教師なし画像のベクトル化と、ベクトルからタグを予想したり類似度を計算したりする
教師なし画像のベクトル化と、ベクトルからタグを予想したり類似度を計算したりする
はじめに
ISAI2017でPCAnetと呼ばれる、教師なし画像の特徴量の抽出方法が紹介されていました
味深い実装になっており、CNNをバックプロパゲーションで結合の太さを学習していくのではなく、予めフィルタを組み込んでおき、使うことで、高い精度を達成しているようです[1]
これを見ていて、AutoEncoderでも同等のことができるのではないかと思いました
AutoEncoderでは、ディープラーニング学習する必要がありますが、やはり、教師データは必要ないです。画像だけあれば良いです。
AutoEncoder

図1. Auto Encoderの図
GANに似ています。GANはこの、図のDecoderを入力との直接の誤差の最小化ではなく、判別機を騙すことで達成しますが、今回はもとの情報が近い方が良いと思ったので、AutoEncodeを利用しました
画像の特徴量をVAEで取り出す方法もあり、僅かにヒントを与えることと出力を工夫することで、より高精度ので分布が取り出せる方法も各種提案されています[2]
余談ですが、単純な、画像生成という視点では、GANに比べて彩度や繊細さがダメっぽくて、画像生成としては色々工夫が必要だなと思いました。
Encoderから特徴量を取り出す
Encoderから任意の次元に圧縮した特徴量を取り出すことができる

図2. Encoderによる特徴量の取り出し
このベクトルは200次元(配列の長さだと、v.size == 200程度)であり、これからディープラーニングは元の画像に近い画像を復旧できたということは、何らか画像を説明する、重要な特徴量がつまっていると考えられます。
このベクトルをVとすると、なんらかのディープラーニング以前のSVMなどのアルゴリズムで機械学習ができそうではあります
また、XGBoostの登場と、DeepLearningの流行りが同時期であったので、これらが得意とする分野が重ならず、併用する文化があまりなかったので、DeepLearningとXGBoostのコンビネーションをやってみようと思いました。
ディープラーニングの現実的な制約とその解決
画像から、属性を予想するプログラムは過去、何回か書かせていただきました。
最初からわかる問題としては、DeepLearning単体ではタグ情報が固定長までしか対応する事ができず、ネットワークを巨大にしても4000次元の出力で、オンライン学習が難しい(新たにタグが発生したときに学習が難しい)などのデメリットがあります
これらを解決する手段としてAutoEncoder, Variable AutoEncoderなどが使える次第です
画像そのもの情報がベクトル化されるので、これらの情報からXGBoostなどに繋げば、新しいタグが発生した祭などに、容易に学習ができます
AutoEncoderのモデル
学習用のコードはgithubにあります
Kerasで書きました。わかりやすいことは一つの正義ではあります。もちろん微細な制御ができるChainerなども正義です
用途と目的によって使い分ければいいかなって思います
input_img = Input(shape=(28*BY, 28*BY, 3)) # adapt this if using `channels_first` image data format x = Conv2D(64, (3, 3), activation='relu', padding='same')(input_img) x = Conv2D(64, (3, 3), activation='relu', padding='same')(x) x = MaxPooling2D((2, 2), padding='same')(x) x = Conv2D(128, (3, 3), activation='relu', padding='same')(x) x = Conv2D(128, (3, 3), activation='relu', padding='same')(x) x = MaxPooling2D((2, 2), padding='same')(x) x = Conv2D(256, (3, 3), activation='relu' , padding='same')(x) x = Conv2D(256, (3, 3), activation='relu' , padding='same')(x) x = BN()(x) x = MaxPooling2D((2, 2), padding='same')(x) x = Conv2D(512, (3, 3), activation='relu' , padding='same')(x) x = Conv2D(512, (3, 3), activation='relu' , padding='same')(x) x = Conv2D(512, (3, 3), activation='relu' , padding='same')(x) x = BN()(x) x = MaxPooling2D((2, 2), padding='same')(x) x = Flatten()(x) z_mean = Dense(196)(x) encoder = Model(input_img, z_mean) """ dec network """ dec_0 = Reshape((7,7,4)) dec_1 = Conv2D(32, (3, 3), padding='same') dec_2 = LeakyReLU(0.2, name="leaky_d1") dec_3 = UpSampling2D((2, 2)) dec_4 = Conv2D(64, (3, 3), padding='same') dec_5 = LeakyReLU(0.2) dec_6 = UpSampling2D((2, 2)) dec_7 = Conv2D(128, (3, 3), padding='same') dec_8 = LeakyReLU(0.2) dec_9 = UpSampling2D((2, 2)) dec_10 = Conv2D(128, (2, 2), padding='same') dec_11 = BN() dec_12 = LeakyReLU(0.2, name="leaky_d5") dec_13 = UpSampling2D((2, 2)) dec_14 = Conv2D(3, (2, 2), padding='same') dec_15 = LeakyReLU(0.2, name="leaky_d6")
実験に用いるデータセット
Pixiv社のデータを利用させていただきました
400万件を取得し、そのうち、200万件をAutoEncoderの学習に用いました。
残り200万件をAutoEncoderのEncoderに通すことで、タイトルとベクトルとその画像のタグ状を取得します
データ構造的には以下のようになります
title1 -> ([v1, v2, ...], [Tag1, Tag2, ...]), title2 -> ([v1, v2, ...], [Tag1, Tag2, ...]), ...
XGBoostの設定
何のタグが付くかの確率値を出したいという思惑があるので、binary, logisticを使います その他の詳細な設定は、以下の通りです
param = {'max_depth':1000, 'eta':0.025, 'silent':1, 'objective':'binary:logistic' }
num_round = 300
これを、すべてのタグに対して予想します タグの種類は30000を超えており、つまり、タグ一つに対して一つモデルを作るので、30000個ものモデルができます このようにいくらでもスケールできることが強みになますね
実験
AutoEncoderのチューニングにはGTX1080にギリギリ入るモデルが必要でした(やはりでかいモデルのほうが性能がいい) 比べて、後半のタスクであるXGBoostでの学習は、CPUです。Ryzen16コアを2つ持っているのですが、持ってなかったら死んでた…
- Pixivのイメージ200万枚を112x112にリサイズして、AutoEncoderで学習
- Encoderのみを取り出し、200万枚をベクトル化
- タグをXGBoostで学習
- 任意の入力の画像に対して、適切にタグが付与されるか
結果
学習に用いてないデータでの検証を行いました 予想できるタグは30000種類を超えており、多様性の視点では既存のDeepLearningを超えているかと思います

図3. 入力画像と予想出力値(下のタグの画像が真)
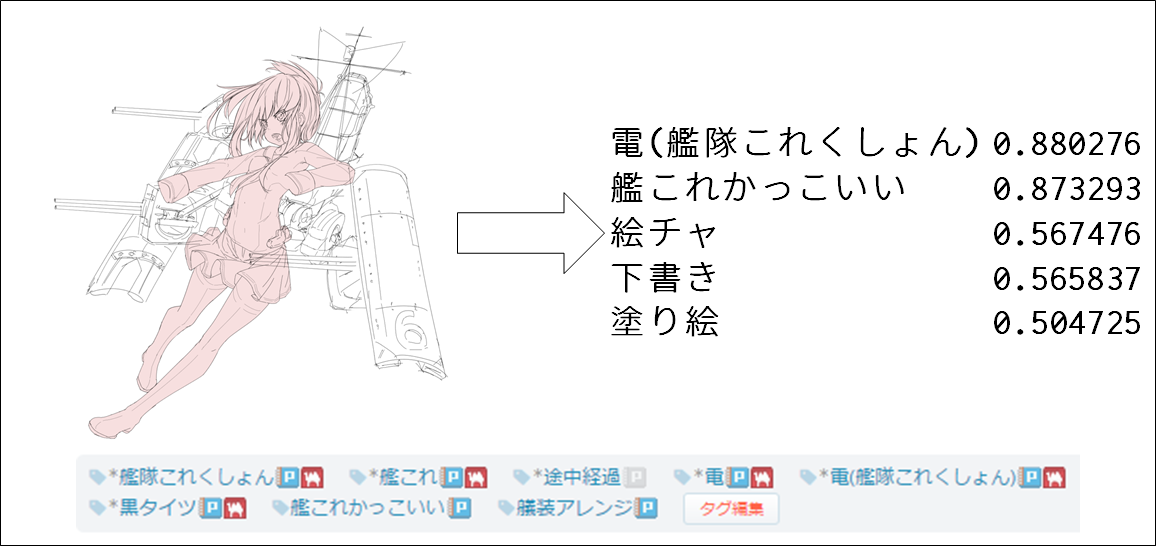
図4. 入力画像と予想出力値(下のタグの画像が真)

図5. 入力画像と予想出力値(下のタグの画像が真, 人物は間違った)
ある程度予想していたのですが、やはり、キャラクターの特定は、Pixiv社のタグの数の個数制限があり、なかなか難しかったです
そのかわり強いなって思ったのが、夜空・星空・下絵・海・ハートなど、全体の世界観などモヤッとしたものをつかむがうまかったです
Appendix.類似度
なお、このAutoEncoderの情報をうまく使えば、画像の類似度検索にも用いることができます 200次元程度なので、ある程度、意味のある類似度検索をすることができ、cosine類似度や、ユークリッド距離を図ったりしていたが どちらも、同等のパフォーマンスで、ランキングに大きな変動がなかったため、計算が早いユークリッドを用いました

図6. 一番上が検索クエリで、2,3番めが検索結果
illustration2vecと同様に、画像自体を検索クエリとすることができます 高速なマッチングも幾つか考案しましたが、余裕があるときにまたご紹介したいと思います
コード
AE. VAEは基礎的な特徴の研究から初めて、なんとか、いろいろ引き上げて使えるようにした感じです
keras-tiny-vaeがオートエンコーダ系で、特にこのPixivのタスクに限定したものではないコードですが、AE, VAEで特徴量を取り出します
PixivTagPredictorがタグを学習・予想するXGBoostのプログラムです