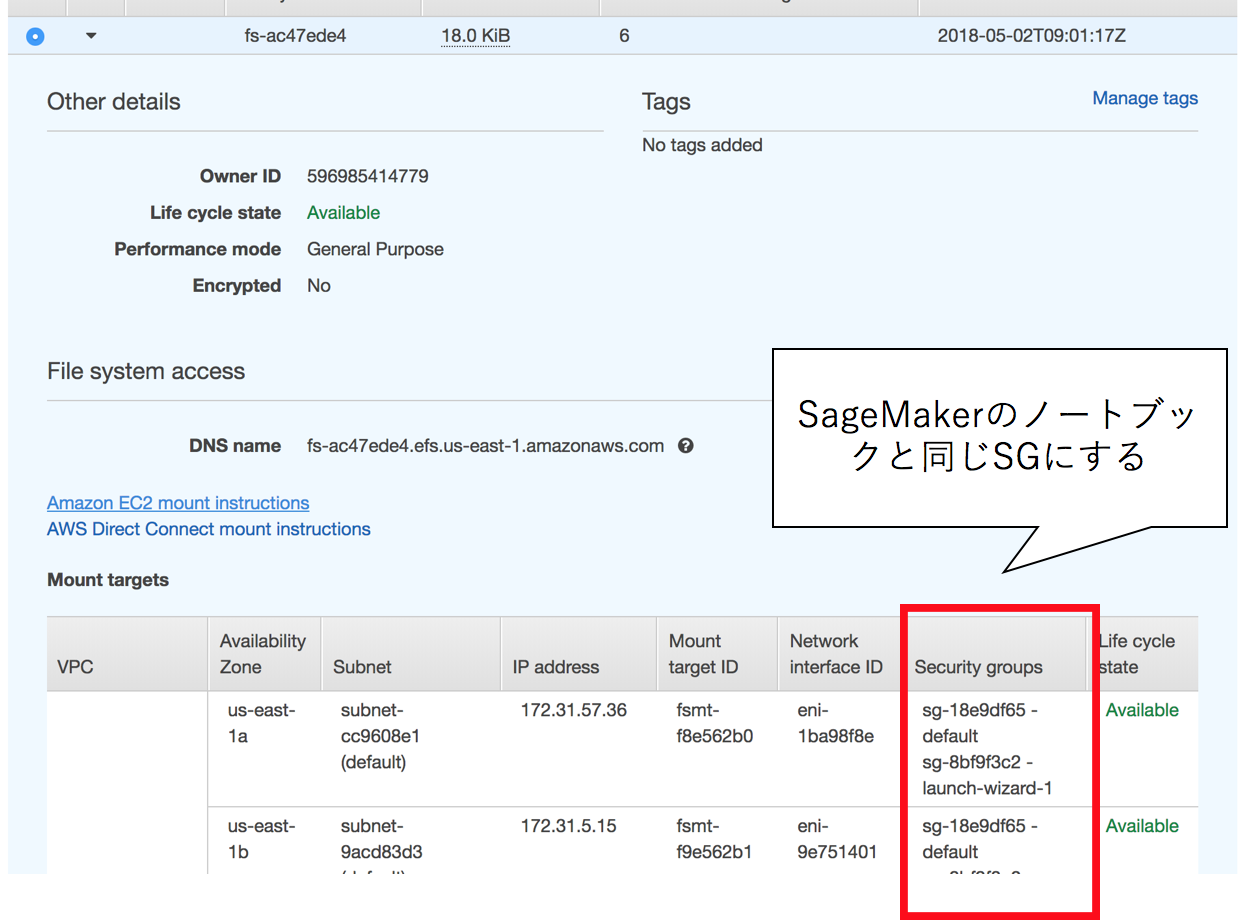
図7. EFSのセキュリティグループをSageMakerのインタンスのものと同じにしておきます
SageMakerも一旦インスタンスを作成してしまうと、セキュリティグループ等を変更できないので、要注意です。
Jupyterでshを有効にするか、terminalに入って、以下のコマンドでEFSをマウントできます。
$ cd SageMaker
$ mkdir efs
$ sudo mount -t nfs4 -o nfsvers=4.1,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2 ${MOUNT_TARGET_IP}:/ efs
$ sudo chown -R uc2-user efs
複数のインスタンスでアクセスでき、後述するS3をマウントするアプローチよりだいぶ速度的にマシだったりして、選択としてありだと思います。
ディスクの制限をS3で回避する
マウントするにはgoofysというgoでS3を透過的にマウントする仕組みが便利です。
Linux用のバイナリがすでにコンパイルされて公開されているので、それを利用します。
goofysのバイナリを設置して、credencialsを設定します
$ cd SageMaker
$ mkdir bin
$ cd bin
$ wget http://bit.ly/goofys-latest
$ chmod +x goofys-latest
$ cat ~/.aws/credencials
[default]
aws_access_key_id = ${AKID1234567890}
aws_secret_access_key = ${MY-SECRET-KEY}
必要なバイナリ、fusermountが含まれていないので、別途インストールします
$ sudo yum install fuse
マウントします
$ /bin/goofys-latest gk-sagemaker-test-01 s3
これでs3で作業するには容量制限を受けませんし、お安いのですが、遅いので、コスパ重視の設定になります
Random Cut Forestの異常値検知アルゴリズム
AWS SageMakerの売りとしてAWSのハイパワー仮想化コンテナを利用することで、JupyterNotebookが動作しているコンテナでなくても、高速に学習・予想することが可能なようです。
Random Cut Forestというあまり名前を聞かない異常検知アルゴリズムです。
ノンパラメトリックの異常値検知アルゴリズムで使い勝手は良さそうです。
論文
論文自体は2016年に発表されたもので比較的新しめです。
AWS whitepaperの中に紛れて公開されており、誰でも参照できます。
アルゴリズム概要
論文(というなのwhite paper)をよんでいった感想なのですが、やろうとしていることとしては、決定木系のアルゴリズムで、異常値を含むと、 なんらかモデルが複雑になるという発想から来ているようです。
つまり、正常な状態より、異常な状態は予想が困難で複雑であるということから、その複雑度を見ていくことで異常度を定義しようという発想に見えました。
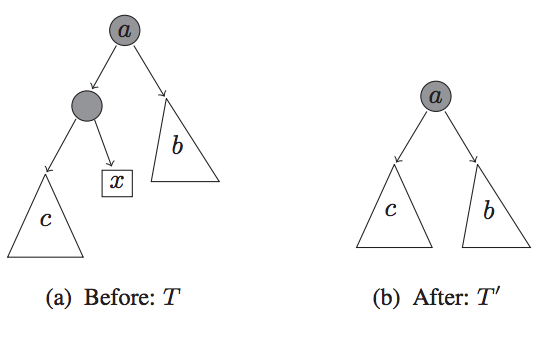
図8. 決定木の複雑度を減らす操作

式1. 簡略化したモデルから複雑なモデルとの誤差をもとに評価を決定
お気持ちとしてはモデルの複雑度(この場合は決定木の深さ)が、しきい値を超えたら、何らかの異常値があるとみなす、という流れです。
各系列で、様々に複雑度を見ていって、これをscoreとして、scoreの平均値と標準偏差の和などをしきい値として、しきい値が偏差を超えたら異常値と定義するなどで使えます。
タクシーの乗車数の異常検知
ニューヨークの日々のタクシーの利用者数をtime seriesで格納されたデータを用いて、異常値検知を行っていますが、2018/05/01に投稿されたはずなのポストですが、動作しませんでした。
追試したところ、以下のようにコードを変更する必要がありました。
変更前
rcf.set_hyperparameters(
num_samples_per_tree=200,
num_trees=50,
feature_size=1)
変更後
rcf.set_hyperparameters(
num_samples_per_tree=200,
num_trees=50,
feature_size=1)
一通り実行した内容のjupyterがあるので、必要に応じて参照してください
感想としては、これは、パラメータ調整次第で、prophetで扱えない高次元の入力となる系列情報も対応かのうそうで、問題によっては使う意義がありそうです。
想定されるユースケース
インスタンスを建てないでJupyterで分析, MLする。
AWSと密に運用されたサービスでモデルの学習とデプロイを行う
SageMakerのモジュールのIF自体が微妙にわかりにくく、学習コストがそれなりに掛かるので、必要でなければ、ScikitLearnとかでローカルで動作させてしまったほうが楽かなと思いました。