テーブルデータに対して、DenosingAutoEncoderで精度向上
データセットの問題
Kaggle Porto Seguroでは問題となっている点があって、テストデータとトレインデータのサイズの方が大きく、トレインだけに着目してしまうと、LeaderBoardにoverfitしてしまう問題があります。
これはトレインだけで学習するために起こる問題で、テストデータ・セットを有意義に使う方法として、教師なし学習でまずは次元変換やなんやらを行うという方法が有効なようです。
ディープを用いることでいくつか有益な変換操作を行うことができて、「すべての情報は何らかのノイズを受けている」という視点に立ったときに、恣意的にAutoEncoderの入力にノイズを乗せ、それを除去するように学習するとはっきりと、物事が観測できるようになったりするという特徴を利用しています。

図1. よくある画像の例
画像の利用からテーブルデータの利用に変換する操作を行います。
このテーブルデータに対して適応するという発想と用途はあまり見たことがなかったので、有益でした。(画像にノイズがかかっていますが実際は値に対してかかります)

図2. テーブルデータのノイズを除去
MichaelさんのとったDAE(DenosingAutoEncoder)の特徴
noiseを掛ける方法
swap noiseという方法を用います。これは、uniformやgaussian noiseをこれらに和算や積算などで、かけても適切ではないという点を抱えているため、いくつかのハッキーな方法が取られています。
swap noiseはランダムに10%程度の確率で、"同じ列"で"他の行"と入れ替える技で、これによりノイズを掛けます。
これをすべての要素にたいして適応するすると、割と現実的なnoisingになるそうです。

図3. swap noise
numpyのアレイをコピーしてすべての要素を操作していって、 10%の確率で"同じ列"、"別の行"と入れ替えます
import numpy as np import random from numba.decorators import jit @jit def noise(array): print('now noising') height = len(array) width = len(array[0]) print('start rand') rands = np.random.uniform(0, 1, (height, width) ) print('finish rand') copy = np.copy(array) for h in range(height): for w in range(width): if rands[h, w] <= 0.10: swap_target_h = random.randint(0,h) copy[h, w] = array[swap_target_h, w] print('finish noising') return copy
rank gauss
Rank Gaussという連続値を特定の範囲の閉域に押し込めて、分布の偏りを解消する方法です。
これも彼の言葉を頼りに実装しました。
このようなコードになるかとおもいます。
import pandas as pd tdf = pd.read_csv('../input/train.csv') Tdf = pd.read_csv('../input/test.csv') df = pd.concat([tdf, Tdf], axis=0) print(df.head()) # catが最後につくとカテゴリ # binがつくとワンホット # 何もつかないと、連続値 from scipy.special import erfinv import re ## to_rank for c in df.columns: if c in ['id', 'target'] or re.search(r'cat$', c) or 'bin' in c: continue series = df[c].rank() M = series.max() m = series.min() print(c, m, len(series), len(set(df[c].tolist()))) series = (series-m)/(M-m) series = series - series.mean() series = series.apply(erfinv) df[c] = series df.to_csv('vars/rank_gauss_all.csv', index=None)
流れとしては、まずランクを計算し、[0, 1]に押し込めて、平均を計算し、(-0.5,0.5)に変換します。
これに対してerfiv関数をかけると、ランクの方よりが正規分布のような形変換することができます。
DAEパラメータ

図4. michaelさんが調整したパラメータ
このように、何種類かのDenosing AutoEncoderをアンサンブルして、Dropoutなどを充分につかって、結果をLinear Brend(線形アルゴリズムでアンサンブル)するそうです
chainerで作成した学習コード
長くなりますので、全体参照には、githubを参照してください。
from chainer import training from chainer.training import extensions import numpy as np import cupy as xp from chainer import report from chainer import Variable from sklearn.metrics import mean_squared_error # Network definition class MLP(chainer.Chain): def __init__(self): super(MLP, self).__init__() with self.init_scope(): self.l1 = L.Linear(None, 1500) # n_in -> n_units self.l2 = L.Linear(None, 1500) # n_units -> n_units self.l3 = L.Linear(None, 1500) # n_units -> n_units self.l4 = L.Linear(None, 227) # n_units -> n_out def __call__(self, h): h1 = F.relu(self.l1(h)) h2 = F.relu(self.l2(h1)) h3 = F.relu(self.l3(h2)) if is_predict: return np.hstack([h1.data, h2.data, h3.data]) h4 = self.l4(h3) return h4
学習部分
if '--train' in sys.argv: df = pd.read_csv('vars/one_hot_all.csv') df = df.set_index('id') df = df.drop(['target'], axis=1) EPOCHS = 2 DECAY = 0.995 BATCH_SIZE = 128 INIT_LR = 3 #0.003 model = L.Classifier(MLP(), lossfun=F.mean_squared_error) OPTIMIZER = chainer.optimizers.SGD(lr=INIT_LR) OPTIMIZER.setup(model) for cycle in range(300): noise = swap_noise.noise(df.values).astype(np.float32) train = TupleDataset(noise, df.values.astype(np.float32)) test = TupleDataset(noise[-10000:].astype(np.float32), df[-10000:].values.astype(np.float32)) # iteration, which will be used by the PrintReport extension below. model.compute_accuracy = False chainer.backends.cuda.get_device_from_id(1).use() model.to_gpu() # Copy the model to the GPU print(f'cycle {cycle-1:09d}') train_iter = chainer.iterators.SerialIterator(train , BATCH_SIZE, repeat=True) test_iter = chainer.iterators.SerialIterator(test, BATCH_SIZE, repeat=False, shuffle=False) updater = training.updaters.StandardUpdater(train_iter, OPTIMIZER, device=1) trainer = training.Trainer(updater, (EPOCHS, 'epoch'), out='outputs') trainer.extend(extensions.Evaluator(test_iter, model, device=1)) trainer.extend(extensions.dump_graph('main/loss')) frequency = EPOCHS trainer.extend(extensions.snapshot(), trigger=(frequency, 'epoch')) trainer.extend(extensions.LogReport()) trainer.extend(extensions.PrintReport( ['epoch', 'elapsed_time', 'main/loss', 'validation/main/loss'])) trainer.extend(extensions.ProgressBar()) def lr_drop(trainer): trainer.updater.get_optimizer('main').lr *= DECAY print('now learning rate', trainer.updater.get_optimizer('main').lr) def save_model(trainer): chainer.serializers.save_hdf5(f'snapshot_15000_model_h5', model) trainer.extend(lr_drop, trigger=(1, 'epoch')) trainer.extend(save_model, trigger=(10, 'epoch')) trainer.run() model.to_cpu() # Copy the model to the CPU mse1 = mean_squared_error( df[-10000:].values.astype(np.float32), model.predictor( noise[-10000:].astype(np.float32) ).data ) mse2 = mean_squared_error( df[-10000:].values.astype(np.float32), model.predictor( df[-10000:].values.astype(np.float32) ).data ) print('mse1', mse1) print('mse2', mse2) chainer.serializers.save_hdf5(f'model-sgd/model_{cycle:09d}_{mse1:0.09f}_{mse2:0.09f}.h5', model)
中間層の取り出し
データがそれなりに多いので、CPUで適当なサイズに切り出して予想します
npyファイル形式にチャンクされたファイルがダンプされます
if '--predict' in sys.argv: df = pd.read_csv('vars/one_hot_all.csv') df = df.set_index('id') df = df.drop(['target'], axis=1) model = L.Classifier(MLP(), lossfun=F.mean_squared_error) chainer.serializers.load_hdf5('models/model_000000199_0.007169580_0.001018013.h5', model) chainer.backends.cuda.get_device_from_id(0).use() model.to_cpu() # Copy the model to the CPU BATCH_SIZE = 512 print( df.values.shape ) height, width = df.values.shape is_predict = True args = [(k, split) for k, split in enumerate(np.split(df.values.astype(np.float32), list(range(0, height, 10000)) + [height] ))] for k, split in args: r = model.predictor( split ).data if r.shape[0] == 0: continue np.save(f'dumps/{k:04d}', r) print(r.shape)
結果
michaelさんのネットワークは5つのモデルのアンサンブルで、この個数を行うのは割と容易ではないです。
LightGBMにDAEのネットワークの活性化した値を入れると、精度向上をすることができまた。
LightGBMだけ
5-cv train auc 0.6250229489476413 5-cv train logloss 0.1528616157817217
DAE + LightGBM
※ Leaves, Depth, 正則化などのパラメータを再調整する必要があります
5-cv train auc 0.6403338821473902 5-cv train logloss 0.15185993565491557
注意
中間層を吐き出して、それをもとに再学習する操作が、想像以上にメモリを消耗するので、96GBのマシンと49GBのマシンの2つ必要でした。
軽い操作ではないです。
Deepあるあるだとは思うのですが、入れるデータによっても、解くべき問題によっても微妙にパラメータを調整する箇所が多く、膨大な試行錯誤が伴います。
プログラム
プロジェクト
rank-gauss.py
連続値や1hot表現をランクガウスに変換
swap_noise.py
テーブルデータを提案に従って、スワップノイズをかけます。
これは他のプログラムからライブラリとして利用されます。
dae_1500_sgd.py
OptimizerをSGDで学習するDAE(1500の全結合層)
dae_1500_adam.py
OptimizerをAdamで学習するDAE(1500の全結合層)
考察
テーブルデータも何らかの確率的な振る舞いをしていて、事象の例外などの影響を受けるとき、このときDenosing AutoEncoderでノイズを除去するように学習することにより一般的で、汎用的な表現に変換できるのかもしれません。かつ、ノイズロバストな値になっているので、これを用いることで精度に寄与するのはそんなに想像に難くないと思います。
しかし、理論的な裏付けや解析が十分に進んでいないのと、追試にものすごい試行錯誤と調整が必要でした。お勉強にはちょうどいいよね。
一度ちゃんと使えようにしておくと、テーブルデータから何かを予想する問題のときに、すぐ使えるので便利です(そして、実際に精度は上がります)
BigQueryでUDFとwindow関数を使う
bigqueryでUDFとwindow関数を使う
転職してからMapReduceそのもののサービスや改良したサービスであるCloud DataFlowなどのサービスより、初手BigQueryが用いられることが増えてきました。分析環境でのプラットフォームを何にするかの文化の違いでしょう。
BigQueryの優れた面がLegacy SQLを使っていたときは、なにもないのでは、と考えていたこともあったのですが、Standard SQLならばWindow関数を利用し、さらに非構造化データに対してもUser Define Functionをアドホックに用いることで、かなり良いところまで行けるということがわかりました。
window関数の例と、User Define Functionとの組み合わを記します。
bigqueryへのpandasからのアップロード
pandasでcsv等を読み取って、pandas-gbqを使うと、pandasの型情報のまま転送することができるので、この方法は体得しておくと便利です。
pandas-gbqのインストール
(AnacondaのPythonがインストールされているという前提で勧めます)
$ conda install pandas-gbq --channel conda-forge
サンプルデータセットとして、Kaggle Open Datasetのdata-science-for-goodという、ニューヨーク州の学校の情報のデータセットを利用します。
デーブルデータはこの様になっています。全部は写っていなく、一部になります。

import pandas as pd pd.set_option("display.max_columns", 120) df = pd.read_csv('./2016 School Explorer.csv') # BigQueryはカラム名がアンダーバーと半角英数字以外認めないので、その他を消します def replacer(c): for r in [' ', '?', '(', ')','/','%', '-']: c = c.replace(r, '') return c df.columns = [replacer(c) for c in df.columns] # BigQueryへアップロード df.to_gbq('test.test2', 'gcp-project')

図1. GCPのBigQueryにテーブルが表示されることを確認
Window関数
SQLは2011年から2014年まで某データウェアハウスのレガシーSQLを使っていた関係で、マジ、MapReduceより何もできなくてダメみたいなことをしばらく思っていたのですが、Standart SQLを一通り触って強い(確信)といたりました。
具体的には、様々な操作を行うときに、ビューや一時テーブルを作りまくる必要があったのですが、window関数を用いると、そのようなものが必要なくなってきます。
Syntaxはこのようなになり、data-science-for-goodのデータセットを街粒度で分割し、白人率でソートして、ランキングするとこのようなクエリになります。
RANK() OVER(partition by city order by PercentWhite desc)
より一般化すると、このようなもになります。

図2.
これは、pandasで書くとこのような意味です。
def ranker(df): df = df.sort_values('PercentWhite', ascending=False) df['rank'] = np.arange(len(df)) + 1 return df df.groupby(by=['City']).apply(ranker)[['City', 'PercentWhite','rank']].head(200)
BigQueryのwindow関数もpandasのgroupby.applyも似たようなフローになっています。

図3. 処理フロー
処理フローとしてはこの様になっています。BigQueryはPandasに比べて圧倒的に早いらしいので、ビッグデータになるにつれて、優位性が活かせそうです。
なお、window関数は他にもさまざまな機能があり、GCPの公式ドキュメントが最も整理されており、便利です。
toy problem: ニューヨーク州の街毎の白人率の大きさランキング
select SchoolName , RANK() over(partition by city order by PercentWhite desc) , city , PercentWhite from test.test ;
出力

図4. window+rank関数によるランキング
Standerd SQLでUDF(UserDefinedFunction)を定義する
前項ではBigQueryに組み込み関数のRANK関数を用いましたが、これを含め、自身で関数をJavaScriptで定義可能です。
JavaScriptで記述するという制約さえ除けば、かなり万能に近い書き方も可能になりますので、こんな不思議なことを計算することもできます。(おそらく、もっと効率の良い方法があると思いますが)
window関数で特定の値のノーマライズを行う
白人のパーセンテージをその街で最大にしめる大きさを1としてノーマライズします。
UDFはCREATE TEMPORARY FUNCTIONで入出力の値と型決めて、このように書きます
CREATE TEMPORARY FUNCTION norm(xs ARRAY<STRING>, rank INT64) RETURNS FLOAT64 LANGUAGE js AS """ const xs2 = xs.map( x => x.replace("%", "") ).map( x => parseFloat(x) ) const max = Math.max.apply(null, xs2) const xs3 = xs2.map( x => x/max ).map( x => x.toString() ) return xs3[rank-1]; """; select SchoolName ,norm( ARRAY_AGG(PercentWhite) over(partition by city order by PercentWhite desc) , Rank() over(partition by city order by PercentWhite desc) ) ,city , PercentWhite from test.test ;
計算結果をみると、正しく、計算できていることがわかります。

図5. UDFによる任意の計算が可能
lag関数を使わずに前のrowの値との差を計算する
学校の街ごとの収入に、自分よりも前のrowとの収入の差を求める。
lag関数でも簡単に求めることができますが、JSの力とrow_number関数を使うことでこのようにして、rowベースの操作すらもできます。
#standardSQL CREATE TEMPORARY FUNCTION prev(xs ARRAY<STRING>, index INT64) RETURNS FLOAT64 LANGUAGE js AS """ const xs1 = xs.map( function(x) { if( x == null ) return "0"; else return x; }); const xs2 = xs1.map( x => x.replace(",", "") ).map( x => x.replace("$", "") ).map( x => parseFloat(x) ); const ret = xs2[index-1-1] - xs2[index-1]; if( ret == null || isNaN(ret)) return 0.0; else return ret """; select SchoolName ,prev( ARRAY_AGG(SchoolIncomeEstimate) over(partition by city order by SchoolIncomeEstimate desc) , row_number() over(partition by city order by SchoolIncomeEstimate desc) ) ,city ,SchoolIncomeEstimate from test.test;

図6. 前のrowとの差を計算する
このように列だけでな行方向にも拡張された操作ができ、万能とはこういう事を言うんでしょうか
なかなかレガシーSQLでは難しかった操作ができる
window関数を用いることで、アグリゲートをする際、groupbyしてからビューを作りjoinをするというプロセスから解放されました。
MapReduceを扱う際のモチベーションが、膨大なデータをHash関数で写像空間にエンベッティングして、シャーディングするという基本的な仕組みを理解していたので、どのようなケースにも応用しやすく、使っていました。

図7. BigQuery(Dremel)とMapReduceの比較
MapReduceに比べて、BigQueryはcomplex data processing(プログラミング等でアドホックな処理など)を行うことができないとされていますが、User Deine Functionを用いればJavaScriptでの表現に限定されますが行うことができます。
outer source
codes
SQLの実行の仕方はコマンドでやるとき、こうするとめっちゃ便利です
$ bq query "$(cat bq-window-lag.sql)"
K8Sで機械学習の予想システムを作成
K8Sで機械学習の予想システムを作成
目次
- 機械学習の最小粒度としてのDocker, Dockerのデプロイ先としてのk8s
- テキストを評価するAPIのDockerコンテナの作り方
- DockerコンテナのGoogle Cloud Container Registryへの登録
- K8Sへのデプロイ
- 実際にアクセスする
- まとめ
機械学習の最小粒度としてのDocker, Dockerのデプロイ先としてのk8s
コンテナのオーケストレーションツールがk8sが他のツールを押しのけて、優位にたった状況からしばらく経過し、ドキュメントやユースケースが揃ってきました。
GCPではコンテナを使ったデプロイメントサービスはKubernetes Engineがデフォルトであり、WebUIやCUIでの操作例を示したドキュメントも充実してきました。
k8sは、ローリングリリースが簡単にできたり、分析者からDocker Fileやコンテナが適切に受け渡しが開発者に行われれば、デプロイまでの時間的労力的消耗を最小化できたりします。
また、Micro Serviceのデザインパターンとして、Dockerが一つの管理粒度になり、そこだけで閉じてしまえば、自分の責任範囲を明確にし、役割が明確になり、「分析 -> モデルの評価&作成 -> IFの定義 -> コード作成 -> Dockerに固める」というプロセスに落とすことができ、進捗も良くなります。
今回はjson形式で日本語の自然言語を受け取り、映画のレビューの星がいくつなのがを予想するトイプロブレムをk8sに実際にデプロイして使ってみるまでを説明します。
今回のk8sのデザインはこのようなスタイルになります。

テキストを評価するAPIのDockerコンテナの作り方
トイプロブレムの予想モデルの要件
- 任意のテキストをhttp経由でjsonを受け取る
- テキストを分かち書きし、ベクトル化する
- ベクトル化した情報に基づき、テキストが映画レビューならば、レビューの星何個に該当するか予想する
- 予想した星の数をhttp経由でjsonで返却する
- 以上の挙動をする仕組みをDockerコンテナとして提供する
HTTPサーバは私の以前のJSONでサーバクライアント間のやりとりのプロジェクトを参照しています。
予想システムは映画.comさまのコーパスを利用して、LightGBMでテキストコーパスから星の数の予想を行います。学習と評価に使ったスクリプトとコーパスはこちらになります。
Dockerコンテナに集約する
以前作成した何でもごった煮Dockerがコンテナがあり、それを元に編集して作成しました。
本来ならば、Docker Fileを厳密に定義して、Docker Fileからgithubからpullして、システムの/usr/binに任意のスクリプトを配置する記述をする必要があります。
それとは別に、アドホックなオペレーションをある程度許容する方法も可能ではあり、Dockerの中に入ってしまって、様々な環境を構築して、commitしてしまうのもありかと思っています(というか楽ですので、それで対応しました)
ベストプラクティスは様々な企業文化があるので、それに従うといいでしょうが、雑な方法についてはこちらで説明しているので、参考にしていただければ幸いです。
作成したDockerコンテナはこちら
動作はこのようにローカルでも行えます。
$ docker pull nardtree/lightgbm-clf $ docker run -it nardtree/lightgbm-clf 40-predict.py
挙動のチェック
ポジティブな文を投入してみる
$ curl -v -H "Accept: application/json" -H "Content-type: application/json" -X POST -d '{"texts":"すごい!最高に興奮した!楽しい"}' http://localhost:4567/api/1/users
{"score": 4.77975661771051}
(星5が最高なので、ほぼ最高と正しく予想できている)
ネガティブな文を投入してみる
$ curl -v -H "Accept: application/json" -H "Content-type: application/json" -X POST -d '{"texts":"この映画は全くだめ、楽しくない。駄作"}' http://localhost:4567/api/1/users
{"score": 1.2809874000768104}
(星1が最低と、正しく予想できている)
DockerコンテナのGoogle Cloud Container Registryへの登録
Cloud Container Registryへの登録は、タグが、asia.gcr.io/${YOUR_PROJECT_NAME}/${CONTAINER_NAME}となっている必要があるので、
このようにコミットして、実行中のコンテナに対して、別のタグを付けます。
$ docker commit 44f751eb4c19
sha256:5a60e4460a156f4ca2465f4eb71983fbd040a084116884bcb40e88e3537cdc38
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
<none> <none> 5a60e4460a15 2 minutes ago 8.39GB
...
$ docker tag 5a60e4460a15 asia.gcr.io/${YOUR_PROJECT_NAME}/${CONTAINER_NAME}
gcrへコンテナのアップロード
$ gcloud docker -- push asia.gcr.io/${YOUR_PROJECT_NAME}/${CONTAINER_NAME}:latest
今回は、CONTAINER_NAMEはlightgbm-clfとしました
※docker hubに置いてあるので参考にしてください
K8Sへのデプロイ
K8Sへのデプロイは、コマンドだと、デプロイ時の進捗の情報が充分に見れないのでWebUIで行う例を示します。
GCPのKubernetes Engineにアクセスし、クラスタを作成します。
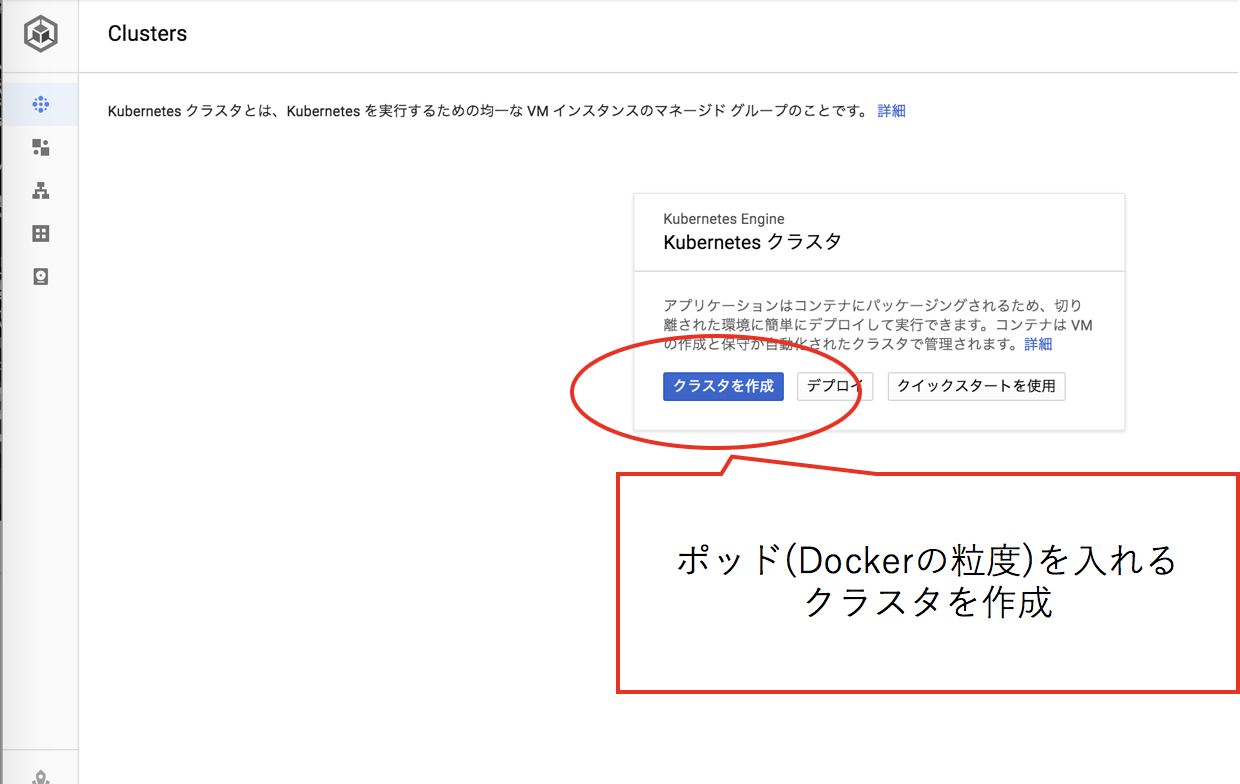
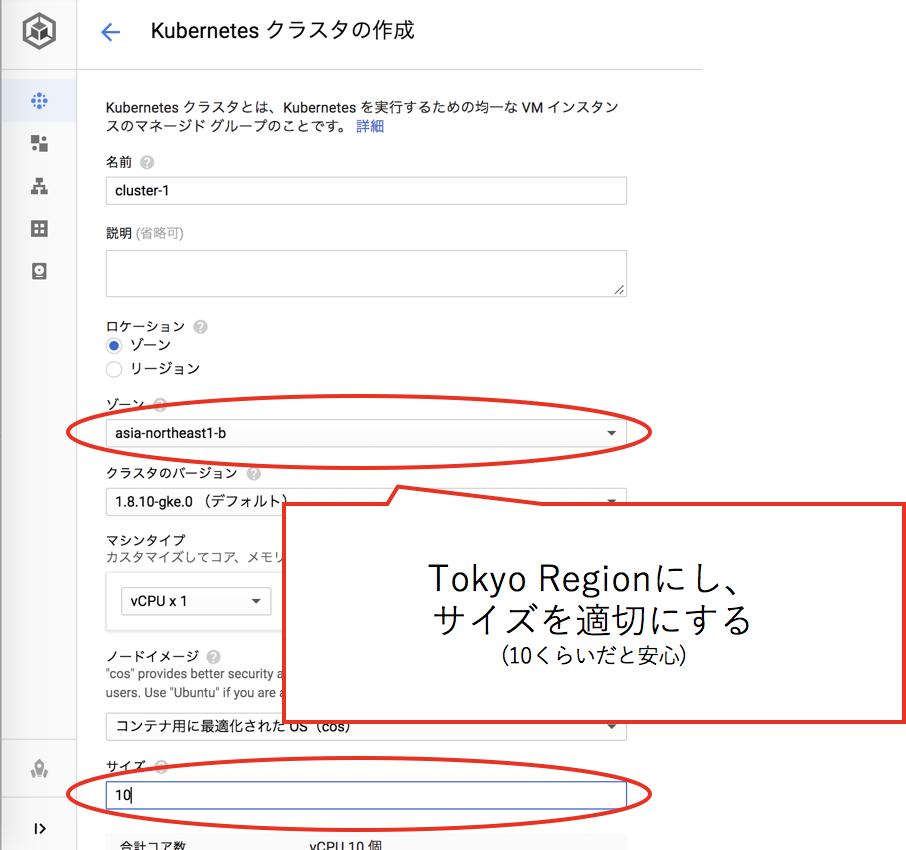
Hello World程度であれば少ないリソースでいいのですが、少し余裕を持って多めのリソースを投下します。
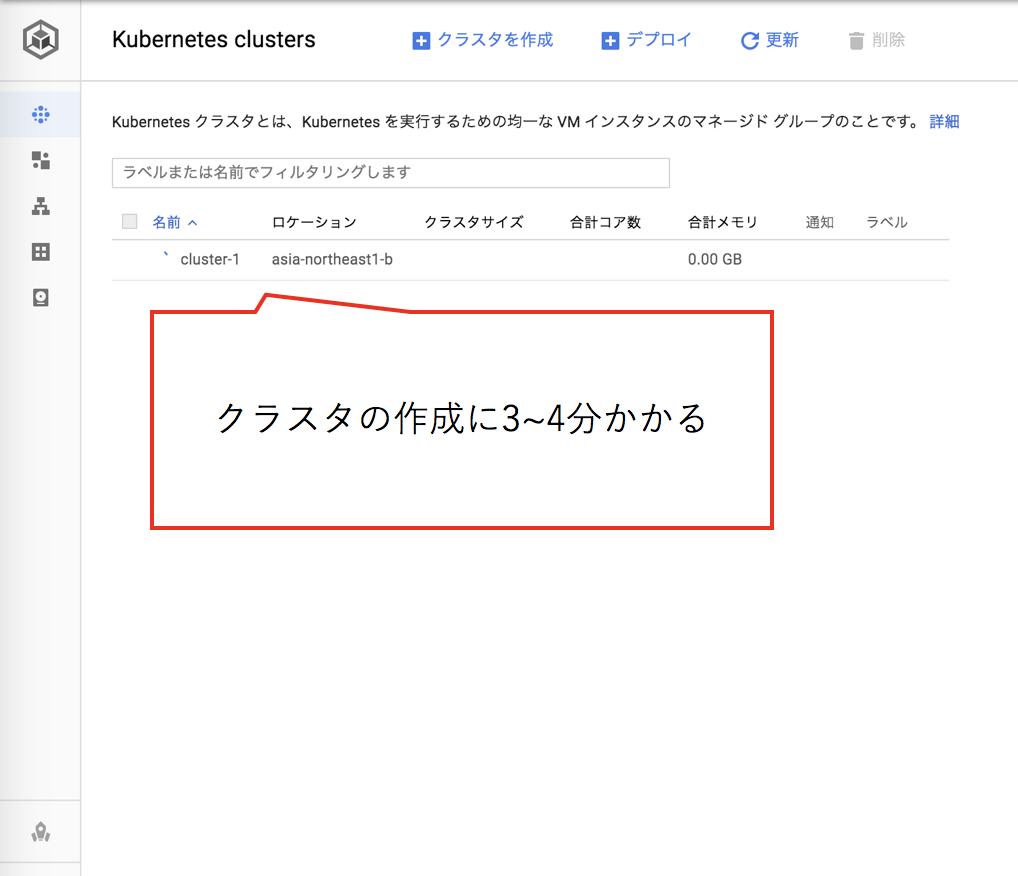
クラスタの作成にはしばらくかかるので、しばらく待ちます。
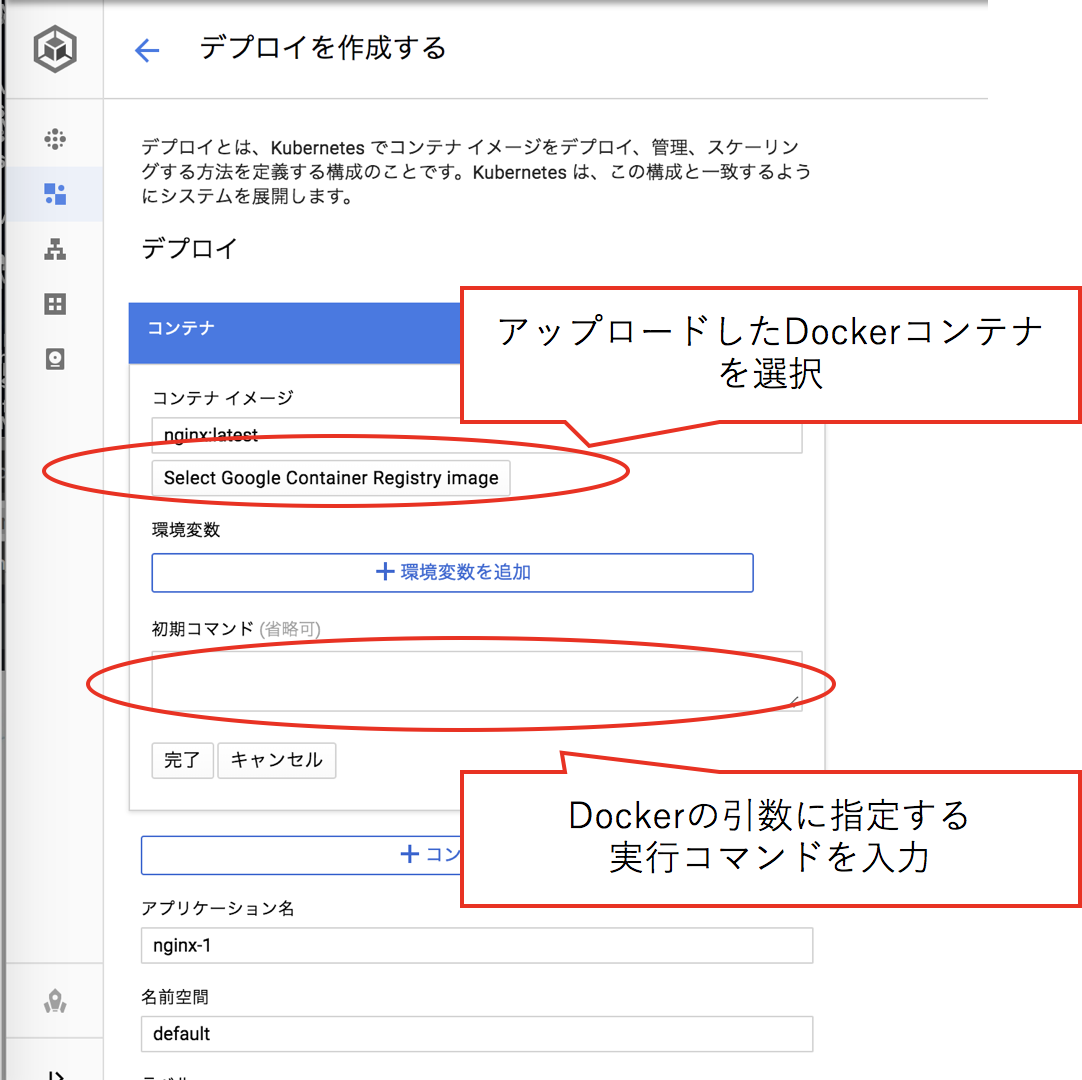
コンテナレジストリに登録したご自身のDockerコンテナを指定し、このコンテナのサービスの実行に必要な引数を入力します。

機械学習のモデルと各種依存ライブラリを含んだDockerコンテナはサイズが大きいので、ダウンロードが完了しデプロイが終わるまでしばらく待ちます(10分程度)
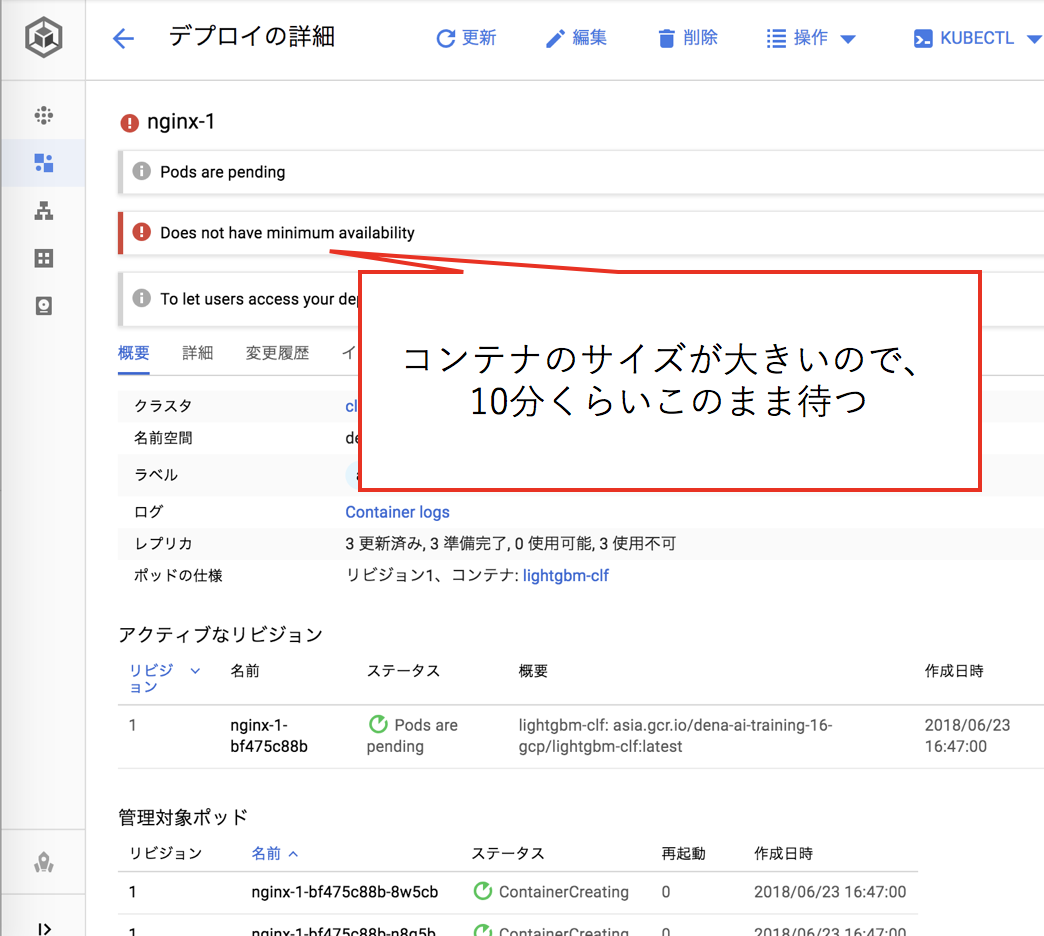
外部に公開するために、IPの割当とPortのマッピングを行います。
このとき、サービスタイプはロードバランサーを選択します。

外部IPが得られるので、次の項で、実際にアクセスしてみましょう。

実際にアクセスする
今回はマイクロサービスのデザインパターンにのっとり、jsonでデータをやり取りし、任意のテキスト情報から、そのテキストの映画のレビューとしての星の数を予想します。
stress-testing.pyで1000件の自然言語のコーパスに対して、負荷テストを行っています。
K8Sの特性としてか、SLAを大幅に超過したときに、httpサーバが応答しなくなってしまうので、これは実運用の際にはよく考えたほうが良さそうです。
GCP K8Sで予想する
$ DOCKER=35.189.146.153 python3 stress-testing.py
...
{"score": 4.059278052177565} 特殊な映画 クリストファー・ノーランらしさ全開だと感じました。この緊迫感、絶望感、暗さ。ダークナイトを思い出します。昼のシーンが多く画面や映像が暗い訳ではないのですが、な
んとなく雰囲気が暗い。でもこの暗さがいい味を出してます。分かりやすい娯楽映画ばかり観ている人には理解しにくいかも。
elapsed time 18.113281965255737
ローカルのDOCKERで予想する
$ DOCKER=localhost python3 stress-testing.py
...
{"score": 4.059278052177565} 特殊な映画 クリストファー・ノーランらしさ全開だと感じました。この緊迫感、絶望感、暗さ。ダークナイトを思い出します。昼のシーンが多く画面や映像が暗い訳ではないのですが、な
んとなく雰囲気が暗い。でもこの暗さがいい味を出してます。分かりやすい娯楽映画ばかり観ている人には理解しにくいかも。
elapsed time 5.5899786949157715
何もチューニングしない状態では、ローカルのほうが早いですね(それはそう)
まとめ
Dockerで簡潔にかつ素早くサービスを提供する仕組みを提供する仕組みとしてとてもよさそうです。
小さい案件を一瞬で終わらせるデザインパターンとして、有益なように思います。
kubeflowではなくてk8sをやった理由
フレームワークを利用しないことによる、圧倒的に高い自由度と、ベースとなるDockerコンテナをそれなりにちゃんと整えていたので、kubeflowのワークフローに乗せるメリットは今回の設定では少なかったです。そのため、生のk8sを利用しました。
参照したドキュメント
- Machine Learning Toolkit for Kubernetes
- Mercari ML Ops Night Vol.1 を開催しました
- 機械学習ではじめるDocker
- ML Ops on AWS
実際に使用したコードはこちら
実践的な分散処理を利用して処理を高速化
実践的な分散処理を利用して処理を高速化
GCPやAWSで膨大な計算を行う際に、オーバーヘッドを見極めて、大量のインスタンスを利用し、半自動化して、より効率的に運用するテクニックです。
Kaggle Google Landmark Recognition + Retrievalで必要となったテク
Kaggleでチームを組んで皆さんのノウハウと勢いを学ぶべく、KaggleのGoogle Landmark RecognitionとRetrievalのコンペティションにそれぞれチームで、参加しました。
メンツは、キャッシュさん、yu4uさん、私という激強のお二人に私が計算リソースの最適化で参加しました。画像のことはディープ以降の知識レベルであったので、大変勉強になったコンペです。結果は銀メダル2個です。
「ディープの特徴量」 + 「局所特徴量」の両方を取り出し、マッチングを計算するという問題で、これが大量の画像に対して適応しようとすると、とても重いものでした。
これを様々な計算リソースを投入し、並列で計算した方法がかなり極まっていたのと、これは知らないと難しいかも、、、と思い、よい機会なのでまとめました。
大量のクラウドの一時的なインスタンスをかりて、SSHFSというファイルシステムで一つのマシンをマウントし、各インスタンスに処理の命令を送り、オーバーヘッドを見極めて、アルゴリズム的改善を行い、改善した処理プロセスを行う、というPDCAのような流れをおこうなのですが、各要素について説明したいと思います。
目次
- ファイルシステム
- GCP Preemtipbleインスタンスを用いた効率的なスケールアウト
- MacBookからGCPのインスタンスに命令を送る
- Overheadを見極める
- Forkコスト最小化とメモ化
- まとめ
1. ファイルシステム:SSHFSがファイルの破損が少なくて便利
sshfsはssh経由で、ファイルシステムをマウントする仕組みですが、安定性が、他のリモート経由のファイルシステムに対して高く、一つのハードディスクに対して、sshfs経由で多くのマシンからマウントしても、問題が比較的軽微です。
また、ホストから簡単に進捗状況をチェックすこともできます。
この構造のメリットは、横展開するマシンの台数に応じて早くできることと、コードを追加で編集することなく、分散処理できます。
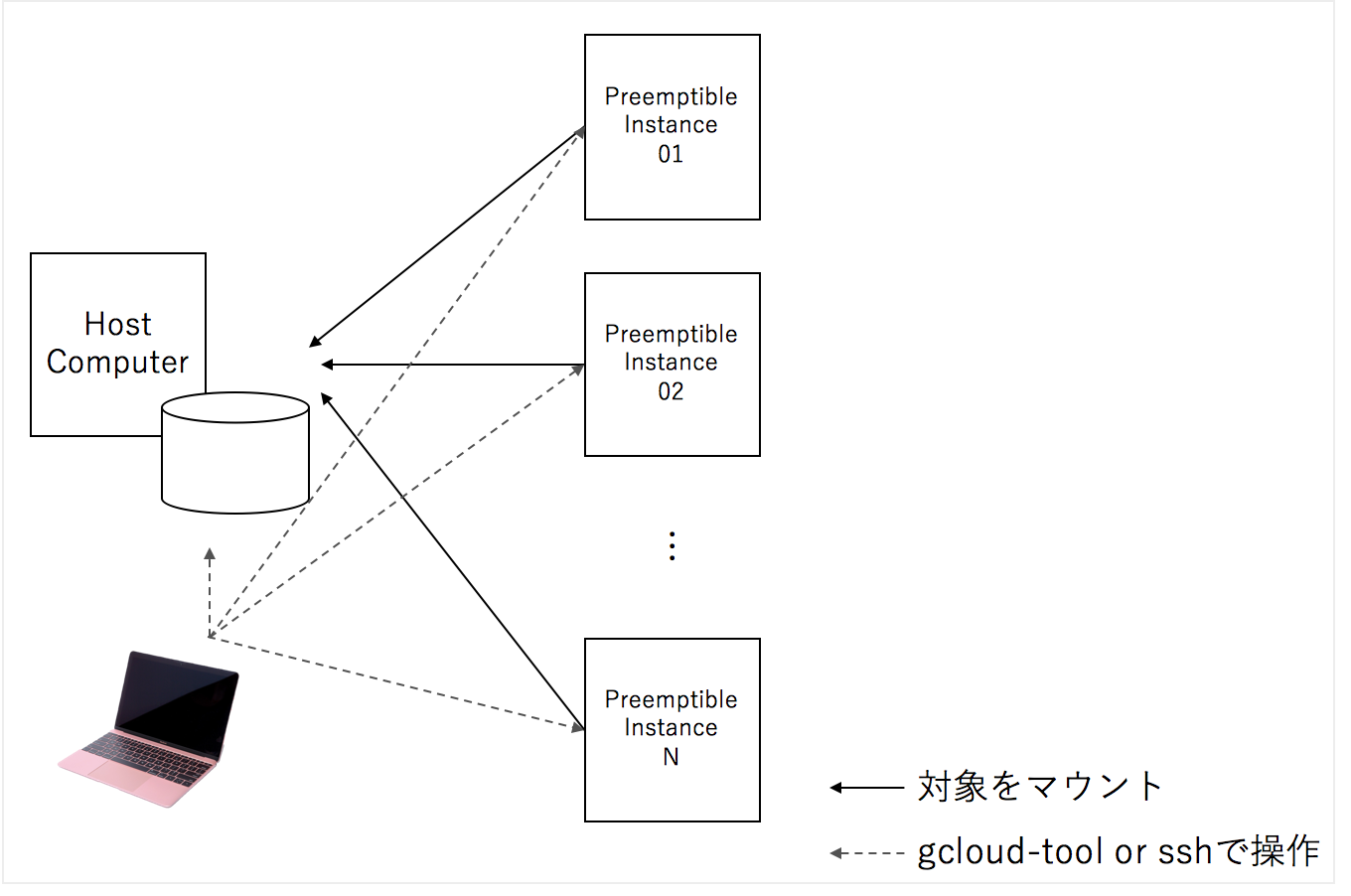
図1.
処理粒度を決定して、処理したデータはなにかキーとなる値か、なければ処理したデータのhash値でファイルが処理済みかどうかを判断することで、効率的に分散処理することtができます。
sshfs上の処理粒度に対してすでに、処理済みであれば、処理をスキップします。
(sshfs上で行ったものは二度目はファイルが共有され、二度目は、処理されないので、効率的に処理できます)
from pathlib import Path import random from concurrent.futures import ProcessPoolExecutor as PPE def deal(path): target = Path( f'target_dir/' + str(path).split('/').pop() ) if target.exists(): # do nothing return # do some heavy process target.open('w').write( 'some_heavy_output' ) paths = [path for path in Path('source_dir/').glob('*')] random.shuffle(paths) # shuffle with PPE(max_workers=64) as exe: exe.map(deal, paths)
2. GCP Preemptible Instance(AWSのSpot Instance)を用いた効率的なスケールアウト
計算ノードは、非同期で運用できるので、途中で唐突にシャットダウンされても問題がないです。そのため、安いけどクラウド運営側の都合でシャットダウンされてしまう可能性があるが、1/10~1/5の値段程度に収まるGCP PreemptibleインスタンスやAWS Spotインスタンスを用いることができます。
Preemptibleインスタンスはgcloudコマンドで一括で作成できますが、このようにPythonなどのスクリプトでラップしておくとまとめて作成できて便利です。
Preemptible インスタンスをまとめて作成
import os type = 'n1-highcpu-64' image = 'nardtree-jupyter-1' for i in range(0, 3): name = f'adhoc-preemptible-{i:03d}' ctx = f'gcloud compute instances create {name} --machine-type {type} --image {image} --preemptible' os.system(ctx)
このスクリプトは、自分で作成した必要なライブラリがインストールされた状態のイメージ(nardtree-jupyter-1)からハイパフォーマンスのインスタンスを3台作成します。
3. MacBookからGCPのインスタンスに命令を送る
google cloud toolをインストールし設定することで、GCPのインスタンスに対して命令(コマンド)を送ることができます
Premptible インスタンスに必要なソフトをインストールして、sshfs経由でマウント
クライアントマシン(手元のMacBookなど)から、コマンドを実行させることができます。
このオペレーションのなかに、手元のマシンから任意の前処理,学習のスクリプトを実行することもできます。
(GCP_NAME, GCP_KEY_NAMEは手元のパソコンの環境変数に設定しておくとよいです)
import os GCP_NAME = os.environ['GCP_NAME'] GCP_KEY_NAME = os.environ['GCP_KEY_NAME'] names = [f'adhoc-preemptible-{i:03d}' for i in range(0, 3)] # commandsのところに任意の処理を書くことができます commands = [ 'sudo apt update', \ 'sudo apt-get install sshfs', \ 'mkdir machine', \ f'sshfs 35.200.39.32:/home/{GCP_NAME} /home/{GCP_NAME}/machine -o IdentityFile=/home/{GCP_NAME}/.ssh/{GCP_KEY_NAME} -o StrictHostKeyChecking=no' ] for name in names: for command in commands: base = f'gcloud compute ssh {GCP_NAME}@{name} --command "{command}"' os.system(base)
4. Overheadを見極める
高速化の余地があるプログラムの最適化はどうされていますでしょうか
私は、以下のプロセスで全体のプロセスを最適化しています。


図2.
図2の例では、CPUは空いており、コードとこの観測結果から、DISKのアクセスが間に合ってないと分かります。オンメモリで読み込むことや、よりアクセスの速いDISKを利用することが検討されます。
5. Forkコスト最小化とメモ化
マルチプロセッシングによるリソースの最大利用は便利な方法ですが、spawn, fork, forkserverの方法が提供されています。
使っていて最もコスト安なのはforkなのですが、これでうまく動作しないことが稀にあって、spawnやforkserverに切り替えて用いることがあります。spawnが一番重いです。
forkでは親プロセスのメモリ内容をコピーしてしまうので、大きなデータを並列処理しようとすると、丸ごとコピーコストがかかり、小さい処理を行うためだけにメモリがいくら高速と言えど、細かく行いすぎるのは、かなりのコストになるので、バッチ的に処理する内容をある程度固めて行うべきです。 cent

例えば、次のランダムな値を100万回、二乗するのをマルチプロセスで行うと、おおよそ、30秒かかります。
from concurrent.futures import ProcessPoolExecutor as PPE import time import random args = [random.randint(0, 1_000) for i in range(100_000)] def normal(i): ans = i*i return ans start = time.time() with PPE(max_workers=16) as exe: exe.map(normal, args) print(f'elapsed time {time.time() - start}')
$ python3 batch.py elapsed time 32.37867593765259
では、単純にある程度、データをチャンクしてマルチプロセスにします。
すると、0.04秒程度になり、ほぼ一瞬で処理が完了します
これはおおよそ、もとの速度の800倍です
from concurrent.futures import ProcessPoolExecutor as PPE import time import random data = [random.randint(0, 1_000) for i in range(100_000)] tmp = {} for index, rint in enumerate(data): key = index%16 if tmp.get(key) is None: tmp[key] = [] tmp[key].append( rint ) args = [ rints for key, rints in tmp.items() ] def batch(rints): return [rint*rint for rint in rints ] start = time.time() with PPE(max_workers=16) as exe: exe.map(batch, args) print(f'elapsed time {time.time() - start}')
$ python3 batch2.py elapsed time 0.035398244857788086
メモ化、キャッシュを利用する
同じ内容が出現し、結果を保存できる場合、計算の多くを共通で占める箇所を、特定のキーで保存しておいて、再利用することで、高速に処理することができます。
特定の入力の値を10乗して、返すというあまりない問題ですが、わかりやすいので、これで示すと、チャンクして処理するものが、このコードになり、4秒程度かかります。
import time import random import functools data = [random.randint(0, 1_000) for i in range(10_000_000)] tmp = {} for index, rint in enumerate(data): key = index%16 if tmp.get(key) is None: tmp[key] = [] tmp[key].append( rint ) args = [ rints for key, rints in tmp.items() ] def batch(rints): return [functools.reduce(lambda y,x:y*x, [rint for i in range(10)]) for rint in rints ] start = time.time() with PPE(max_workers=16) as exe: exe.map(batch, args) print(f'elapsed time {time.time() - start}')
$ python3 batch2.py elapsed time 3.9257876873016357
これをメモ化して、ある程度の最適化を入れると、倍以上の速度になります
from concurrent.futures import ProcessPoolExecutor as PPE import time import random import itertools data = [random.randint(0, 1_000) for i in range(10_000_000)] tmp = {} for index, rint in enumerate(data): key = index%16 if tmp.get(key) is None: tmp[key] = [] tmp[key].append( rint ) args = [ rints for key, rints in tmp.items() ] def batch(rints): mem = {} result = [] for rint in rints: if mem.get(rint) is None: mem[rint] = itertools.reduce(lambda y,x:y*x, [rint for i in range(10)] ) result.append( mem[rint] ) return result start = time.time() with PPE(max_workers=16) as exe: exe.map(batch, args) print(f'elapsed time {time.time() - start}')
$ python3 batch3.py elapsed time 1.4659481048583984
5.5 コード
6. まとめ
並列処理はMapReduceという分析スタイル以外のものもたくさん存在し、微妙な勘所の最適化がないとそもそも目的に対して間に合わないということも十分にありえます。
sshfsを共通のファイルシステムとして持ち、Preemptibleインスタンスをたくさん用意して、 gcloudで任意のコマンドを送信することで、一つの問題を膨大な計算リソースで処理することができるようになります。
計算量での押し切りは、最後に粘りがちになるえる技能でもあるので、そこそこ重要なのだと思います。