不動産価格分析とモデルの作成とクローム拡張
序
機械学習で不動産を予想する意味
特徴量から重要度を知ることができるEndUserにとって嬉しいことは?
線形モデルならばChrome ExtentionなどJavaScriptなどにモデルを埋め込むこともでき、意思決定の補助材料などとして、不動産の情報の正当性を推し量る事ができる管理会社にとって嬉しいことは?
特徴量の重要度が明確にわかるため、設備投資戦略をどうするか、異常に値段がずれてしまっている案件の修正などに用いることができる
データを集める
- ダウンロード済みのデータはこちらLink
モデルを検討する
1 / (2 * n_samples) * ||y - w*x||^2 + alpha * l1_ratio * ||w|| + 0.5 * alpha * (1 - l1_ratio) * ||w||^2
目的関数はこのように定義され、alpha, l1_ratioのパラメータを自由に設定することでCross-Validationの性能を確認することができる
独立な情報でone-hotベクトルを仮定
線形モデルは事象が可能な限り独立であると嬉しく、特に特徴量の重要度を知りたい場合、categoricalな変数がone-hotベクトルで表現されている方が、continiusな値の係数を出すより解釈性能として優れる(これは性能とトレードオフの場合がある)optunaで最適化 alpha, l1_ratioは自由に決められる 0 ~ 1の値なので、探索する値の対象となる。
optunaというライブラリが超楽に探索できる
def objective(trial): l1_ratio = trial.suggest_uniform('l1_ratio', 0, 1) alpha = trial.suggest_uniform('alpha', 0, 1) loss = trainer(l1_ratio, alpha) # <- 具体的なfoldをとって計算するコード return loss
このように目的関数を定義して、最適化の対象となる変数を必要なだけ作成する
東京と全国でモデルを分け、n-foldの結果
東京
$ E001_encoding_tokyo_csv.py
$ python3 F001_train.py
...
[I 2019-03-23 03:25:29,056] Finished trial#19 resulted in value: 3.4197571524870867. Current best value is 2.2600063056382806 with parameters: {'l1_ratio': 0.003751256696740757, 'alpha': 0.8929680752855311}.
2.2600063056382806 # <- 平均、2.26万ぐらいはズレがあって、このパラメータが最良であったという意味
全国
$ E001_encoding_all_country_csv.py
$ python3 F001_train.py
...
[I 2019-03-23 03:31:46,979] Finished trial#19 resulted in value: 1.8120767773887. Current best value is 1.37366033285635 with parameters: {'l1_ratio': 0.006727252595147615, 'alpha': 0.1862555099699844}.
1.37366033285635 # <- 平均、1.37万ぐらいはズレがあって、このパラメータが最良であったという意味
Chrome Extentionを作る
モデルを具体的にどう使うかいくつかのユースケースがあるが、今回はWebの面に対して各要素から、家賃価格を予想するようなものを作成する。
モデルの作りが線形モデルになっているため、割と簡単にJavaScriptにモデルを組み込むことができる。(面側の言葉のゆらぎなどに脆弱ですが)
※ githubのreal-estate-value-prediction/chrome-ex-template/srcをChromeのchrome://extensions/より、インストールすることができます。
分析
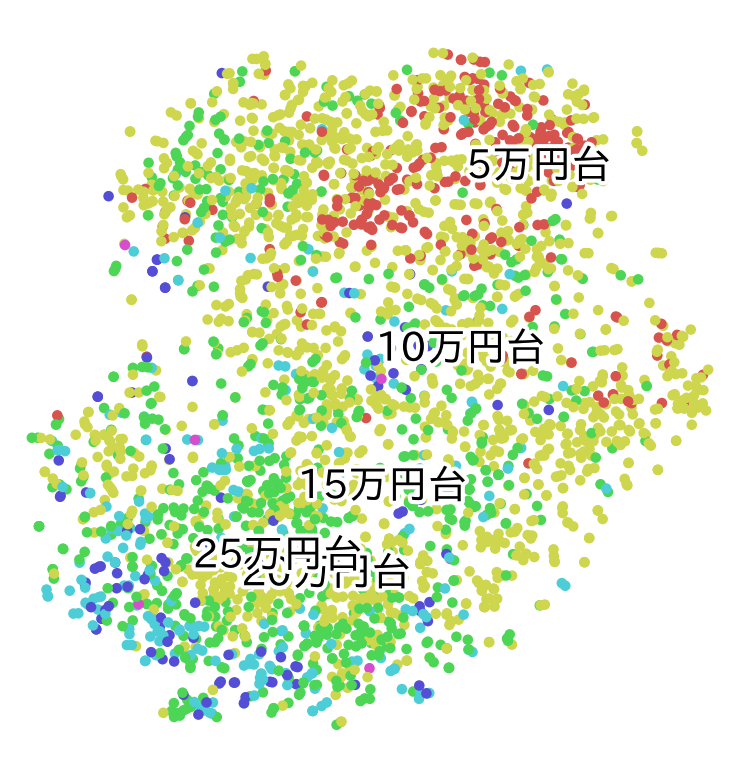
- 東京23区の一般的な特徴量(部屋の種類、何区、設備など)からt-sneを行うと、クラスタが分かれるより連続している事がわかる
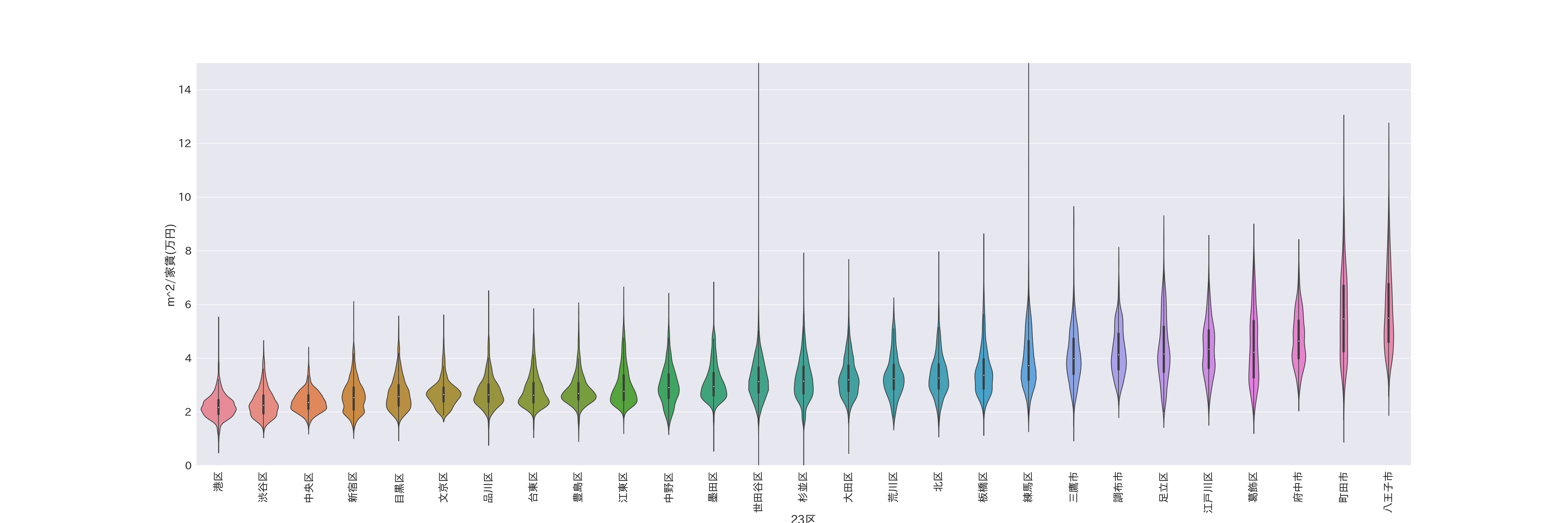
- 東京23区の一万円あたりで借りられる面積のバイオリン図
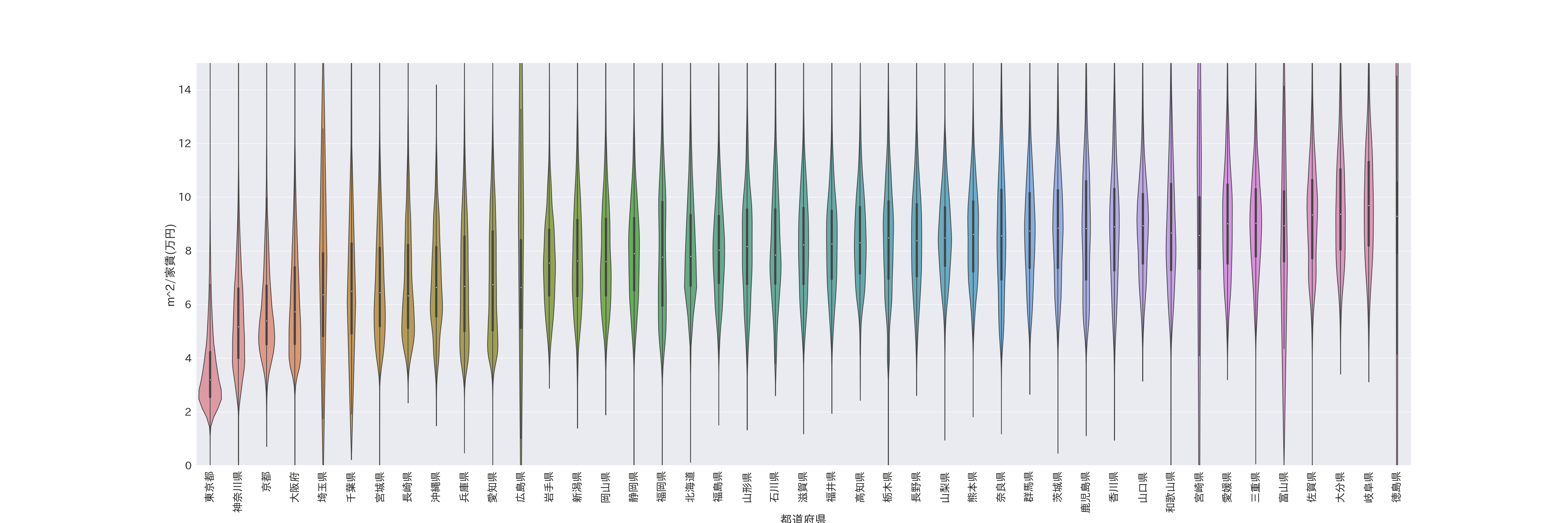
- 都道府県の一万円あたりで借りられる面積のバイオリン図
特徴量重要度
ElasticNetの特徴量の重要度で、重要度がプラス側に倒れるほど価格にプラスに影響する特徴量で、マイナスに倒れるほど価格にマイスに影響する特徴量になる。
- 東京の結果
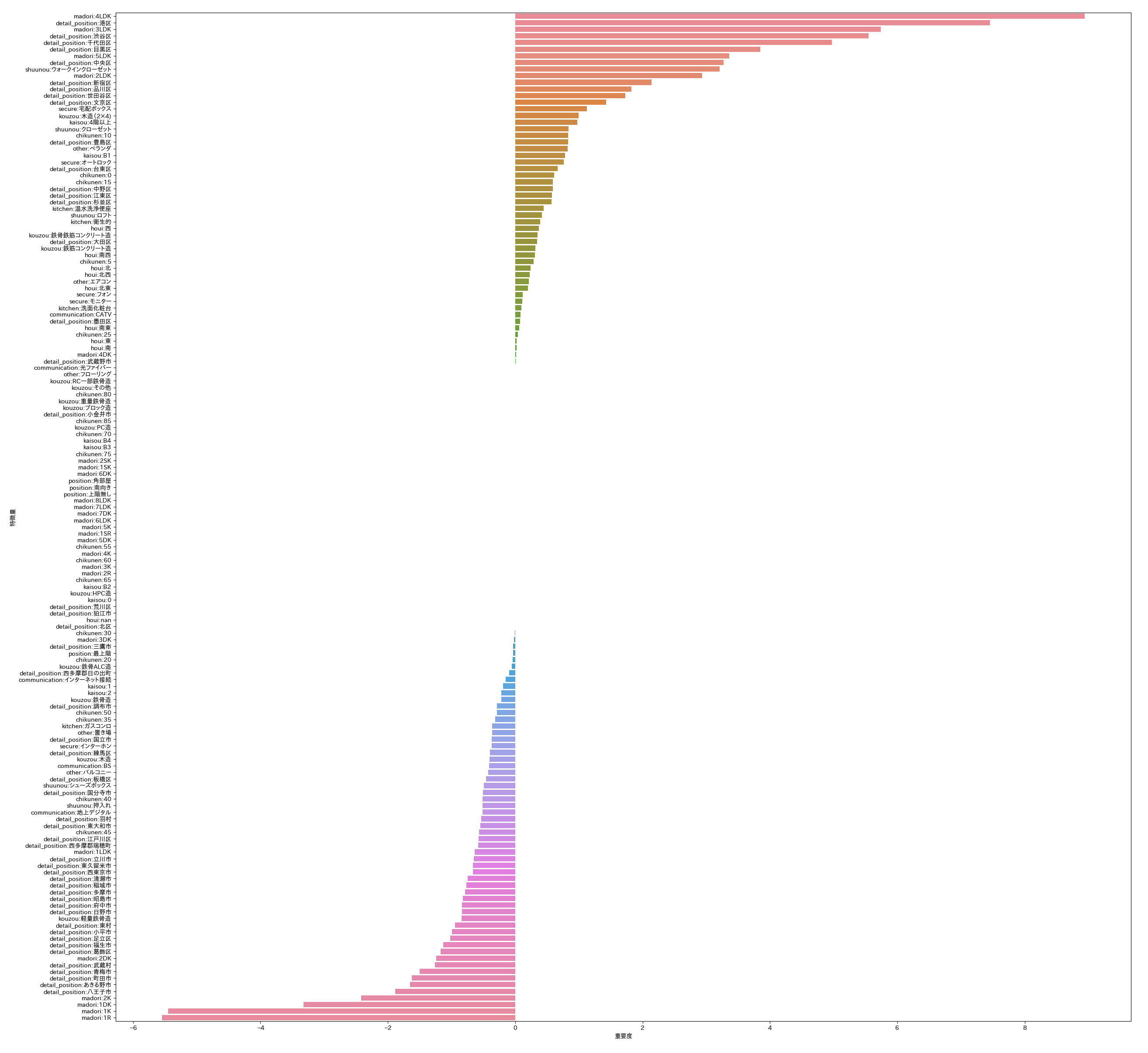
細かいので拡大して閲覧してください
- 全国の結果
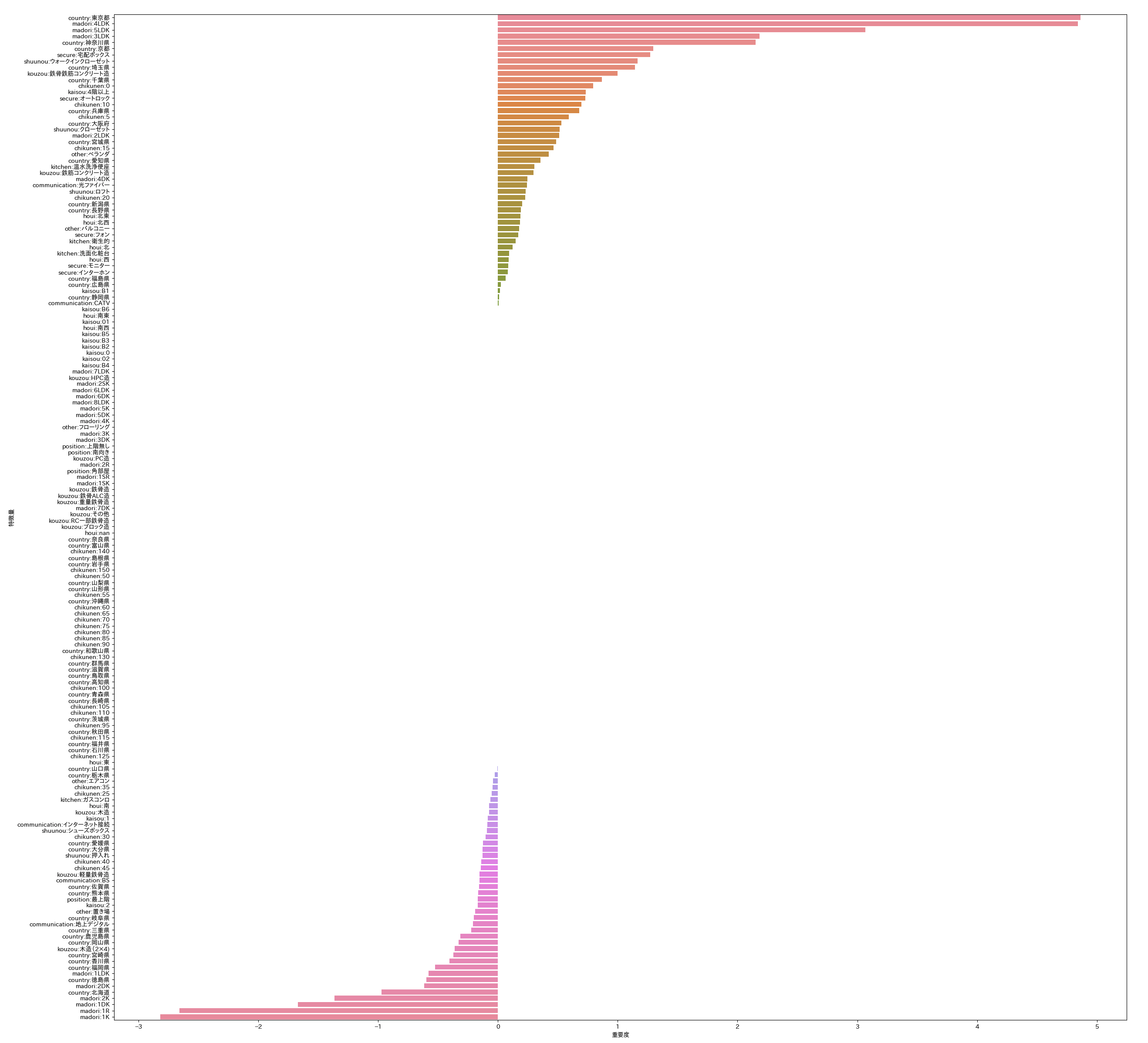 細かいので拡大して閲覧してください
細かいので拡大して閲覧してください
Chrome Extentionのユースケース
なれないJavaScriptを書いて作ったものになります。
このGitHubのコードをもとに作成しました。
"ネットで賃貸"さまのデータから、"Homes"さまの東京の詳細情報を評価できるChrome Extentionを作ってみました。


JSわからないなりに頑張った…
- 価格差が大きいとはなにかあるのでは無いかを考えられる
当然ながら、事故物件であるようなフラグは存在しないので、今回のモデルは特徴量として獲得していない。 例えば、異常に安い物件があるのならば、なにかそれを説明する変数(事故など)が背景にあると考える一助になる。
今回のモデルがあれば相場がわからない人がぼったくられるようなことを防ぐようなことも、インターフェースを整理すれば可能になるだろう。
コード説明
- A001_parse_htmls.py : chintai.netのhtmlのパース、データは上記のDropboxよりダウンロード
- B001_lexical_parse_json.py : ヒューリスティックにタグを解析してパースする
- C001_analysis_country_agg.py : バイオリンプロットの可視化
- E001_encoding_all_country_csv.py : 全都道府県の粒度でワンホットエンコーディング
- E001_encoding_tokyo_csv.py : 23区の粒度でワンホットエンコーディング
- F001_train.py : 学習
- chrome-ex-template/src : クローム拡張の本体
Excelの光と影 ~Excelデータ分析を超えていけ~
Excelは便利なソフトで、あらゆる企業で使われている表計算ソフトウェアですが、国内ではその役割が拡張されドキュメント作成的な意味もあります。
まともな使い方としてのExcelもあり、分析してと渡されることが多いフォーマットでもあります。
私自身のいくつか経験した案件を踏まえ、Excelとその周辺文化がデータ分析の妨げになっているという感想を持っていて、可能な限り、客観的に示していこうと思います。
Excelの功罪
一般的にExcelについてそのメリットやデメリットが語られる際、どのようなことが言われるのでしょうか。
おそらくデータに携わる人では、このような共通認識があるかと思います。
良い点
- 小さいデータから完結に何かを述べるときに便利
- グラフが簡単にかけて、可視化する際に便利
- プログラミングなど複雑なことがわからなくても大丈夫
悪い点
- セル結合はデータがパースが難しいかできない
- 人間が手入力してもそれなりに仕事になるので、データソース源として考えたとき、大量のデータを保存する文化が育たない
- カラムが揺らぐなどでパースと結合が難しい
各分析経験から、うまく行ったもの、うまく行かなったものの例示
Excelに対する思い込みや見落としがある可能性があるので、このような思いがどうして導かれたか明らかにする必要があります。
具体的な仕事での案件を通じ、公開して問題ない程度に抽象化して、どのような経験があったかを述べて抽象化していて特徴を明らかにします。
うまく行かなかった分析
1 公共法人の人口減少原因の分析
- 概要:各市町村がホームページで出しているデータから、年代、職業、学校、病院等の公共施設の充実度等から、人口減少を説明するモデルを構築し、その重要度を見る
- データ:各市町村が提出しているExcel, PDF, CSVの混在データ[1-3]
- 問題点:各市町村でHPのフォーマットと出力形式が一定していなくExcel, PDF, CSVが混在している。データを提供するという文脈を、分析してアグリゲートして結論だけを述べたものを提供している。そのため、日本の市町村を横断してそれなりのデータ量にして、分析者によらず客観性がある程度担保される定量分析にならず、分析者のドメイン知識を大量に投入してそれなりの説明力を出す定性的で属人化するモデルになりがち。
- 最終的な出力:人口の増減を2値分類して、特徴量の分布からそれなりに説明が付く定性的な文脈を作成(職を安定させることと、若者を増やすような施策を打つことが人口増加戦略の基本であるという結論になったが、データが少ないため数字の頑健性が少なく、もっと特徴量を調べたかった)
2 CRMとExcelから企業分析をする
- 概要:売上のデータから、経営で気をつけるべきインサイトを明らかにし、投資する点として美味しいポイントなどを発見する
- データ:CRMとExcel
- 問題点:CRMが古くデータ構造が入力者にとって自由に拡張されている & 入力にサニタイズの処理が入っておらず、自由に好きなテキストで入力できる形式になってしまっている。CRMで補完できない部分をExcelでカバーするという発想であり、データ分析を最終的にリーチさせるという視点がなかった。
- 最終的な出力:データを機会学習に掛ける前の段階で大いにつまずく、これはカラム名が不安定であったり、一定のルールでカテゴリ変数に対応する自由入力フィールドがサニタイズできないため、データボリュームを稼ぐことが難しく、アウトプットに数字的な頑健性が与えられなかった
3 イベント等の分析
- 概要:コンサートやライブなどのイベントの席は有限である。満員までよく埋まるが、潜在客はどの程度あり、ライブ会場をより広い会場にすると収益が最大化するのか知りたい
- データ:Excel
- 問題点:Excelでなんからの分析結果を示した内容であり、データがアグリゲートされており、情報が少なく、別の結論を導くのは難しい。カラムがかなり揺らいでおり、データを束ねて定量解析するという視点に向いていない(人力サニタイズしかない)。人間が手でデータを入力するため、間違いが結構ある(私も人力で修正して人力で突合するのでデータ誤差がどんどん累積する)
- 最終的な出力:ロジック的にはおそらく行けるというものを大量に投入したが、どうにも納得感のある数字にならず、インサイトとしては弱かった。
うまく行った分析
1 Hadoopに蓄積されたユーザ情報からインサイトを明らかにする
- 概要:とある企業のサービスの行動ログからHadoopに蓄積されたデータから何らかのインサイトを得る
- データ:広告を配信したユーザの行動をトラックして、ユーザの行動を明らかにして、別サービスとのレコメンデーションにしたり、サービス同士のユーザの流出などを見たりする(最近流行りのCookieを許可してくださいとかの走り)
- うまく行った要因:今はBigQueryがあるけど、当時のビッグデータ基盤はHadoop的なものが主流で大量の生データが保存されていた。サービスを横断して分析を行いインサイトを得る
- 最終的な出力:サービス横断施策のインサイト
2 SNSから各種KPIを予想する
- 概要:その時の時代の流行りの語と各種KPIから因果推論のサポートを行う
- データ:テキストとBigQueryにはいったKPI情報
- うまく行った要因:情報量が多く、機械的なデータであったので、擬似相関を一部をシステムで、残りを人間の方で吸収するという視点にたてば、時代背景やその時の流行りと関連性をある程度明確にすることができた
- 最終的な出力:あるKPIがある時、そのKPIはSNSのどのバズワードによって引き起こされたか可能性があるのかを網羅的に提示することができた(ロジックは良かったものの政治的要因とうネガティブな要素は今回は見ていない)
3 イベント等の分析(仕切り直しバージョン)
- 概要:コンサートやライブなどのイベントの席は有限である。満員までよく埋まるが、潜在客はどの程度あり、ライブ会場をより広い会場にすると収益が最大化するのか知りたい
- データ:Apache Log
- うまく行った要因:うまく行かなかったものを仕切り直したバージョン。データソースをExcelから、Apache Logに変更した。情報源としての誤りが少ないのと、情報量自体が多かった。
- 最終的な出力:数字的に納得感があり、分析として意味のあるものになった
ここからうまく行かなった理由を分析する
共通項1 : パースしにくいExcelなどをデータソースとすると、うまくいかない
共通項2 : 生の非構造化データや構造化データを問わず、ビッグデータと呼ばれるほどデータが多いとうまくいく
共通項3 : 何らかのビジネス的なKPIを報告する目的で、アグリゲートされた分析結果を再度利用するものはうまくいかない
さらに整理して図示するとこの様になります。

Excelでカラム名が揺らいでしまう + パースが難しい一般例(共通項1の深掘り)
奥村さんの有名な神エクルの問題[5]でも述べらているとおり、Excelでデータを貰ってもそれを分解して定量分析するには、Excelの自由な入力形式故に機械的にパースすることが難しく、データ量を稼ぐことが難しくなってきます。
データのボリュームを多くすれば、気づきにくい特徴であっても何かしら発見を行うことができ、ビジネス的にも有意義です。
カラムのゆらぎ

図1. 入力する人間の使う語で入力されるためカラム名がゆらぎがち
カラムが可変長レコード

図2. 機械的にパースすることができるが、使い捨てのちゃんとしたコードをたくさん書く必要がある
正規化されたレコードが結合できない

図3. 要素名が揺らいでいたりして突合できない
より一般化したデータの不可逆性と情報量の関係(共通項2, 3の深掘り)
Excelで報告書をもとに分析してと言われることが多いのですが、報告書自体が何らかのデータをアグリゲートしたものであり、そこから別の角度で何かを発見するのが難しいのかを、情報の不可逆性と、情報量の関係から示します。

図4. よくある熱の不可逆性
”仕切りを開ける”という操作を行うと、2つの分子運動は混じり合って、もとに戻せなくなります。
例えば、データ分析の文脈では、”仕切を開ける”という操作ではないですが、もとに戻せなくなる操作があります。
例えば中学校のテストのデータをもとになにかの操作を行ったとすると、もとに戻せなくなることが自明であるかと思います

図5. meanの操作を行った結果だけから、もとのデータを戻すことができない
この操作は多くのアグリゲート関数について成り立ち、sum, min, max, mean, mode, mediunなど、単射である処理について成り立ちます。
情報量を下げる操作が多くの報告書では行われている
情報量の観点から具体的に高校の進学率の例で導いていきます

図6. 少しずつデータが要約される
この結果から何らかのアグリゲートされた値からは、不可逆性があり、かつ情報量が減少しています。
情報量が下がるということはどういうことかというと、情報の曖昧さが少ないということですが、上記の平均の例では、それ部活動や都道府県の情報を捨ててスコープを絞ることで、情報量を下げています。
意思決定層に見せるデータは完結でごちゃごちゃしてはいけないので、シンプルになっている事がほとんどです。そこから、もとのデータの分布がどうなっていたのかは復元が基本的には不可能なので、別の結論を導くことが難しい事がわかるかと思います。
Excel分析で詰まったときに使える銀の弾丸
ソフトウェア工学で、銀の弾丸は存在しないという表現[5]で、万能の解決策は存在しないというものがあります。
個人の経験では、あるアプローチが取れる場合、案件が失敗したことがないようなソリューションがあります(個人だけの経験に限れば100%の解決力である)
その方法は、構造化されているいないに拘わらず「できるだけ分析対象の元情報に近いデータを取得する」です。
どういうことかというと、何かしらデータが出来上がっている背景には、もとのデータが存在するはずで、そこを参照すればいいということが大いにあります。

図7. 大体、最初は下の方のデータを渡されるので、データの源流をたどり、上に持っていく
何かしら集計の途中で意図してか意図しないでかデータ整形のプロセスのなかでクリティカルな特徴が消えてしまったり、あまりやってほしくないアグリゲーションが行われて出したいデータが出せなかったりしていることが多々あります。
そんなとき、データの源流を探す旅にでるのは有意義で、クライアントがそもそも気づいていなかった新たな事実の発見や、なんとなく感覚でしかわからなかった事実を定量的に表すことが可能になり、ビジネス的にもデータ分析的にも大変有効です。
参考文献
- [1] 宇都宮市データバンク
- [2] OpenData那須
- [3] 日光市のデータ
- [4] 情報量
- [5] 銀の弾丸
5ch(旧2ch)をスクレイピングして、過去流行ったネットスラングの今を知る
5ch(旧2ch)ではここ数年はTwitterを使用するようになってしまいましたが、ネットのミームの発信地点であって、様々なスラングを生み、様々な文化を作ってきたと思います。
学生時代、2chまとめとか見ていたので、影響を受けてきたネット文化で、感覚値からすると、どうにも流行り廃りがあるようです。
5chの過去ログを過去18年ほどさかのぼって取得する方法と、懐かしいネットスラングのドキュメントに占める出現具合を時系列でカウントすることで、時代の変遷でどのように使用の方法が変化したのか観測することができます。
文末に「orz」って付けたら若い人から「orzってなんですか?」と聞かれて心身共にorzみたいになってる
— ばんくし (@vaaaaanquish) October 19, 2018

図1. 今回集計したorzの結果
例えば、今回集計した5chの書き込み500GByte程度のログからでは、orzというネットスラングは、2005年をピークに書き込みの中で出てくる頻度がどんどん下がっています。
orzという表現は、若い人が知らないのも、まぁしょうがない、といった感じのネットスラングのようです。
5chの過去ログをスクレイピングするには
前々から5chのコーパスは欲しかったのですが、どこから、どうやって取得すればいいのかわからなかったのですが、なんとかPython3 + requests + BeautifulSoupの組み合わせで確立した方法があるのでご紹介します。
幅優探索による過去ログのスクレイピング
URL同士のリンクばネットワーク構造になります。
スクレイピングする際の戦略として、ネットワークをどうたどるか、という問題で、幅優先探索を行いました。
2chの過去ログから辿れるログは平面的に大量のリンクを2~3回たどれば目的のデータにアクセスできる構造で幅優先探索に適していたからという理由です。

起点となる一点を決める
かねてから2chの全ログ取得は夢でしたが、様々な方法を検討しましたが、ログが保存されているURLの一覧が存在しないということで諦めていたのですが、ついに発見するに至りました。
以下のURLからアクセスすることができ、多くのスレの過去ログサーバを参照しています。
そのためここからアクセスすることで2chの過去ログをスクレイピングすることができます。
http://lavender.5ch.net/kakolog_servers.html
レガシーなhtmlフォーマットに対応する
Pythonのhtmlパーサーを前提に話しますが、旧2chのHTMLは正しいHTMLというわけでないようです。
tableタグを多用するデザインが2017年度半ばまで主流だったようで、このときのタグに閉じるの対応なく、lxml, html.parserなどを使うと失敗します。
そのため、一部の壊れたhtmlでもパースできるようにhtml5libパーサーを利用してパースすることができます[1]
この問題は、BeautifulSoupのパーサを以下のようにhtml5libに設定すれば解決することができます。
soup = bs4.BeautifulSoup(html, 'html5lib')
並列アクセスを行う
2chの過去ログは、一つ一つのサーバに名前がついていて、各サーバが異なったサブドメインを持っています。
そのため、異なった実サーバをもっていると考えられるので、サーバごとにアクセスを並列化することで高速化することができます。加えて、もともとPythonのrequestsとBeautifulSoupを使ったhtml解析が重い作業なので、マルチコアリソースを最大限利用して、並列アクセスする意義があります。
集計するネットスラングの選定
一般的なネットスラングは時代の変遷の影響を受けるという感覚値がありました。
具体的には、その日における単語の頻度が人気があると高くなり、低くなると下がっていくという感覚値があり、時系列にしたとき、人気の発生から、使われなくなるまでが観測できるのではないかと思い、集計しました。
過去、20年間に存在してきた様々なネットスラングについて、様々なまとめ[2]があり、みているととても懐かしくなります。
記憶に強く残っていたり、違和感があったり、今でも使わているのだろうか?最近見ていないがどの程度減ったのか?、という視点で選んだ単語がこれらになります。
(下記に記したGitHubの集計コードを変更することによって、任意のキーワードで再集計することができます、よろしかったらやってみてください)
- orz
- 尊師
- 香具師
- 笑(文末)
- 初音ミク
- 結月ゆかり
- コードギアス
- hshs
- iphone
- うp
- 自宅警備員
- ワンチャン
- ステマ
- 情弱
- チラ裏
- 今北産業
- 禿同
- w(文末)
- メシウマ
- まどマギ
- ソシャゲ
- ジワる
- ナマポ
- (ry
- ggrks
- オワコン
この計算は、下記のGitHubのexamples/time_term_freq.pyで行うことができて、プログラムを変えることで集める単語を変更することができ、再集計することができます。
htmlをjsonl化する
スクレイピングしたhtmlをスレの内容を取り出し、jsonl(一行に一オブジェクトのjson)にしておくといろいろと集計が都合がよいです。
scan_items.pyというプログラムでパースできるので、参考にしてください。
$ python3 scan_items.py
結果
examples/time_term_freq.pyを実行することで得られます。





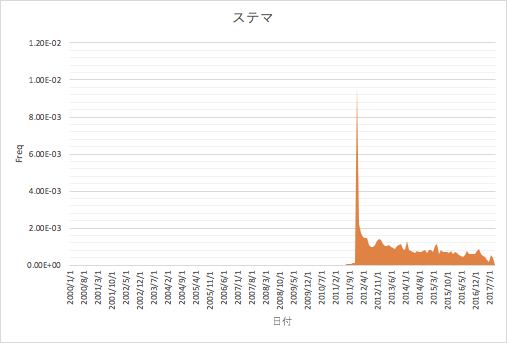










仮説どおり、ネットスラングは流行り廃りがあり、今は殆ど使われなくなったものがどの時期から消えていったのか視覚化されました。
また、文末にwをつけるなどの草を生やす表現は今も強くなりつづけており、しばらく使っても老害扱いされないでしょう(安心)。
感覚値と実際にデータで表されるネットスラング表現の隔たりが明らかにされ、発祥や時代感が不明確であったりしたものが整理され、発見的な集計となりました。
コード
参考
テーブルデータに対して、DenosingAutoEncoderで精度向上
データセットの問題
Kaggle Porto Seguroでは問題となっている点があって、テストデータとトレインデータのサイズの方が大きく、トレインだけに着目してしまうと、LeaderBoardにoverfitしてしまう問題があります。
これはトレインだけで学習するために起こる問題で、テストデータ・セットを有意義に使う方法として、教師なし学習でまずは次元変換やなんやらを行うという方法が有効なようです。
ディープを用いることでいくつか有益な変換操作を行うことができて、「すべての情報は何らかのノイズを受けている」という視点に立ったときに、恣意的にAutoEncoderの入力にノイズを乗せ、それを除去するように学習するとはっきりと、物事が観測できるようになったりするという特徴を利用しています。

図1. よくある画像の例
画像の利用からテーブルデータの利用に変換する操作を行います。
このテーブルデータに対して適応するという発想と用途はあまり見たことがなかったので、有益でした。(画像にノイズがかかっていますが実際は値に対してかかります)

図2. テーブルデータのノイズを除去
MichaelさんのとったDAE(DenosingAutoEncoder)の特徴
noiseを掛ける方法
swap noiseという方法を用います。これは、uniformやgaussian noiseをこれらに和算や積算などで、かけても適切ではないという点を抱えているため、いくつかのハッキーな方法が取られています。
swap noiseはランダムに10%程度の確率で、"同じ列"で"他の行"と入れ替える技で、これによりノイズを掛けます。
これをすべての要素にたいして適応するすると、割と現実的なnoisingになるそうです。

図3. swap noise
numpyのアレイをコピーしてすべての要素を操作していって、 10%の確率で"同じ列"、"別の行"と入れ替えます
import numpy as np import random from numba.decorators import jit @jit def noise(array): print('now noising') height = len(array) width = len(array[0]) print('start rand') rands = np.random.uniform(0, 1, (height, width) ) print('finish rand') copy = np.copy(array) for h in range(height): for w in range(width): if rands[h, w] <= 0.10: swap_target_h = random.randint(0,h) copy[h, w] = array[swap_target_h, w] print('finish noising') return copy
rank gauss
Rank Gaussという連続値を特定の範囲の閉域に押し込めて、分布の偏りを解消する方法です。
これも彼の言葉を頼りに実装しました。
このようなコードになるかとおもいます。
import pandas as pd tdf = pd.read_csv('../input/train.csv') Tdf = pd.read_csv('../input/test.csv') df = pd.concat([tdf, Tdf], axis=0) print(df.head()) # catが最後につくとカテゴリ # binがつくとワンホット # 何もつかないと、連続値 from scipy.special import erfinv import re ## to_rank for c in df.columns: if c in ['id', 'target'] or re.search(r'cat$', c) or 'bin' in c: continue series = df[c].rank() M = series.max() m = series.min() print(c, m, len(series), len(set(df[c].tolist()))) series = (series-m)/(M-m) series = series - series.mean() series = series.apply(erfinv) df[c] = series df.to_csv('vars/rank_gauss_all.csv', index=None)
流れとしては、まずランクを計算し、[0, 1]に押し込めて、平均を計算し、(-0.5,0.5)に変換します。
これに対してerfiv関数をかけると、ランクの方よりが正規分布のような形変換することができます。
DAEパラメータ

図4. michaelさんが調整したパラメータ
このように、何種類かのDenosing AutoEncoderをアンサンブルして、Dropoutなどを充分につかって、結果をLinear Brend(線形アルゴリズムでアンサンブル)するそうです
chainerで作成した学習コード
長くなりますので、全体参照には、githubを参照してください。
from chainer import training from chainer.training import extensions import numpy as np import cupy as xp from chainer import report from chainer import Variable from sklearn.metrics import mean_squared_error # Network definition class MLP(chainer.Chain): def __init__(self): super(MLP, self).__init__() with self.init_scope(): self.l1 = L.Linear(None, 1500) # n_in -> n_units self.l2 = L.Linear(None, 1500) # n_units -> n_units self.l3 = L.Linear(None, 1500) # n_units -> n_units self.l4 = L.Linear(None, 227) # n_units -> n_out def __call__(self, h): h1 = F.relu(self.l1(h)) h2 = F.relu(self.l2(h1)) h3 = F.relu(self.l3(h2)) if is_predict: return np.hstack([h1.data, h2.data, h3.data]) h4 = self.l4(h3) return h4
学習部分
if '--train' in sys.argv: df = pd.read_csv('vars/one_hot_all.csv') df = df.set_index('id') df = df.drop(['target'], axis=1) EPOCHS = 2 DECAY = 0.995 BATCH_SIZE = 128 INIT_LR = 3 #0.003 model = L.Classifier(MLP(), lossfun=F.mean_squared_error) OPTIMIZER = chainer.optimizers.SGD(lr=INIT_LR) OPTIMIZER.setup(model) for cycle in range(300): noise = swap_noise.noise(df.values).astype(np.float32) train = TupleDataset(noise, df.values.astype(np.float32)) test = TupleDataset(noise[-10000:].astype(np.float32), df[-10000:].values.astype(np.float32)) # iteration, which will be used by the PrintReport extension below. model.compute_accuracy = False chainer.backends.cuda.get_device_from_id(1).use() model.to_gpu() # Copy the model to the GPU print(f'cycle {cycle-1:09d}') train_iter = chainer.iterators.SerialIterator(train , BATCH_SIZE, repeat=True) test_iter = chainer.iterators.SerialIterator(test, BATCH_SIZE, repeat=False, shuffle=False) updater = training.updaters.StandardUpdater(train_iter, OPTIMIZER, device=1) trainer = training.Trainer(updater, (EPOCHS, 'epoch'), out='outputs') trainer.extend(extensions.Evaluator(test_iter, model, device=1)) trainer.extend(extensions.dump_graph('main/loss')) frequency = EPOCHS trainer.extend(extensions.snapshot(), trigger=(frequency, 'epoch')) trainer.extend(extensions.LogReport()) trainer.extend(extensions.PrintReport( ['epoch', 'elapsed_time', 'main/loss', 'validation/main/loss'])) trainer.extend(extensions.ProgressBar()) def lr_drop(trainer): trainer.updater.get_optimizer('main').lr *= DECAY print('now learning rate', trainer.updater.get_optimizer('main').lr) def save_model(trainer): chainer.serializers.save_hdf5(f'snapshot_15000_model_h5', model) trainer.extend(lr_drop, trigger=(1, 'epoch')) trainer.extend(save_model, trigger=(10, 'epoch')) trainer.run() model.to_cpu() # Copy the model to the CPU mse1 = mean_squared_error( df[-10000:].values.astype(np.float32), model.predictor( noise[-10000:].astype(np.float32) ).data ) mse2 = mean_squared_error( df[-10000:].values.astype(np.float32), model.predictor( df[-10000:].values.astype(np.float32) ).data ) print('mse1', mse1) print('mse2', mse2) chainer.serializers.save_hdf5(f'model-sgd/model_{cycle:09d}_{mse1:0.09f}_{mse2:0.09f}.h5', model)
中間層の取り出し
データがそれなりに多いので、CPUで適当なサイズに切り出して予想します
npyファイル形式にチャンクされたファイルがダンプされます
if '--predict' in sys.argv: df = pd.read_csv('vars/one_hot_all.csv') df = df.set_index('id') df = df.drop(['target'], axis=1) model = L.Classifier(MLP(), lossfun=F.mean_squared_error) chainer.serializers.load_hdf5('models/model_000000199_0.007169580_0.001018013.h5', model) chainer.backends.cuda.get_device_from_id(0).use() model.to_cpu() # Copy the model to the CPU BATCH_SIZE = 512 print( df.values.shape ) height, width = df.values.shape is_predict = True args = [(k, split) for k, split in enumerate(np.split(df.values.astype(np.float32), list(range(0, height, 10000)) + [height] ))] for k, split in args: r = model.predictor( split ).data if r.shape[0] == 0: continue np.save(f'dumps/{k:04d}', r) print(r.shape)
結果
michaelさんのネットワークは5つのモデルのアンサンブルで、この個数を行うのは割と容易ではないです。
LightGBMにDAEのネットワークの活性化した値を入れると、精度向上をすることができまた。
LightGBMだけ
5-cv train auc 0.6250229489476413 5-cv train logloss 0.1528616157817217
DAE + LightGBM
※ Leaves, Depth, 正則化などのパラメータを再調整する必要があります
5-cv train auc 0.6403338821473902 5-cv train logloss 0.15185993565491557
注意
中間層を吐き出して、それをもとに再学習する操作が、想像以上にメモリを消耗するので、96GBのマシンと49GBのマシンの2つ必要でした。
軽い操作ではないです。
Deepあるあるだとは思うのですが、入れるデータによっても、解くべき問題によっても微妙にパラメータを調整する箇所が多く、膨大な試行錯誤が伴います。
プログラム
プロジェクト
rank-gauss.py
連続値や1hot表現をランクガウスに変換
swap_noise.py
テーブルデータを提案に従って、スワップノイズをかけます。
これは他のプログラムからライブラリとして利用されます。
dae_1500_sgd.py
OptimizerをSGDで学習するDAE(1500の全結合層)
dae_1500_adam.py
OptimizerをAdamで学習するDAE(1500の全結合層)
考察
テーブルデータも何らかの確率的な振る舞いをしていて、事象の例外などの影響を受けるとき、このときDenosing AutoEncoderでノイズを除去するように学習することにより一般的で、汎用的な表現に変換できるのかもしれません。かつ、ノイズロバストな値になっているので、これを用いることで精度に寄与するのはそんなに想像に難くないと思います。
しかし、理論的な裏付けや解析が十分に進んでいないのと、追試にものすごい試行錯誤と調整が必要でした。お勉強にはちょうどいいよね。
一度ちゃんと使えようにしておくと、テーブルデータから何かを予想する問題のときに、すぐ使えるので便利です(そして、実際に精度は上がります)