pytorch-pix2pix
一年ほどまえ、pix2pix系のネットワークを編集して色々おもしろいことができると言うことを示しました。当時はブログ等に何かポストする際に再現可能なコードを添付することを諸事情により十分にできなかったのですが、pytorchに元論文の実装に近いImage to Imageが登場し、かなり強力で表現力の高いネットワークであったので、いくつか再現性とデータセットを再び添付して公開したいと思います
- 白黒画像に色をつける
- 不完全な欠損した画像を復元する
- フォントのスタイル変換
Image-to-Imageのネットワークと論文とその実装系のForkのForkになります。
素晴らしい編集力と、コードの一般化を行った方々に感謝を申し上げます
A fork of PyTorch implementation of Image-to-Image Translation Using Conditional Adversarial Networks.
Based on pix2pix by Isola et al.
Update
Image to Imageの初版は2016年12月時点の論文ですが、2017年12月にもarXivにversion2が投稿されています。
学習が安定しているかつ、複雑なネットワークにも対応していて、U-netと論文中では言われていますが、コード中ではResisual Blockなどと表現されており、入力情報を忘れないように細工をする仕組みが十分に入っていることがあるようです(経験的にこのネットワークはコンピュータリソースが十分にあれば巨大なネットワークでも学習できます)

目的関数の設計については古典的な普通の表現を古典的な距離とGANでの距離のハイブリッドになっていて、古典距離はブラー(画像のボケ)を防ぐ効果が期待できます
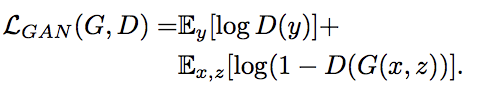
GANの距離と
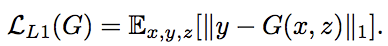
古典的な距離を
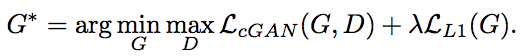
くっつけます
End2Endでラベルを用いるような学習をかなり色々試行錯誤しましたが、もう限界に達しているとも思い、これからは、学習自体に何らか意味あるような学習が優位になっていく用に思います。
requirements
- Python3 with numpy
- cuda
- pytorch
- torchvision
Getting Started
git clone
$ git clone https://github.com/GINK03/pytorch-pix2pix $ cd pix2pix-pytorch
train dataset
$ python3 train.py --dataset facades --nEpochs 100 --cuda
train dataset
$ python3 test.py --dataset facades --model checkpoint/facades/netG_model_epoch_200.pth --cuda
Examples
白黒写真に色を付ける
夏+花のデータセットを用いて、学習します Download
$ wget https://www.dropbox.com/s/yhstjhqmsy1cneb/grayscale.zip $ mv grayscale.zip dataset $ cd dataset $ unzip grayscale.zip
train dataset
$ python3 train.py --dataset grayscale --nEpochs 100 --cuda
predict dataset
$ python3 test.py --dataset grayscale --model checkpoint/grayscale/netG_model_epoch_100.pth --cuda
example output

ノイズや欠落情報を復元する
"自然"のデータセットに対して、ノイズを乗せて復元を試みます Download
$ wget https://www.dropbox.com/s/1yvr560s24sliay/random_drop.zip $ mv random_drop.zip dataset $ cd dataset $ unzip random_drop.zip
train dataset
$ python3 train.py --dataset random_drop --nEpochs 50 --cuda
predict dataset
$ python3 test.py --dataset random_drop --model checkpoint/random_drop/netG_model_epoch_50.pth --cuda
example output

フォントのスタイルの変換を行う
人間が習字で書いたデータセットに対して、Takao Fontと対応させて、新規フォントを作るという発想です
Download
$ wget https://www.dropbox.com/s/owee6hxopnr4dpo/font.zip $ mv font.zip dataset $ cd dataset $ unzip font.zip
train dataset
$ python3 train.py --dataset font --nEpochs 150 --cuda
predict dataset
$ python3 test.py --dataset font --model checkpoint/font/netG_model_epoch_150.pth --cuda
example output

コード
ご自由にご利用ください


















