Pythonで100万ドキュメントオーダーのサーチエンジンを作る(PageRank, tfidf, 転置インデックスとか)
検索エンジンを何故作ってみたかったか
- もともとこのブログのコンセプトのNLP的なことで、情報を整理してなにか便利にしたかった(Googleと同じモチベーションの世界の情報を整理する)
- 4年前にほぼ同じシステムを作ろうとしたとき、500万を超える大量のインデックスを検索するシステムは、数学的な理解度が十分でない+エンジニアリング力が伴わないなどでギブアップした背景があり、今回再チャレンジしたくなった
- ほぼすべての機能をpure python(+いくつかの例外はある)で実装して、世の中の
ソフトウェアを使うだけの検索エンジンをやってみたなどではなく、実際に理解して組んでみることを目的としたかった
依存パッケージと依存ソフトウェア
GitHubのコードを参照してください
様々なサイトを巡回する必要があり、requestsが文字コードの推論を高確率で失敗するので、nkf をlinux環境で入れている必要があります。
$ sudo apt install nkf $ which nkf /usr/bin/nkf
Mecabも入れます
$ sudo apt install mecab libmecab-dev mecab-ipadic $ sudo apt install mecab-ipadic-utf8 $ sudo apt install python-mecab $ pip3 install mecab-python3 $ git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git $ ./bin/install-mecab-ipadic-neologd -n
残りの依存をインストールします
$ pip3 install -r requirements.txt
再現
基本的にGitHubのコードをUbuntu等のLinuxでAから順に実行してもらえば、再現できます。
クローラ(スクレイパー)はやろうと思えば無限に取得してしまうので、適当にSEEDを決めて、適当な時間で終了することを前提としていています。
全体の処理の流れ
- クローリング
- クローリングしたHTMLを, title, description, body, hrefsをパースしデータを整形する
- IDF辞書の作成
- TFIDFのデータを作成
- 転置したurl, hrefの対応を作成(単純な被参照量の特徴量)
- 非参照数のカウントと、PageRankのための学習データの作成
- URLとtfidfのウェイトの転置インデックスを作成
- hash化されたURLと実際のURLの対応表の作成
- PageRankの学習
- 検索のインターフェース

プログラムの詳細
A. クローリング
特定のドメインによらず、網羅的にクローリングしていきます。
ブログサイトをシードとしてドメインを限定せずどこまでも深く潜っていきます。
多様なサイトをクロールするがとても重いので、自作した分散可能なKVSをバックエンドのDBと利用しています。SQLLiteなどだとファイルが壊れやすく、LevelDB等だとシングルアクセスしかできません。

B. HTMLのパースと整形
Aで取得したデータは大きすぎるので、Bのプロセスで、tfidfでの検索の主な特徴量となる、"title", "description", "body"を取り出します。
また、そのページが参照している外部のURLをすべてパースします。
soup = BeautifulSoup(html, features='lxml') for script in soup(['script', 'style']): script.decompose() title = soup.title.text description = soup.find('head').find( 'meta', {'name': 'description'}) if description is None: description = '' else: description = description.get('content') body = soup.find('body').get_text() body = re.sub('\n', ' ', body) body = re.sub(r'\s{1,}', ' ', body)
BeautifulSoupでシンプルに処理することができる.
C. IDF辞書の作成
頻出する単語の重要度を下げるために、各単語がどの程度のドキュメントで参照されているかをカウントします。
D. TDIDFの計算
B, Cのデータを利用して、TFIDFとして完成させます
title description bodyはそれぞれ重要度が異なっており、 title : description : body = 1 : 1 : 0.001
として処理しました。
# title desc weight = 1 text = arow.title + arow.description text = sanitize(text) for term in m.parse(text).strip().split(): if term_freq.get(term) is None: term_freq[term] = 0 term_freq[term] += 1 # title body = 0.001 text = arow.body text = sanitize(text) for term in m.parse(text).strip().split(): if term_freq.get(term) is None: term_freq[term] = 0 term_freq[term] += 0.001 # ここのweightを 0.001 のように小さい値を設定する
F. あるURLと、あるURLのHTMLがリンクしているURLの転置インデックスを作成
昔良くあった、URLのリンクを色んな所から与えるとSEOができるということを知っていたので、どの程度外部から被参照されているか知るため、このような処理を行います
G. 被参照数のカウントと、PageRankのための学習データの作成
Fで作成したデータをもとに、networkxというライブラリでPageRankのノードのウェイトを学習可能なので、学習用データを作成します
このようなデータセットが入力として望まれます(右のハッシュがリンク元、左のハッシュがリンク先)
d2a88da0ca550a8b 37a3d49657247e61 d2a88da0ca550a8b 6552c5a8ff9b2470 d2a88da0ca550a8b 3bf8e875fc951502 d2a88da0ca550a8b 935b17a90f5fb652 7996001a6e079a31 aabef32c9c8c4c13 d2a88da0ca550a8b e710f0bdab0ac500 d2a88da0ca550a8b a4bcfc4597f138c7 4cd5e7e2c81108be 7de6859b50d1eed2
H. 単語から簡単にURLを逆引きできるように、転置インデックスの作成
最もシンプルな単語のみでの検索に対応できるように、単語からURLをすぐ検索できるindexを作ります
出力が、単語(のハッシュ値)ごとにテキストファイルが作成されて、 URLのハッシュ , weight(tfidf) , refnum(被参照数) のファイルが具体的な転置インデックスのファイルになります
0010c40c7ed2c240 0.000029752 4 000ca0244339eb34 0.000029773 0 0017a9b7d83f5d24 0.000029763 0 00163826057db7c3 0.000029773 0
I. URLとhash値の対応表の作成
URLはそのままメモリ上に持つとオーバーフローしてしまうので、sha256をつかって先頭の16文字だけを使った小さいhash値とみなすことで100万オーダーのドキュメントであってもある程度実用に耐えうる検索が可能になります。
J. PageRankの学習
Gで作成したデータを学習してURLにPageRankの値を学習します。
networkxを用いれば凄くシンプルなコードで学習する事ができます
import networkx as nx
import json
G = nx.read_edgelist('tmp/to_pagerank.txt', nodetype=str)
# ノード数とエッジ数を出力
print(nx.number_of_nodes(G))
print(nx.number_of_edges(G))
print('start calc pagerank')
pagerank = nx.pagerank(G)
print('finish calc pagerank')
json.dump(pagerank, fp=open('tmp/pagerank.json', 'w'), indent=2)
K. 検索のインターフェース
検索IFを提供
$ python3 K001_search_query.py (ここで検索クエリを入力)
例
$ python3 K001_search_query.py
ふわふわ
hurl weight refnum weight_norm url pagerank weight*refnum_score+pagerank
9276 36b736bccbbb95f2 0.000049 1 1.000000 https://bookwalker.jp/dea270c399-d1c5-470e-98bd-af9ba8d8464a/ 0.000146 1.009695
2783 108a6facdef1cf64 0.000037 0 0.758035 http://blog.livedoor.jp/usausa_life/archives/79482577.html 1.000000 0.995498
32712 c3ed3d4afd05fc43 0.000045 1 0.931093 https://item.fril.jp/bc7ae485a59de01d6ad428ee19671dfa 0.000038 0.940083
...
実際の使用例
"雷ちゃん"等で検索すると、ほしい情報がおおよそちゃんと上に来るようにチューニングすることができました。
Pixivについては明示的にクローリング先に設定していないが、Aのクローラがどんどんとリンクをたどりインデックスを作成した結果で、自動で獲得したものです。

"洒落怖"など、他のクエリでも望んだ結果が帰ってきています。

検索のスコアリングはどうあるべきか
手でいろいろ試してみて、良さそうなスコアはこのような感じなりました。(私が正解データです)

本来は、謎のヒューリスティックに依存した掛け算やlogを取るアプローチより、正解の並び順を与えて、機械学習で正しい並び順になるように学習するのが筋が良いです。
SEOという文化が登場してもう何十年にもなると思うのですが、高いweightを被参照リンクなどに与えるとひどいことになります。アフィリエイトブログやアドネットワークのようなものが大量に上に来てしまいます。
結局できた
様々なクエリを売ってみてそれなりの検索をすることができました。
少なくとも500万 ~ 1000万ドキュメントぐらいならば、すぐ検索できるので、適切なユースケース(図書館とか病院のカルテとか)を設定すればいろいろな応用ができそうです。
アメブロでの流行語大賞のその後、各デモグラで使用する単語の違いなど
序
国内最大級の自然言語のデータ・セットが一般ユーザがアクセスできる範囲であるものは2chとアメブロなどがあります。
アメブロは広大で数千万の投稿があると思われますが、全てをパースし切ることはできませんでした。(またしなくてもサンプルサイズ的に十分だという視点ではあります)
ユーザには女性が多く、後述するFaceBookやLineなどの浸透スピードを鑑みると、レートマジョリティに相当するメディアだと思われます。
せっかくいろいろ遊べそうなコーパスであるのに、どうにも使い勝手が良くなく何かを導くのにアイディアをひねる必要があります。
アメブロ自体が自分と違う人間たちの巣窟であるので、なかなかおもしろい分析が思いつかず、だいぶ放置していたのですが、重い腰を上げてデータの基本的なところを見ていきます。
データ
- 2019/05/10からの過去のアメブロのスナップショット
- 1272万記事
- 142万人のプロフィール
ダウンロード
コード
基本的にはデータをダウンロードして A, B, C, D, ... の順序で実行していくことで再現できます(メモリが32GBは必要です)
分析(集計)すること
- 代表的な角度でのクラシフィケーション(分類)とその重要度
- 流行語大賞は結局、その後も根付くのか
- 周期性のあるキーワード
- TV,新聞の衰退と、SNSやYouTubeの躍進
こういった大規模コーパスで分類するのに向いている疎行列 + Stochastic Gradient Descent
Andrew NGさんが説明しているStochastic Gradient Descentの動画がありわかりやすいです。
すべてのデータ・セットを一度にオンメモリに展開して最適化するというものではないので、 1000万を超えるコーパスでもうまくすれば分類することができます。
ScikitLearnには線形モデル各種をSGDで最適化できる関数が用意されていて、SVM, Logistic Regressonなどなどが損失関数の設定で行えるようになっています。
またペナルティも、L1, L2のほかelasticが最新のScikitLearnでは用意されていて便利です(2019年5月現在のAnacondaのデフォルトのScikitLearnは実装されていないようですが、pipから入る方はインターフェースがきちんと実装されています)
実際にやった分類
ScikitLearnのSGDClassifierを利用して、ペナルティをelasticとしました。
kfoldしながら、optunaでAUCの最大となる点を探索しながら各種ハイパラを探索させています。
代表的な角度でのクラシフィケーション(分類)とその重要度
埼玉県民とそれ以外の違い
埼玉県民とそれ以外を分類を行おうとすると、 AUC 0.503 で実際はほとんど分類できませんでした。
分類性能は悪いが、その判断基準となった特徴量がユニークで面白いです。
埼玉県民のコーパスの特徴として「池袋」が入っているとそれらしいという結果になっており、実質的に池袋は埼玉県民の土地であるということがわかります。
表1. 埼玉県民とその他

男女の分類
男女の分類で見ると、 AUC 0.741 になり、そこそこの性能で分類できます。
男性言葉、女性言葉が分類用の特徴量として目立っており、どんな言葉を使えば男性らしく、女性らしく統計的になるのかわかりました。
表2. 男女の分類

1988年生以前生まれと以後生まれ
勝手に若いというを1988以前, 1988以降の生まれの人の記事の分類をすると、 AUC 0.681 で分類できる
おそらく携帯電話の頭である 090 が最もわかりやすい特徴量になっていることや、息子、娘がいること、文章中の 〜 も年寄りくさいな、、、と思っていたのですが想像通りなる部分もあるし、アルゴリズムにより初めてこの特徴量が効くのかと認識できるものもあります。
表3. 年代別

サービスのユーザの人口の高齢化
ニコニコ動画も高齢化しているというデータがあるように、実はアメブロでも同様の老化が起きていることがわかっています。
ユーザプロフィールと登録している生年月日を突合すると、ブログを書いたときの平均年齢が逆算できる。
その時の平均の年齢を age とすると、このようなグラフになります

図1. 年齢の経年変化
ほぼサービス人口の年齢が新陳代謝していません
結局流行語(大賞)は長生きするのか
見ていきましょう
アメブロはサービスとしても現在進行系で記事数が増加しておりそのバイアスを排除するため、その集計粒度の月の総数で割ることで一定の正規化をしています
壁ドン(2014年)

図2. 壁ドン
妖怪ウォッチ(2014年)

図3. 妖怪ウォッチ
爆買い(2015年)

図4. 爆買い
PPAP(2016年)

図5. PPAP
ライフステージなどに応じたキーワード
ガン

図6. ガン
出産

図7. 出産
結婚

図8. 結婚
周期性のあるキーワード
花粉症

図9. 花粉症
PM2.5

図10. PM2.5
暑い

図11. 暑い
2018年が過去ないほどの比率で”暑い”と言われており、実際に人々がそう感じていたということが定量的にわかります
TV,新聞に対して、SNS各種は継続して人気が上がり続ける
ブロードキャスト型のコンテンツのテレビに対して、twitter, facebook, line, youtube, instagramなどは人気が上がり続けています

図12. Twitter

図13. Facebook
line

図14. line
インスタグラム

図15. インスタグラム
YouTube

図16. YouTube
テレビ

図17. テレビ
新聞

図18. 新聞
まとめ
何らかの判別のモデルを作成して、その特徴量を見ると何で分離されているのかわかりやすいのですが、判別性能が十分に出ないのであれば、強く一般化できない特徴量だと思われます。
アメブロという媒体の特性か、Twitterで流行りの激おこぷんぷん丸などのバズワードや言い回しは殆ど使われていないようでした。
サービス自体が若い世代の参入が少ないという状態にあるので、ガンの頻出や結婚出産もブログサービスの経過年月に比例して上がっていることがわかりました。
高齢化の影響を受けつつもテレビと新聞は人気が現状維持か少し落ち気味です。年齢的なバイアスを外せばSNSに順調にシェアを奪われているように見えます。
不動産価格分析とモデルの作成とクローム拡張
序
機械学習で不動産を予想する意味
特徴量から重要度を知ることができるEndUserにとって嬉しいことは?
線形モデルならばChrome ExtentionなどJavaScriptなどにモデルを埋め込むこともでき、意思決定の補助材料などとして、不動産の情報の正当性を推し量る事ができる管理会社にとって嬉しいことは?
特徴量の重要度が明確にわかるため、設備投資戦略をどうするか、異常に値段がずれてしまっている案件の修正などに用いることができる
データを集める
- ダウンロード済みのデータはこちらLink
モデルを検討する
1 / (2 * n_samples) * ||y - w*x||^2 + alpha * l1_ratio * ||w|| + 0.5 * alpha * (1 - l1_ratio) * ||w||^2
目的関数はこのように定義され、alpha, l1_ratioのパラメータを自由に設定することでCross-Validationの性能を確認することができる
独立な情報でone-hotベクトルを仮定
線形モデルは事象が可能な限り独立であると嬉しく、特に特徴量の重要度を知りたい場合、categoricalな変数がone-hotベクトルで表現されている方が、continiusな値の係数を出すより解釈性能として優れる(これは性能とトレードオフの場合がある)optunaで最適化 alpha, l1_ratioは自由に決められる 0 ~ 1の値なので、探索する値の対象となる。
optunaというライブラリが超楽に探索できる
def objective(trial): l1_ratio = trial.suggest_uniform('l1_ratio', 0, 1) alpha = trial.suggest_uniform('alpha', 0, 1) loss = trainer(l1_ratio, alpha) # <- 具体的なfoldをとって計算するコード return loss
このように目的関数を定義して、最適化の対象となる変数を必要なだけ作成する
東京と全国でモデルを分け、n-foldの結果
東京
$ E001_encoding_tokyo_csv.py
$ python3 F001_train.py
...
[I 2019-03-23 03:25:29,056] Finished trial#19 resulted in value: 3.4197571524870867. Current best value is 2.2600063056382806 with parameters: {'l1_ratio': 0.003751256696740757, 'alpha': 0.8929680752855311}.
2.2600063056382806 # <- 平均、2.26万ぐらいはズレがあって、このパラメータが最良であったという意味
全国
$ E001_encoding_all_country_csv.py
$ python3 F001_train.py
...
[I 2019-03-23 03:31:46,979] Finished trial#19 resulted in value: 1.8120767773887. Current best value is 1.37366033285635 with parameters: {'l1_ratio': 0.006727252595147615, 'alpha': 0.1862555099699844}.
1.37366033285635 # <- 平均、1.37万ぐらいはズレがあって、このパラメータが最良であったという意味
Chrome Extentionを作る
モデルを具体的にどう使うかいくつかのユースケースがあるが、今回はWebの面に対して各要素から、家賃価格を予想するようなものを作成する。
モデルの作りが線形モデルになっているため、割と簡単にJavaScriptにモデルを組み込むことができる。(面側の言葉のゆらぎなどに脆弱ですが)
※ githubのreal-estate-value-prediction/chrome-ex-template/srcをChromeのchrome://extensions/より、インストールすることができます。
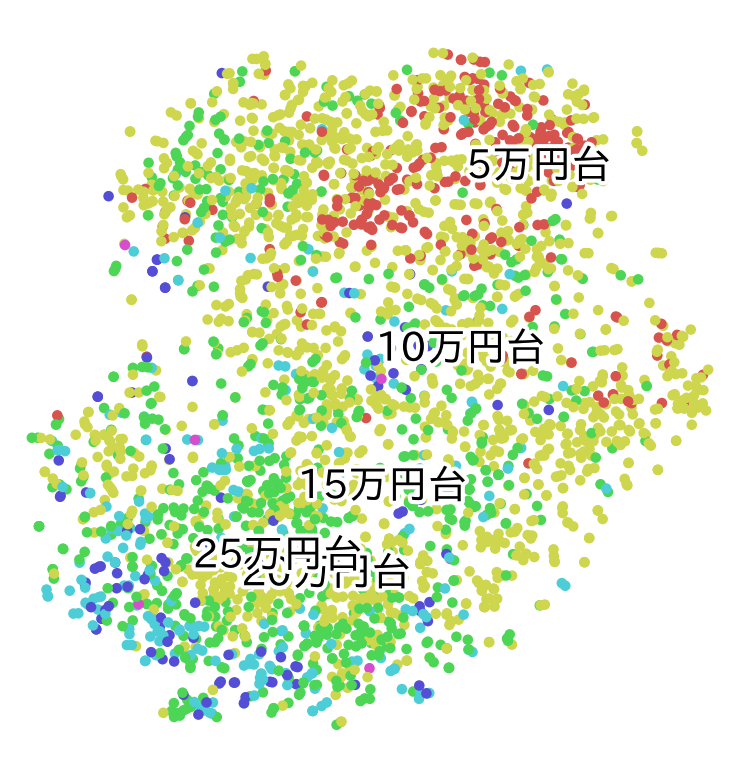
分析
- 東京23区の一般的な特徴量(部屋の種類、何区、設備など)からt-sneを行うと、クラスタが分かれるより連続している事がわかる
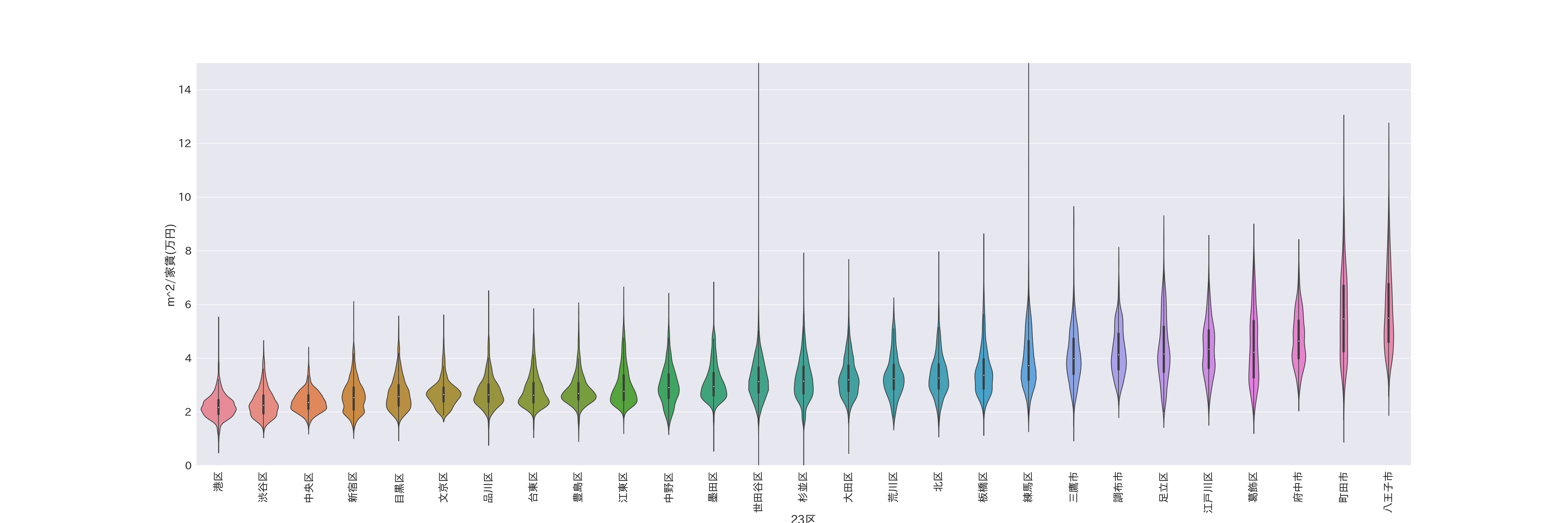
- 東京23区の一万円あたりで借りられる面積のバイオリン図
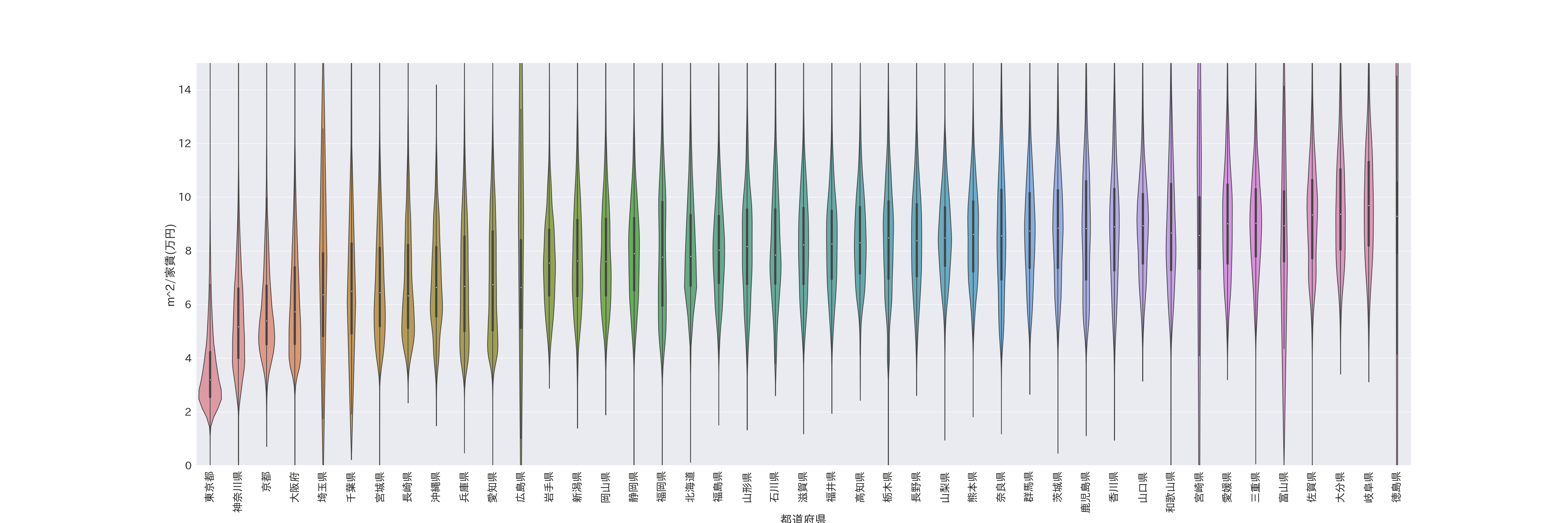
- 都道府県の一万円あたりで借りられる面積のバイオリン図
特徴量重要度
ElasticNetの特徴量の重要度で、重要度がプラス側に倒れるほど価格にプラスに影響する特徴量で、マイナスに倒れるほど価格にマイスに影響する特徴量になる。
- 東京の結果
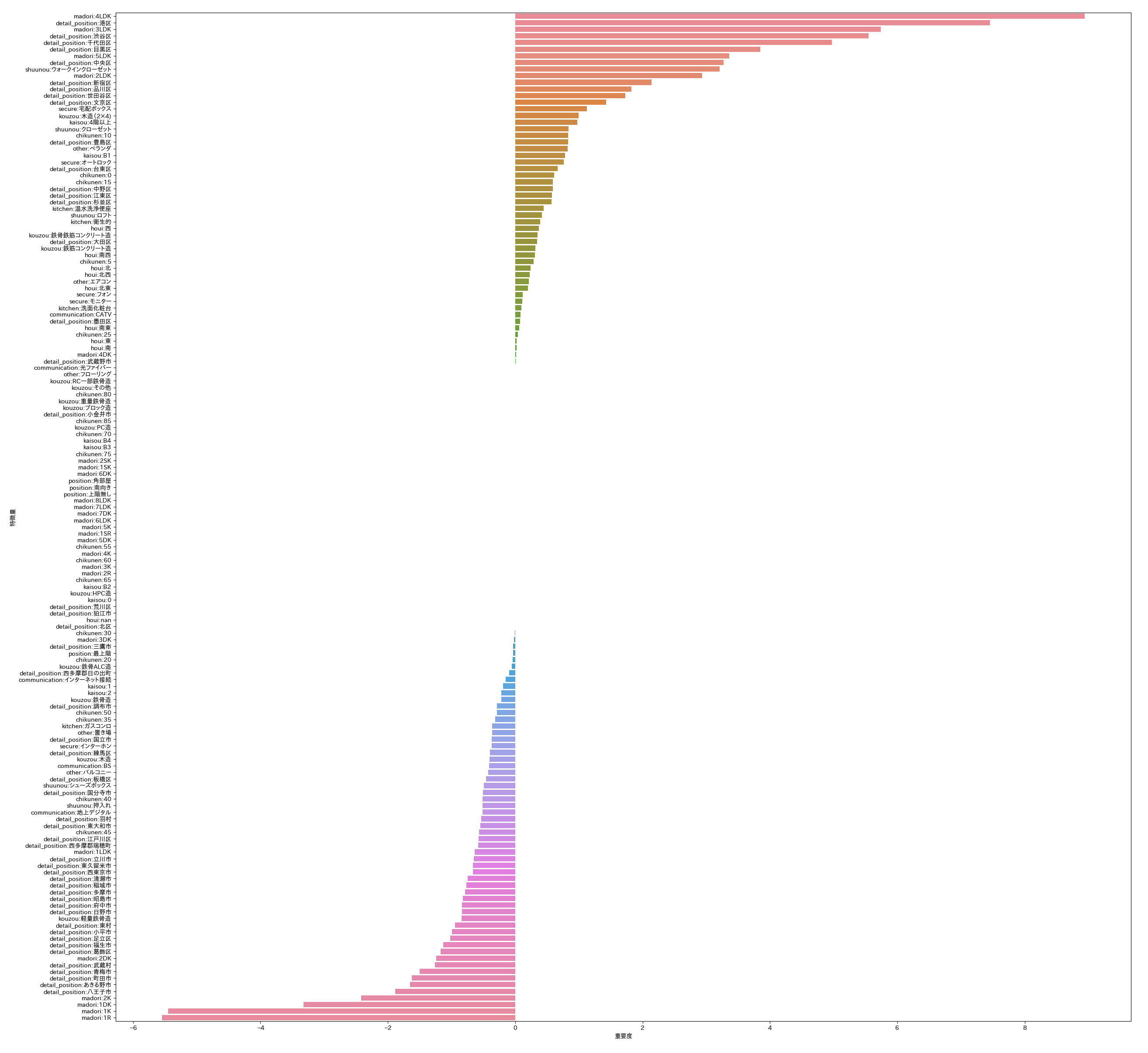
細かいので拡大して閲覧してください
- 全国の結果
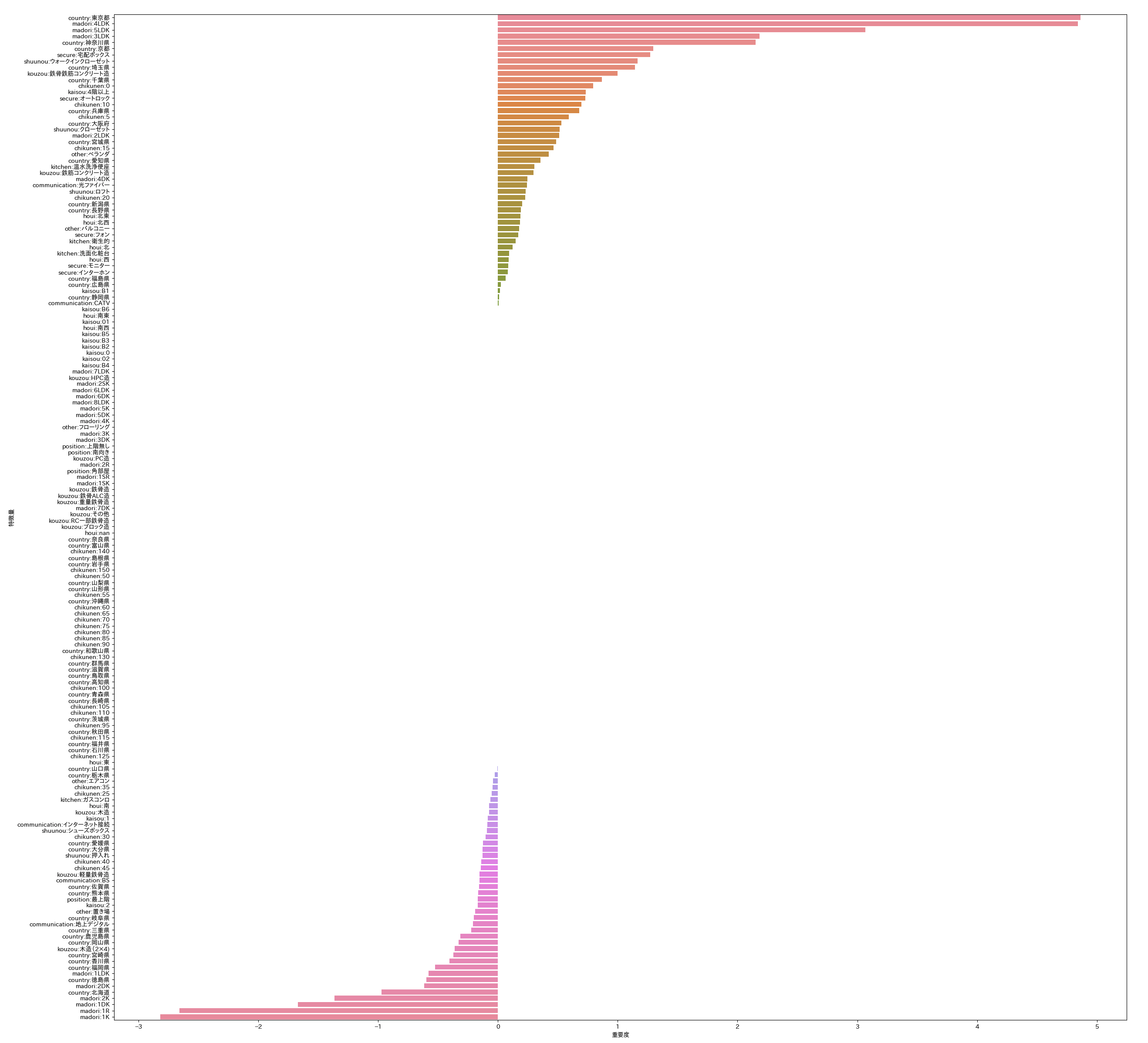 細かいので拡大して閲覧してください
細かいので拡大して閲覧してください
Chrome Extentionのユースケース
なれないJavaScriptを書いて作ったものになります。
このGitHubのコードをもとに作成しました。
"ネットで賃貸"さまのデータから、"Homes"さまの東京の詳細情報を評価できるChrome Extentionを作ってみました。


JSわからないなりに頑張った…
- 価格差が大きいとはなにかあるのでは無いかを考えられる
当然ながら、事故物件であるようなフラグは存在しないので、今回のモデルは特徴量として獲得していない。 例えば、異常に安い物件があるのならば、なにかそれを説明する変数(事故など)が背景にあると考える一助になる。
今回のモデルがあれば相場がわからない人がぼったくられるようなことを防ぐようなことも、インターフェースを整理すれば可能になるだろう。
コード説明
- A001_parse_htmls.py : chintai.netのhtmlのパース、データは上記のDropboxよりダウンロード
- B001_lexical_parse_json.py : ヒューリスティックにタグを解析してパースする
- C001_analysis_country_agg.py : バイオリンプロットの可視化
- E001_encoding_all_country_csv.py : 全都道府県の粒度でワンホットエンコーディング
- E001_encoding_tokyo_csv.py : 23区の粒度でワンホットエンコーディング
- F001_train.py : 学習
- chrome-ex-template/src : クローム拡張の本体
Excelの光と影 ~Excelデータ分析を超えていけ~
Excelは便利なソフトで、あらゆる企業で使われている表計算ソフトウェアですが、国内ではその役割が拡張されドキュメント作成的な意味もあります。
まともな使い方としてのExcelもあり、分析してと渡されることが多いフォーマットでもあります。
私自身のいくつか経験した案件を踏まえ、Excelとその周辺文化がデータ分析の妨げになっているという感想を持っていて、可能な限り、客観的に示していこうと思います。
Excelの功罪
一般的にExcelについてそのメリットやデメリットが語られる際、どのようなことが言われるのでしょうか。
おそらくデータに携わる人では、このような共通認識があるかと思います。
良い点
- 小さいデータから完結に何かを述べるときに便利
- グラフが簡単にかけて、可視化する際に便利
- プログラミングなど複雑なことがわからなくても大丈夫
悪い点
- セル結合はデータがパースが難しいかできない
- 人間が手入力してもそれなりに仕事になるので、データソース源として考えたとき、大量のデータを保存する文化が育たない
- カラムが揺らぐなどでパースと結合が難しい
各分析経験から、うまく行ったもの、うまく行かなったものの例示
Excelに対する思い込みや見落としがある可能性があるので、このような思いがどうして導かれたか明らかにする必要があります。
具体的な仕事での案件を通じ、公開して問題ない程度に抽象化して、どのような経験があったかを述べて抽象化していて特徴を明らかにします。
うまく行かなかった分析
1 公共法人の人口減少原因の分析
- 概要:各市町村がホームページで出しているデータから、年代、職業、学校、病院等の公共施設の充実度等から、人口減少を説明するモデルを構築し、その重要度を見る
- データ:各市町村が提出しているExcel, PDF, CSVの混在データ[1-3]
- 問題点:各市町村でHPのフォーマットと出力形式が一定していなくExcel, PDF, CSVが混在している。データを提供するという文脈を、分析してアグリゲートして結論だけを述べたものを提供している。そのため、日本の市町村を横断してそれなりのデータ量にして、分析者によらず客観性がある程度担保される定量分析にならず、分析者のドメイン知識を大量に投入してそれなりの説明力を出す定性的で属人化するモデルになりがち。
- 最終的な出力:人口の増減を2値分類して、特徴量の分布からそれなりに説明が付く定性的な文脈を作成(職を安定させることと、若者を増やすような施策を打つことが人口増加戦略の基本であるという結論になったが、データが少ないため数字の頑健性が少なく、もっと特徴量を調べたかった)
2 CRMとExcelから企業分析をする
- 概要:売上のデータから、経営で気をつけるべきインサイトを明らかにし、投資する点として美味しいポイントなどを発見する
- データ:CRMとExcel
- 問題点:CRMが古くデータ構造が入力者にとって自由に拡張されている & 入力にサニタイズの処理が入っておらず、自由に好きなテキストで入力できる形式になってしまっている。CRMで補完できない部分をExcelでカバーするという発想であり、データ分析を最終的にリーチさせるという視点がなかった。
- 最終的な出力:データを機会学習に掛ける前の段階で大いにつまずく、これはカラム名が不安定であったり、一定のルールでカテゴリ変数に対応する自由入力フィールドがサニタイズできないため、データボリュームを稼ぐことが難しく、アウトプットに数字的な頑健性が与えられなかった
3 イベント等の分析
- 概要:コンサートやライブなどのイベントの席は有限である。満員までよく埋まるが、潜在客はどの程度あり、ライブ会場をより広い会場にすると収益が最大化するのか知りたい
- データ:Excel
- 問題点:Excelでなんからの分析結果を示した内容であり、データがアグリゲートされており、情報が少なく、別の結論を導くのは難しい。カラムがかなり揺らいでおり、データを束ねて定量解析するという視点に向いていない(人力サニタイズしかない)。人間が手でデータを入力するため、間違いが結構ある(私も人力で修正して人力で突合するのでデータ誤差がどんどん累積する)
- 最終的な出力:ロジック的にはおそらく行けるというものを大量に投入したが、どうにも納得感のある数字にならず、インサイトとしては弱かった。
うまく行った分析
1 Hadoopに蓄積されたユーザ情報からインサイトを明らかにする
- 概要:とある企業のサービスの行動ログからHadoopに蓄積されたデータから何らかのインサイトを得る
- データ:広告を配信したユーザの行動をトラックして、ユーザの行動を明らかにして、別サービスとのレコメンデーションにしたり、サービス同士のユーザの流出などを見たりする(最近流行りのCookieを許可してくださいとかの走り)
- うまく行った要因:今はBigQueryがあるけど、当時のビッグデータ基盤はHadoop的なものが主流で大量の生データが保存されていた。サービスを横断して分析を行いインサイトを得る
- 最終的な出力:サービス横断施策のインサイト
2 SNSから各種KPIを予想する
- 概要:その時の時代の流行りの語と各種KPIから因果推論のサポートを行う
- データ:テキストとBigQueryにはいったKPI情報
- うまく行った要因:情報量が多く、機械的なデータであったので、擬似相関を一部をシステムで、残りを人間の方で吸収するという視点にたてば、時代背景やその時の流行りと関連性をある程度明確にすることができた
- 最終的な出力:あるKPIがある時、そのKPIはSNSのどのバズワードによって引き起こされたか可能性があるのかを網羅的に提示することができた(ロジックは良かったものの政治的要因とうネガティブな要素は今回は見ていない)
3 イベント等の分析(仕切り直しバージョン)
- 概要:コンサートやライブなどのイベントの席は有限である。満員までよく埋まるが、潜在客はどの程度あり、ライブ会場をより広い会場にすると収益が最大化するのか知りたい
- データ:Apache Log
- うまく行った要因:うまく行かなかったものを仕切り直したバージョン。データソースをExcelから、Apache Logに変更した。情報源としての誤りが少ないのと、情報量自体が多かった。
- 最終的な出力:数字的に納得感があり、分析として意味のあるものになった
ここからうまく行かなった理由を分析する
共通項1 : パースしにくいExcelなどをデータソースとすると、うまくいかない
共通項2 : 生の非構造化データや構造化データを問わず、ビッグデータと呼ばれるほどデータが多いとうまくいく
共通項3 : 何らかのビジネス的なKPIを報告する目的で、アグリゲートされた分析結果を再度利用するものはうまくいかない
さらに整理して図示するとこの様になります。

Excelでカラム名が揺らいでしまう + パースが難しい一般例(共通項1の深掘り)
奥村さんの有名な神エクルの問題[5]でも述べらているとおり、Excelでデータを貰ってもそれを分解して定量分析するには、Excelの自由な入力形式故に機械的にパースすることが難しく、データ量を稼ぐことが難しくなってきます。
データのボリュームを多くすれば、気づきにくい特徴であっても何かしら発見を行うことができ、ビジネス的にも有意義です。
カラムのゆらぎ

図1. 入力する人間の使う語で入力されるためカラム名がゆらぎがち
カラムが可変長レコード

図2. 機械的にパースすることができるが、使い捨てのちゃんとしたコードをたくさん書く必要がある
正規化されたレコードが結合できない

図3. 要素名が揺らいでいたりして突合できない
より一般化したデータの不可逆性と情報量の関係(共通項2, 3の深掘り)
Excelで報告書をもとに分析してと言われることが多いのですが、報告書自体が何らかのデータをアグリゲートしたものであり、そこから別の角度で何かを発見するのが難しいのかを、情報の不可逆性と、情報量の関係から示します。

図4. よくある熱の不可逆性
”仕切りを開ける”という操作を行うと、2つの分子運動は混じり合って、もとに戻せなくなります。
例えば、データ分析の文脈では、”仕切を開ける”という操作ではないですが、もとに戻せなくなる操作があります。
例えば中学校のテストのデータをもとになにかの操作を行ったとすると、もとに戻せなくなることが自明であるかと思います

図5. meanの操作を行った結果だけから、もとのデータを戻すことができない
この操作は多くのアグリゲート関数について成り立ち、sum, min, max, mean, mode, mediunなど、単射である処理について成り立ちます。
情報量を下げる操作が多くの報告書では行われている
情報量の観点から具体的に高校の進学率の例で導いていきます

図6. 少しずつデータが要約される
この結果から何らかのアグリゲートされた値からは、不可逆性があり、かつ情報量が減少しています。
情報量が下がるということはどういうことかというと、情報の曖昧さが少ないということですが、上記の平均の例では、それ部活動や都道府県の情報を捨ててスコープを絞ることで、情報量を下げています。
意思決定層に見せるデータは完結でごちゃごちゃしてはいけないので、シンプルになっている事がほとんどです。そこから、もとのデータの分布がどうなっていたのかは復元が基本的には不可能なので、別の結論を導くことが難しい事がわかるかと思います。
Excel分析で詰まったときに使える銀の弾丸
ソフトウェア工学で、銀の弾丸は存在しないという表現[5]で、万能の解決策は存在しないというものがあります。
個人の経験では、あるアプローチが取れる場合、案件が失敗したことがないようなソリューションがあります(個人だけの経験に限れば100%の解決力である)
その方法は、構造化されているいないに拘わらず「できるだけ分析対象の元情報に近いデータを取得する」です。
どういうことかというと、何かしらデータが出来上がっている背景には、もとのデータが存在するはずで、そこを参照すればいいということが大いにあります。

図7. 大体、最初は下の方のデータを渡されるので、データの源流をたどり、上に持っていく
何かしら集計の途中で意図してか意図しないでかデータ整形のプロセスのなかでクリティカルな特徴が消えてしまったり、あまりやってほしくないアグリゲーションが行われて出したいデータが出せなかったりしていることが多々あります。
そんなとき、データの源流を探す旅にでるのは有意義で、クライアントがそもそも気づいていなかった新たな事実の発見や、なんとなく感覚でしかわからなかった事実を定量的に表すことが可能になり、ビジネス的にもデータ分析的にも大変有効です。
参考文献
- [1] 宇都宮市データバンク
- [2] OpenData那須
- [3] 日光市のデータ
- [4] 情報量
- [5] 銀の弾丸