3つのレコメンド系アルゴリズム
(誤字脱字が目立ったので、修正しました。。)
3つのレコメンド系アルゴリズム
- 協調フィルタリング
- fasttextでの購買時系列を考慮したアイテムベースのproduct2vec(skipgram)
- アイテムベースのtfidfなどの類似度計算を利用したレコメンド
1. 協調フィルタリング
協調フィルタリング自体は簡潔なアルゴリズムで、実装しようと思えば、簡単にできる類のものであるように思えるのですが、製品と製品の類似度を計算するのに、その製品を購入したユーザをベクトル列としてみなすと割と簡単に計算できます[5]。世の中のコンテンツはユーザの関連度の計算の方が多い気がしますが、今回はアイテムにひもづくユーザをベクトルにします
例えば、今回はbookmeter.comさまのユーザの読んだ本情報を用いて、一人のユーザを一つのユニークな特徴量としてみなすことで、本同士の関連度が計算可能になります
Albertさんなどのブログなどを参考し、今回の問題に当てはめると、このようなことであると言えそうです。
今回は要素間距離の計算方法に、cosine similarityを利用していますが、ジャッカードという距離の取り方や、色々あるので、実際に業務で使う時にはあるべきレコメンドリストを作って定量評価すると良いでしょう。

図1. 今回用いた協調フィルタリング
今回用いさせていただいた、bookmeter.comさんから作成したデータセットはこちらです。27GByte程度あるので、覚悟してダウンロードしてください(何度もスクレイピングするのは気がひけるので、初期調査はこのデータセットを公開しますので、有効活用していただけると幸いです。用途はアカデミックな用途に限定されると思います)
また、必要なユーザと読んだ本とその時のタイムスタンプの情報のみをまとめたものは、こちらからダウンロードできます。
このアルゴリズムはユーザの行動が蓄積されていなくても、一つ商品を選べば、それに関連してレコメンドできるという特徴があり、この用途場合、強力に動作します。
学習
Google Cloud Strageから、mapped.jsonpを当プロジェクトにダウンロードしたという前提です
$ wget https://storage.googleapis.com/nardtree/bookmeter-scraping-20171127/mapped.jsonp $ python3 reduce.py --fold1 $ cd collaborative-filtering-itembase $ python3 make_matrix.py --step1 $ python3 make_matrix.py --step2 # <- とても重いので、計算に数日みてください
結果.
いくつか結果をピックアップします。チェリーピックにならないように、ランダムサンプルしたうち知っているものを選んで見ました。 それなりに正しく動作していることがわかり一安心です。
氷菓(1)(角川コミックス・エース) との類似度 当然、その本地身とシリーズが出て欲しいのですが、例えば、コミック版氷菓を読むユーザは、「我妻さんは俺のヨメ」シリーズも読むことがわかりました。 氷菓が好きな人は、このシリーズもきっとおすすめです
氷菓(1)(角川コミックス・エース) 1.0 氷菓(3)(角川コミックス・エース) 0.6324555320336759 氷菓(2)(角川コミックス・エース) 0.565685424949238 氷菓(4)(角川コミックス・エース) 0.5477225575051661 氷菓(5)(角川コミックス・エース) 0.4743416490252569 我妻さんは俺のヨメ(8) 0.4472135954999579 キン肉マン60(ジャンプコミックスDIG… 0.4472135954999579 弱虫ペダル 51(少年チャンピオン・コミッ… 0.4472135954999579 魔法遣いに大切なこと~夏のソラ~(1)(角… 0.4472135954999579 人生はまだ長いので(FEELCOMICS… 0.4472135954999579 キン肉マン59(ジャンプコミックスDIG… 0.4472135954999579 お前はまだグンマを知らない 1巻(バンチコ… 0.4472135954999579 我妻さんは俺のヨメ(5) 0.4472135954999579 トリニティセブン 7人の魔書使い(1)(ド… 0.4472135954999579 このお姉さんはフィクションです!?:4… 0.4472135954999579 我妻さんは俺のヨメ(6)(週刊少年マガジン… 0.4472135954999579 ナナマルサンバツ(7)(角川コミックス・… 0.4472135954999579 夏の前日(4) 0.4472135954999579 我妻さんは俺のヨメ(9)(週刊少年マガジン… 0.4472135954999579 お前はまだグンマを知らない 2巻(バンチコ… 0.4472135954999579 塩田先生と雨井ちゃん2 0.4472135954999579
ガガガ文庫 羽月莉音の帝国10 との類似度
完全に趣味ですが、一時期、どハマりしていた「羽月莉音の帝国」シリーズです。お金と欲と権力に振り回される少年少女とディープステートたちは熱かった
この系統の書籍が好きでしたが、当時は定量的に解析するすべを知らず、今このように類似度を計算すると感慨深いものがあります
ガガガ文庫 羽月莉音の帝国10(イラスト完全… 1.0 ガガガ文庫 羽月莉音の帝国9(イラスト完全版) 1.0 群れない生き方(SB文庫) 0.7071067811865475 ハチワンダイバー100万円争奪・地下将棋!… 0.7071067811865475 ガガガ文庫 羽月莉音の帝国3(イラスト完全版) 0.7071067811865475 大人のADHD ――もっとも身近な発達障害… 0.7071067811865475 ハチワンダイバー闇将棋集団・鬼将会を追え編… 0.7071067811865475 ガガガ文庫 羽月莉音の帝国5(イラスト完全版) 0.7071067811865475 奥の細道(21世紀によむ日本の古典15) 0.7071067811865475 ハチワンダイバー恋の“賭け将棋”にダイブ!… 0.7071067811865475 ハチワンダイバー激アツ修行!24時間将棋編… 0.7071067811865475 世界の端っことあんずジャム(2)(デザート… 0.7071067811865475 No.1理論―ビジネスで、スポーツで、受験… 0.7071067811865475 腸が嫌がる食べ物、喜ぶ食べ物 40歳を過ぎた… 0.7071067811865475 UXの時代―IoTとシェアリングは産業を… 0.7071067811865475 図解・速算の技術 一瞬で正確に計算するための… 0.7071067811865475 マンガでわかる有機化学 結合と反応のふしぎか… 0.7071067811865475 頭の体操 第1集~パズル・クイズで脳ミソを鍛… 0.7071067811865475 ガガガ文庫 羽月莉音の帝国7(イラスト完全版) 0.7071067811865475 コンなパニック(1)(なかよしコミックス) 0.7071067811865475 ガガガ文庫 羽月莉音の帝国8(イラスト完全版) 0.7071067811865475 ガガガ文庫 羽月莉音の帝国4(イラスト完全版) 0.5 シンギュラリティ・ビジネス AI時代に勝ち残… 0.5
ハーモニー〔新版〕(ハヤカワ文庫JA) に類似する本
私が唯物論者になるきっかけで、ビッグデータと機械学習による意思決定のその先に置けそうな社会として、「意識」が消失するという仮説は大変魅力的な小説です
伊藤計劃三部作の中で一番好きです。
ハーモニー〔新版〕(ハヤカワ文庫JA) 1.0 虐殺器官〔新版〕(ハヤカワ文庫JA) 0.4568027835606774 屍者の帝国(河出文庫) 0.2727051065113576 虐殺器官(ハヤカワ文庫JA) 0.14109861338756574 TheIndifferenceEngin… 0.12909944487358058 アンドロイドは電気羊の夢を見るか?(ハヤカ… 0.11756124576907943 PSYCHO-PASSGENESIS1… 0.11603391514496726 PSYCHO-PASSGENESIS2… 0.11489125293076057 know(ハヤカワ文庫JA) 0.11199737837836385 一九八四年[新訳版](ハヤカワepi文庫) 0.10744565033846916 PSYCHO-PASSASYLUM1(… 0.10264528445948555 PSYCHO-PASSGENESIS3… 0.09331569498236164 PSYCHO-PASSASYLUM2(… 0.09203579866168446 ニューロマンサー(ハヤカワ文庫SF) 0.0900003231847342 伊藤計劃記録II(ハヤカワ文庫JA) 0.08882967062031503 いなくなれ、群青(新潮文庫nex) 0.08679025878292934 [映]アムリタ(メディアワークス文庫の… 0.08626212458659283 華氏451度〔新訳版〕(ハヤカワ文庫SF) 0.08464673190724618 その白さえ嘘だとしても(新潮文庫nex) 0.08191004034460432
PSYCHO-PASSも好きですが、小説でてたんですか!良いですね。買います!←こんな感じのユースケースを想定しています
データセットのダウンロード
2. fasttextでのアイテムベースのproduct2vec(skipgram)
一部でproduct2vecと呼ばれる技術のようですが、同名でRNNを用いた方法も提案されており、購買鼓動を一連の時系列として文章のように捉えることで、似た購買行動をするユーザの購買製品が似たようなベクトルになるという方法を取っているようです
このベクトルとベクトルのコサイン距離か、ユークリッド距離を取れば、購買行動が似た商品ということができそうです
リクルートではこのアリゴリズムは動作しているよう[4]なのですが、効果のほどはどうなんですかね?知りたいです

期待される結果
- 流行があり、時代と時期によって読まれやすい本などが存在している場合、同じ時代に同じ流れで、読まれやすい本のレコメンド
- 本のコンテンツの類似度ではなく、同じような本を読む人が同じ時代にどういった方も、また読んでいたか、という解釈
- 時系列的な影響を考慮した協調フィルタリングのようなものとして働くと期待できる
学習アルゴリズム
- fasttext
- skipgram
- 512次元
- n-chargramは無効化
前処理
bookmeterさんからスクレイピンしたデータからユーザ名とIDで読んだ本を時系列順に紐づけます
$ python3 parse_user_book.py --map1 $ python3 parse_user_book.py --fold1
bookmeterさんのデータをpythonで扱うデータ型に変換します
$ python3 reduce.py --fold1 $ python3 reduce.py --label1 > recoomender-fasttext/dump.jsonp
fasttext(skipgramを今回計算するソフト)で処理できる形式に変換します
$ cd recoomender-fasttext $ python3 mkdataset.py
SkipGramでベクトル化と、本ごとのcosime similarityの計算
$ sh run.sh $ python3 ranking.py --to_vec $ mkdir sims $ python3 ranking.py --sim
定性的な結果
- 近年、本は大量に出版されて、その時に応じて売れ行きなどが変化するため、その時代に同じような本を買う傾向がある人が同じような買うというプロセスで似た傾向の本を買うと仮定ができそうである
- 本は、趣味嗜好の内容が似ている系列で似る傾向があり、コンテンツの内容では評価されない
以上の視点を持ちながら、私が知っている書籍では理解しやすいので、いくつかピックアップした
聖☆おにいさん(11)(モーニングKC) と同じような購買の行動で登場する本
聖☆おにいさん(11)(モーニングKC) 聖☆おにいさん(11)(モーニングKC) 1.0 聖☆おにいさん(11)(モーニングKC) 富士山さんは思春期(1)(アクションコミッ… 0.8972133709829763 聖☆おにいさん(11)(モーニングKC) 血界戦線4―拳客のエデン―(ジャンプコ… 0.8880415759167462 聖☆おにいさん(11)(モーニングKC) 闇の守り人2(Nemuki+コミックス) 0.874690584963135 聖☆おにいさん(11)(モーニングKC) 高台家の人々1(マーガレットコミックス) 0.8739713568492584 聖☆おにいさん(11)(モーニングKC) よりぬき青春鉄道(MFコミックスジーンシ… 0.8654563200372407 聖☆おにいさん(11)(モーニングKC) MUJIN―無尽―2巻(コミック(Y… 0.864354621889988 聖☆おにいさん(11)(モーニングKC) 日日べんとう8(オフィスユーコミックス) 0.8642825499104115 聖☆おにいさん(11)(モーニングKC) Baby,ココロのママに!(1)(ポラリ… 0.8633512045595658 聖☆おにいさん(11)(モーニングKC) 僕とおじいちゃんと魔法の塔(1)(怪CO… 0.8599349055581674
ボールルームへようこそ(5) と同じような購買の行動で登場する本
ボールルームへようこそ(5)(講談社コミッ… ボールルームへようこそ(5)(講談社コミッ… 0.9999999999999999 ボールルームへようこそ(5)(講談社コミッ… 乙女座・スピカ・真珠星―タカハシマコ短編集… 0.9209695753657776 ボールルームへようこそ(5)(講談社コミッ… 微熱×発熱(少コミフラワーコミックス) 0.9200136951145198 ボールルームへようこそ(5)(講談社コミッ… 銀魂-ぎんたま-52(ジャンプコミックス) 0.9192139559710213 ボールルームへようこそ(5)(講談社コミッ… ボールルームへようこそ(3)(講談社コミッ… 0.9185994617714857 ボールルームへようこそ(5)(講談社コミッ… リメイク5(マッグガーデンコミックスE… 0.9178462840921753 ボールルームへようこそ(5)(講談社コミッ… カラダ探し2(ジャンプコミックス) 0.9133800737256051 ボールルームへようこそ(5)(講談社コミッ… エンジェル・ハート1STシーズン4(ゼノ… 0.9131301530550904 ボールルームへようこそ(5)(講談社コミッ… モテないし・・・そうだ、執事を召喚しよう。… 0.912900126682059 ボールルームへようこそ(5)(講談社コミッ… IPPO1(ヤングジャンプコミックス) 0.9127181876031607
バーナード嬢曰く。(REXコミックス) と同じような購買の行動で登場する本
バーナード嬢曰く。(REXコミックス) バーナード嬢曰く。(REXコミックス) 0.9999999999999999 バーナード嬢曰く。(REXコミックス) 宝石の国(7)(アフタヌーンKC) 0.8471396900305308 バーナード嬢曰く。(REXコミックス) 宝石の国(5)(アフタヌーンKC) 0.8382072129764407 バーナード嬢曰く。(REXコミックス) 里山奇談 0.816403634050381 バーナード嬢曰く。(REXコミックス) ファイブスター物語(12)(ニュータイプ… 0.8158735339937038 バーナード嬢曰く。(REXコミックス) 汐の声(山岸凉子スペシャルセレクション2) 0.813237955152229 バーナード嬢曰く。(REXコミックス) ゴールデンカムイ5(ヤングジャンプコミッ… 0.8124194507560973 バーナード嬢曰く。(REXコミックス) サンドマン(1)(DCCOMICSV… 0.8063562786141018 バーナード嬢曰く。(REXコミックス) ナチュン(5)(アフタヌーンKC) 0.8062792077739434 バーナード嬢曰く。(REXコミックス) めぞん一刻15(ビッグコミックス) 0.8050153883069142
34万冊にも及ぶ購買行動関連スコアを計算したので、きっとあなたの好きな本を広げるにも役に立つはずです。参考にしていただければ幸いです
Google Cloud Strageにtar.gzで固めたファイルを置いてあるので、どの本が何の本と関連度がどれくらい持ちたい方は参考にしてみてください
アイテムベースのtfidfの類似度を利用したレコメンド
今更、tfidfなのかという気持ちもあるのですが、ユーザの購買行動ログが蓄積されていない時には有効な手段です
skipgramにせよRNNのEncoder-Decoderモデルを利用するにせよ、ログがある程度あることを前提とするので、コンテンツを示す情報が何かしら適切に表現されていれば、類似度の計算が可能です。
例えば、本の概要情報をBag Of Wordsとして文字列のベクトルとしてみなすことで、レコメンドが可能になります。
前処理
本の概要情報をtfidfでベクトル化します
$ python3 tfidf.py --make
類似度を計算
$ python3 tfidf.py --similarity
具体例
その女アレックス (文春文庫)
{ "その女アレックス (文春文庫)": 1.0, "死のドレスを花婿に (文春文庫)": 0.217211675720195, "蟻の菜園 ―アントガーデンー (宝島社文庫 『このミス』大賞シリーズ)": 0.17019688046138778, "ゴーストマン 時限紙幣": 0.15007411620369276, "使命と魂のリミット (角川文庫)": 0.11353386562607512, "ネトゲの嫁は女の子じゃないと思った? (電撃文庫)": 0.10053605201421331, "絶叫": 0.09928094382921815, "限界点": 0.09839970550260285, "探偵が早すぎる (上) (講談社タイガ)": 0.09710240347327244, "何様ですか? (宝島社文庫 『このミス』大賞シリーズ)": 0.0967122631023104 }
ビブリア古書堂の事件手帖 (6) ~栞子さんと巡るさだめ~ (メディアワークス文庫)
{ "ビブリア古書堂の事件手帖 (6) ~栞子さんと巡るさだめ~ (メディアワークス文庫)": 1.0, "ビブリア古書堂の事件手帖4 ~栞子さんと二つの顔~ (メディアワークス文庫)": 0.14235848517270094, "ビブリア古書堂の事件手帖 (5) ~栞子さんと繋がりの時~ (メディアワークス文庫)": 0.12690320576737468, "ビブリア古書堂の事件手帖 2 栞子さんと謎めく日常 (メディアワークス文庫)": 0.10860850572897893, "ビブリア古書堂の事件手帖3 ~栞子さんと消えない絆~ (メディアワークス文庫)": 0.09155840600578283, "0能者ミナト〈3〉 (メディアワークス文庫)": 0.08957995681421002, "ビブリア古書堂の事件手帖7 ~栞子さんと果てない舞台~ (メディアワークス文庫)": 0.07945929682993862, "きみと暮らせば (徳間文庫)": 0.07897713721113855, "ビブリア古書堂の事件手帖―栞子さんと奇妙な客人たち (メディアワークス文庫)": 0.07818237184568279, "天使たちの課外活動2 - ライジャの靴下 (C・NOVELSファンタジア)": 0.07661947755379202 }
オプションデータ
月ごとの本棚に登録された本の累計(その月での)数

読んでる人が多い本ランキング
読んでる人が多い本(2017年11月時点)
永遠の0(講談社文庫) 6805 ビブリア古書堂の事件手帖―栞子さんと奇妙な客… 6551 舟を編む 6500 イニシエーション・ラブ(文春文庫) 6158 火花 5988 阪急電車(幻冬舎文庫) 5979 夜は短し歩けよ乙女(角川文庫) 5964 君の膵臓をたべたい 5504 コンビニ人間 5134 ビブリア古書堂の事件手帖2栞子さんと謎め… 5075 レインツリーの国(新潮文庫) 4994 その女アレックス(文春文庫) 4792 ぼくは明日、昨日のきみとデートする(宝島社… 4631 氷菓(角川文庫) 4606 ビブリア古書堂の事件手帖3~栞子さんと消え… 4590
6ヶ月以上、連続で本を読んでいる人の読んでる本ランキング
1 舟を編む 5419 1 永遠の0(講談社文庫) 5296 1 ビブリア古書堂の事件手帖―栞子さんと奇妙な客… 5277 1 火花 5081 1 イニシエーション・ラブ(文春文庫) 4784 1 阪急電車(幻冬舎文庫) 4570 1 夜は短し歩けよ乙女(角川文庫) 4427 1 君の膵臓をたべたい 4422 1 コンビニ人間 4225 1 その女アレックス(文春文庫) 4186
6ヶ月間、連続で本を読むことができなかった人の読んでる本ランキング
0 夜は短し歩けよ乙女(角川文庫) 1537 0 永遠の0(講談社文庫) 1509 0 阪急電車(幻冬舎文庫) 1409 0 イニシエーション・ラブ(文春文庫) 1374 0 ビブリア古書堂の事件手帖―栞子さんと奇妙な客… 1274 0 ぼくは明日、昨日のきみとデートする(宝島社… 1143 0 レインツリーの国(新潮文庫) 1120 0 君の膵臓をたべたい 1082 0 舟を編む 1081 0 西の魔女が死んだ(新潮文庫) 1004
コード
githubにて管理しております。
参考
[1] Instacart Product2Vec & Clustering Using word2vec
[2] MRNet-Product2Vec: A Multi-task Recurrent Neural Network for Product Embeddings
[3] Deep Learning at AWS: Embedding & Attention Models
[4] リクルートのデータで世界へ挑む 組織を率いるサイエンティストの仕事観
[5] 推薦システムのアルゴリズム
勾配ブースティングを利用した、KPIに効く特徴量のレコメンド
勾配ブースティングを利用した、KPIに効く特徴量のレコメンド
近況:おばあちゃんが亡くなった関係で、しばらく更新できませんでした。人間の一生とは改めて有限で、限られた時間で何をどうやるかを意識しないといけないなと思いました
意思決定をサポートする機械学習の必要性
機械学習は、マスメディアの中で語られるまるで人間の置き換えかのように表現されることが多いのですが、利用できる実態としては以下の側面が私が携わる案件で多いです。
- CTR予想など、KPIを自動で場合によっては高速に計算することで、人間が最適な意志決定しやすくする
- 膨大な経験に基づく必要がある一部の職人の仕事で、何がKPIなのかなどの特徴量重要度を把握し、定量的な値で意志決定することで、属人性をなくす
まだ私自身、キャリアとして、そんなに長くない機械学習エンジニアですが、主要な幾つか本質的な要素に還元すると、このようなものであることが多いです
いろんなシステムを作ってきましたが、意外とヒアリングしていると、システムに半自動でいいから意思決定を任せたい(もしくは施策が定量的にどの程度有効なのか知りたい)などが多く見受けられました
IBMのコグニティブコンピューティングの資料を引用しますと、コグニティブコンピューティングのDecision(レコメンド), Discovery(意思決定のサポート)の領域とも無理くり解釈できそうではあります

ワトソンの料理の新しいレシピのレコメンドからの発想
もともと、このKPIを最大化する特徴量群をレコメンドするという考えは、シェフ・ワトソン[1]の全く新しい食材の組み合わせで美味しいと言われているレシピをレコメンドするという機能を幾つかの状況証拠から仮説を立てて、導いたものです
IBMが長らく研究していたテーマとして、意味情報を演算可能にするというお題があったはずですが、これはちょっと別で、機械学習の最小化のアルゴリズムでいくつかこの特徴量とあの特徴量が同時に存在して、ある量以下(または以上)ならば、という膨大なルールセットを獲得し、その獲得した条件式が成立していれば、美味しいはずであるという発想に基づいているかと思います
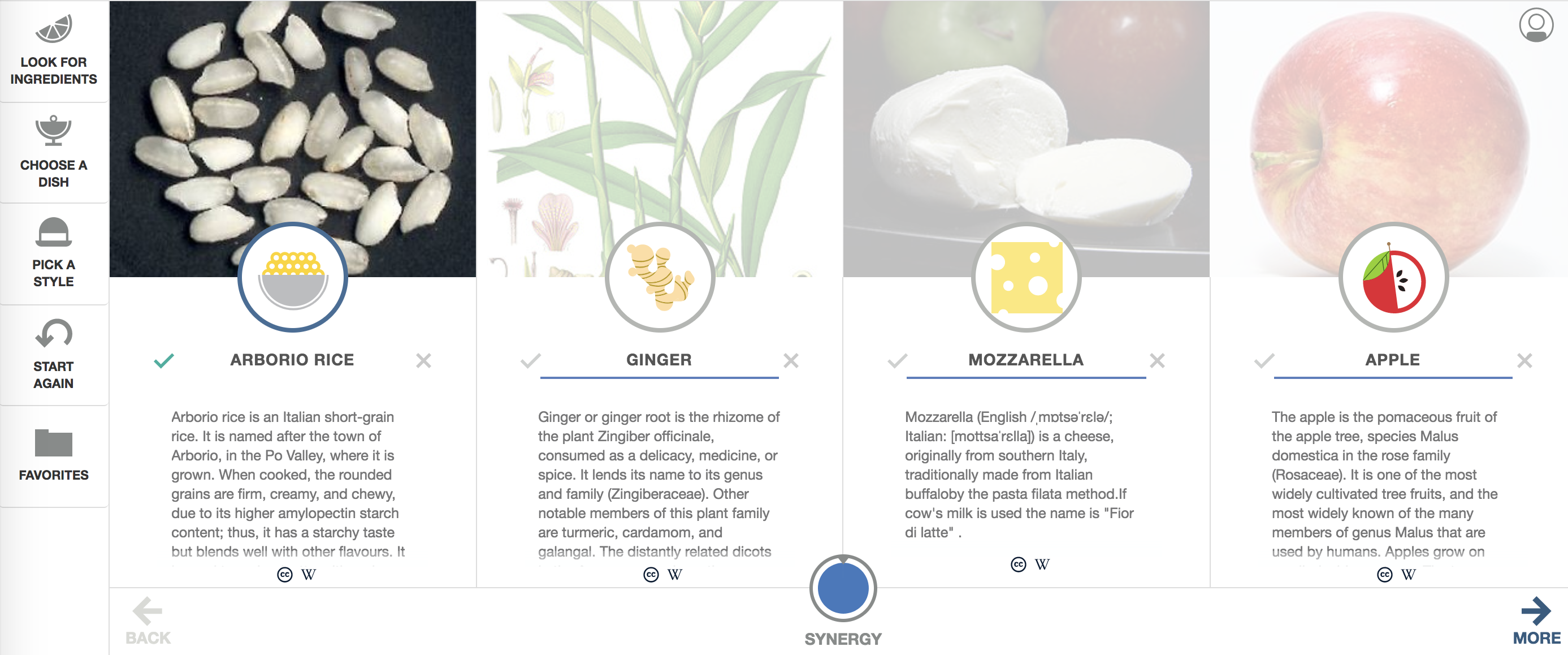
図1. 何品か、最初の条件となる、食品を選んで、他の何品かのレシピを自動でレコメンドします
今回はテキストの作りに着目し、テキストにどのような単語が含まれていたら、KPIの向上が望めるかのシステムを2chまとめサイトに対象にやってみたいと考えています
【実験】jin115.comのコメント数をどんな単語で記述したら数が増えるか予想する
jin115.comのデータセットをzip圧縮で17GByteもダウンロードしてしまったので、何か有効活用できないかと考えていたのですが、難しく、なんともKPIという軸で定量化できないので、 ある記事に対してつく、コメント数を増やすには、どんな単語選択が適切かという軸に切り替えて、分析してみました。
コードはgithubのレポジトリで管理しています
jin115.comでは、2chまとめが流行った時に大量のアクセスを受けていたという背景があり、一気にその時に成長したのですが、今はユーザ数はサチっているように見えます。
各月のユーザのコメント数を累積していくと、このようなグラフを書くことができました(2006年からやっているんですね。。すごい)

前処理
データセットダウンロード
Google Cloud Strageに大容量のスクレイピング済みのデータセットをzip圧縮したものがありので、追試等が必要な方は参照してください。
$ wget https://storage.googleapis.com/nardtree/jin115-20171125/jin115-20171125.zip
htmlコンテンツから必要なarticle, commentの数, 日時, タイトルのパース
ダウンロード済みのhtmlコンテンツから予想の元となる説明変数(article, title, date)と、目的変数であるcomment数をパースします
この捜査自体が極めて重いので、Google Data Strageからもダウンロードできます
$ python3 parser.py --map1
パースしたデータを分かち書きします
分かち書きして、形態素解析して、BoWとしてベクトル表現にできる状態にします
$ python3 wakati.py --verb
LightGBM, XGBoostで機械学習可能なデータセット(train, test)を作成します
まず最初に、予想するとしたKPIであるコメント数を予想するもモデルを構築することを目的とします
そのために、トレインとテストのデータセットを分割して、作成します
$ python3 make_sparse.py --terms # uniq単語をカウント $ python3 make_sparse.py --sparse # train, testデータセットを作成します
LightGBMで学習して、モデルを作成します
一般的に、言語のBoWは単語数に応じたベクトル時原まで拡大されますので、numpyなどで密行列で表現することには向いていません
そのため、デフォルトでスパースマトリックスを扱え、CUI経由で学習できるLightGBMのバイナリを直接実行してモデルを作成します
$ lightgbm config=train.conf
(LightGBMのインストールは、Githubからcloneして、cmake, make & sudo make installでシステムパスに追加しておくと便利です)
特徴量重要度を確認する
Gradient Boosting Machine系の特徴量重要度は、必ずしも、事象を説明する特徴量が支配的に記述されるわけではないのですが、どんな特徴量が効いているのか参考適度になります。
また、今回、どんな単語をアーティクルやタイトルに記述されていれば、KPIが向上するのかの選択候補を与えるために、これらの特徴量重要度が高い候補の単語から抽出します
特定の記事から、KPIを増加させるために、なんの単語群を選択すればいいのか
ここまでとても長かったのですが、ここからが本番で、クリエイティブを作る人は、書きかけの記事の単語選択や、表現に迷うことがあります。
一般的に単語や表現は組み合わせで初めて、価値を発揮することが多く、経験則的にはこのようなクリエイティブはKPIが異なるとされています
[もちもち した 美肌 ! 今なら 、 キャンペーン で 送料 無料 !]
[もちもち した 食感 ! 北海道産 、 まんじゅう ! 美味しい !]
liblinearや単純な重回帰では、「もちもち」は単独の特徴量として表現されて、「もちもち」+ 「美肌」 と「もちもち」+「まんじゅう」の組み合わせることで、別の特徴量だと考慮すべき点は見ることができません
Gradient Boosting MachineやDeep Learningなどは、組み合わせ表現の重要度を獲得可能なので、「美容」のクリエイティブを作成している時に、「美肌」という制約が入った状態で、最適などの単語を使うべきかをレコメンド可能になります
KPIを予想するモデルを移動する
$ mv LightGBM_model.txt best-term-combination-search/ $ cd best-term-combination-search/
元となるテキストをベクトル化する
デフォルトでは、学習データセットに用いなかったjin115.comの最新の記事を参照するようにしていますが、適宜必要なデータセットに変えてください
$ python3 make_init.py
モデルで判別するために獲得された単語群を作成する この単語があるから、KPIが変わった、という判別の閾値に用いられている、単語の一覧を得て、その単語群を組み合わせることで、よくなるのか、悪くなるか計算することができます
$ python3 check_importance.py
単語群を利用して、ランダムの組み合わせ表現100,000通りを作成する
レコメンドの候補となる単語群の組み合わせ10万通りを計算して、データセットを作成します
$ python3 calc_combinations.py > dump.dat
前処理で学習したモデルを利用して、KPI増加量が多い単語の組み合わせ表現を、昇順でランキングします
$ python3 upper_calc.py | less
(この例では、コメントするユーザのハッシュ値も予想の重要な特徴量になってしまっているので、名詞のみのモデルでランキングしています)
具体例
やはり、2chねらーとTwitterユーザは仲が悪のか、Twitterネタは炎上しやすい感じでした
三つの単語をレコメンドし、右側の数字のぶんだけ、KPIであるコメント投稿数が上がると期待されると解釈します
articleはコンテンツ中, h1は記事のタイトル中に含まれているべき単語です
article@頂点 article@SCEJ article@バリュー 354.4107576417173 article@マジモン article@東方 article@板 353.46575634371357 article@pr h1@ツイッター民 article@543 348.5449500051823 h1@バカッター article@老害 article@5W 345.9868295939084 article@商業 article@肯定 h1@ツイッター民 337.3307174323563 h1@ファイナルファンタジー15 article@安倍晋三 article@一位 330.16779109936283 article@2月27日 article@年収 h1@ツイッター民 315.97116550315286 article@ネトウヨ article@ただ h1@爆死 313.42247907534056 article@570 article@2013年 h1@ツイッター民 308.77429368376124 article@暗殺 h1@バカッター h1@赤字 304.52876971810906 article@ロゴ article@熊本県 h1@バカッター 302.28776850940653 h1@ソニー article@ガム h1@ツイッター民 294.8744340111921
では、KPIが下がってしまうようなコンテンツの組み合わせにするには、どんな単語にすればいいのでしょうか
article@テキスト article@デュラララ!! article@ドラマ -189.53177862790812 article@tenki h1@黒子のバスケ article@動向 -190.51400300682553 article@気象庁 article@165 h1@プロジェクト -190.59643895049328 h1@配信決定 article@30代 article@コンピュータ -190.85115503750387 article@3月20日 article@グランツーリスモSPORT article@舞台化 -191.62621800299712 article@怪獣 article@太鼓の達人 article@MP -191.65833548081196 article@子会社 article@DMM h1@2012 -192.6149488251317 article@逮捕 article@簡単 h1@2012 -193.43026190229068 article@カオス h1@配信決定 article@机 -194.11086374900992 article@売却 article@ギズモード・ジャパン article@新テニスの王子様 -194.42483360420647 article@ロケットニュース24 article@故郷 article@2005年 -194.87825375720115 h1@配信決定 article@音声 article@オンラインサービス -195.4315454292838 article@情報番組 h1@無料配信 article@よ -196.20890731778456 article@狂気 h1@2012 article@人間関係 -196.5040631720508 article@PS4 article@年寄り h1@2012 -197.5578885851079 article@アイドルマスター ミリオンライブ! h1@C article@Sony Computer Entertainment -198.7143092931767
一部の作品や層を狙った文章にすると、KPIが下がるとかそういうことだと思います
想定する使い方
今回は、記事全文の長文に対して重要な単語のレコメンドをやってみたのですが、それより、短い文章(例えばキャッチコピーや記事のタイトルなど)に部分的に適応するのが筋が良さそうに見えました
jin115.comさんに限らず、クリエイティブの作り方や、組み合わせのレシピなどで美味しくなるなどは、一定の傾向が存在し、それらを獲得することで、何かを最大化するレコメンドシステムは作れることが示せたかと思います
ディープラーニングではなく勾配ブースティングを用いたのは、スパースマトリックの扱いやすさからなので、適応例によっては、ディープラーニングでも同等の仕組みは作れると考えています
膨大にある意思決定のサポートの一側面のみの利用法なので、全てではないし、他のアプローチもありますが、この方法だと考えることが少なく、簡単に適応できます(簡単にできることはとても重要だと思います)
参考文献
Gradient Boosting Machineで特徴量を非線形化
Gradient Boosting Machineで特徴量を非線形化
Practical Lessons from Predicting Clicks on Ads at Facebook
Facebook社のGradient Boosting Machineで特徴量を非線形化して、CTRを予想するという問題の論文からだいぶ時間が立っていますが、その論文のユニークさは私の中では色あせることなくしばらく残っています。
原理的には、単純でGrandient Boosting Machineの特徴量で複数の特徴量を選択して決定木で一つの非線形な状態にして、数値にすることでより高精度でリニアレグレッションなどで予想できるようになります。私の雑な解釈では、GBMがその誤差を最小化しようと試みる時に、複数の特徴量を選んで木を作成するのですが、この時の木がうまく特徴量の相関を捉えて、結果として特徴量の圧縮として働いているという理解です。
では、これは、どのような時に有益でしょうか。
CTR予想はアドテクの重要な基幹技術の一つですが、リアルタイムで計算して、ユーザにマッチした結果を返す必要がある訳ですが、何も考えずに自然言語やユーザ属性を追加していくと、特徴量の数が50万から100万を超えるほどになり、さらに増えると1000万を超えることがあります
GBM系のアルゴリズムの一種であるLightGBMを用いることで、LightGBMで特徴量を500個程度の非線形化した特徴量にして、これ単独でやるより各々の木の出力値をLinear Regressionにかけるだけで性能が同等になるか、向上するとのことです
図示

図1. FBの論文の引用
GBMで特徴量を非線形化して、その非線形になった特徴量の係数をLinear Regressionで計算します
問題設定
映画.comのレビューのテキストを形態素解析してBoWのベクトルを作り、そのベクトル値から、星の数をレグレッションで当てます
単語は多様性があるので、とても高次元になりますが、1. 単純なLinear Regressionと2. LightGBMと3. LightGBMで非線形化+Linear Regressionで比較します
全体の流れ
- 映画.comの映画のレビュー情報を取得します
- レビューの星の数と、形態素解析してベクトル化したテキストのBoWと星の数を表現したペア情報を作ります
- これをそのままLightGBMで学習させます
- LightGBMで作成したモデル情報を解析し、木構造の粒度に分解します
- 2のベクトル情報を作成した木構造で非線形化します
- ScikitLearnで非線形化した特徴でLinear Regressionを行い、星の数を予想します
データセット
作成したコーパスはここからダウンロードができます
1. Linear Regressionのみの精度
Linear Regressionより性能が高くなると期待できるので比較検討します
今回の使用したデータセットは50万程度の特徴量ですので、単純にLinear Regressionで計算したものと比較します
$ ./train -s 11 ../xgb_format iter 1 act 7.950e+06 pre 7.837e+06 delta 1.671e+00 f 9.896e+06 |g| 2.196e+07 CG 2 cg reaches trust region boundary iter 2 act 3.798e+05 pre 3.755e+05 delta 6.685e+00 f 1.946e+06 |g| 8.440e+05 CG 5 cg reaches trust region boundary iter 3 act 2.320e+05 pre 2.300e+05 delta 2.674e+01 f 1.566e+06 |g| 1.298e+05 CG 12 cg reaches trust region boundary iter 4 act 2.481e+05 pre 2.476e+05 delta 1.070e+02 f 1.334e+06 |g| 4.600e+04 CG 28 cg reaches trust region boundary iter 5 act 3.378e+05 pre 3.489e+05 delta 4.278e+02 f 1.086e+06 |g| 4.329e+04 CG 104 iter 6 act 1.306e+05 pre 1.698e+05 delta 4.278e+02 f 7.481e+05 |g| 9.367e+04 CG 180 iter 7 act 4.090e+04 pre 1.129e+05 delta 1.117e+02 f 6.175e+05 |g| 2.774e+04 CG 419
学習が完了しました
$ ./predict ../xgb_format_test xgb_format.model result Mean squared error = 0.785621 (regression) Squared correlation coefficient = 0.424459 (regression)
MSE(Mean Squared Error)は0.78という感じで、星半分以上間違えています
2. LightGBMのみでの精度
LightGBM単体での精度はどうか検討します。
このようなパラメータで学習を行いました。
task = train boosting_type = gbdt objective = regression metric_freq = 1 is_training_metric = true max_bin = 255 data = misc/xgb_format valid_data = misc/xgb_format_test num_trees = 500 learning_rate = 0.30 num_leaves = 100 tree_learner = serial feature_fraction = 0.9 bagging_fraction = 0.8 min_data_in_leaf = 100 min_sum_hessian_in_leaf = 5.0 is_enable_sparse = true use_two_round_loading = false output_model = misc/LightGBM_model.txt convert_model=misc/gbdt_prediction.cpp convert_model_language=cpp
50万次元程度のスパースベクトルなので、numpyなどのアレーにせず、そのままバイナリのLightGBMに投入します
$ lightgbm config=config/train.lightgbm.conf ... [LightGBM] [Info] 47.847420 seconds elapsed, finished iteration 499 [LightGBM] [Info] Iteration:500, training l1 : 0.249542
テストデータに置ける誤差は先ほどより小さく、0.25程度ということになりました
LightGBMでの非線形化の前処理
出力したC++のモデルを非線形化するPythonのコードに変換
$ cd misc $ python3 formatter.py > f.py ...(適宜取りこぼしたエラーをvimやEmacs等で修正してください)
特徴量を非線形化したデータセットに変換
$ python3 test.py > ../shrinkaged/shrinkaged.jsonp
3. LightGBMで非線形化 + Linear Regressionでの精度
$ cd shrinkaged $ python3 linear_reg.py --data_gen $ python3 linear_reg.py --fit train mse: 0.24 test mse: 0.21
testデータセットで0.21の平均絶対誤差と、LightGBM単体での性能に逼迫し、上回っているとわかりました
精度などの比較
単純なACCURACYという意味での精度であれば、以下の関係が成り立っていそうです
LightGBM = LinearRegression(NonLinear) > LinearRegression(Native)
では、最初からLightGBMだけで計算すればいいじゃんという話がありましたが、これは多分、特徴量を非線形化しておいて少ない次元で取り扱うことで、CTR予想を行いすぐ計算結果を返すなどの、用途に向いているのだと思います
コード
コードはこちらにあります。C++のモデルをPythonの決定木の構造に変換するのが大変でした。。。
まとめ
これに極めて特徴量が大きい問題に対して、決定木による非線形化と、非線形化した状態で保存することで、広告を配信する際など、計算時間がかなり短縮できることが期待できます(クリエイティブの特徴量とユーザ行動列の特徴量を別に非線形化して組み合わせてLRで予想するとか)
謝辞
SNSで理論をだらだら述べていた時に、先行して研究を行っていてそのノウハウや本質を伝えてくださった菜園さんに深く感謝しています。
より多角的な指標で検討されているので、ぜひ一読されると良いと思います。
Kerasを使ったGoogle VisionサービスのDistillation(蒸留)
Kerasを使ったGoogle VisionサービスのDistillation(蒸留)
Vision APIをVGGで蒸留する
Vision APIの出力は実はタグの値を予想する問題でしかない
出力するベクトルが任意の次元に収まっており、値の範囲を持つ場合には、特定の活性化関数で近似できる
例えば、Vision APIはメジャーなタグに限定すれば、5000個程度のタグの予想問題であり、5000個程度であればVGGを改良したモデルで近似できることを示す
(2017/11/08 データセットをスクリーニングして、問題のあるデータセット(一定の確率で特定のタグによってしまう)を排除したところ、だいぶ改善しました)
理論
去年の今頃、話題になっていたテクノロジーで、モデルのクローンが行えるとされているものである。
Google VISION APIなどの入出力がわかれば、特定のデータセットを用意することで、何を入力したら、何が得られるかの対応が得られる
この対応を元に、VISION APIの入出力と同等の値になるように、VGG16を学習させる
DeepLearning界の大御所のHinton先生の論文によると、モデルはより小さいモデルで近似することができて、性能はさほど落ちないし、同等の表現力を得られるとのことです[2]
(蒸留を行う上で重要な、仕組みはいくつかあるのですが、KL Divergenceという目的関数の作り方と、softmaxを逆算して値を出すことがポイントな気がしています)
イメージするモデル

図1. クローン対象のモデルをブラックボックスとして、任意のモデルで近似する
論文などによると、人間が真偽値を0,1で与えるのではなく、機械学習のモデルの出力値である 0.0 ~ 1.0までの連続値を与えることで、蒸留の対象もととなるモデルの癖や特徴量の把握の仕方まで仔細にクローンできるので効率的なのだそうです
実験環境
- pixabox.comという写真のデータセット200万枚を利用
- 特徴しては5000個の頻出する特徴を利用
- KL Divergenceではなく、Binary Cross Entropyを利用(Epoch 180時点においてこちらの方が表現力が良かった)
- 事前に200万枚に対してGoogle Cloud Vision APIでデータセットを作成し、Distillationで使うデータセットに変換
- AdamとSGDでAdamをとりあえず選択
- 訓練用に195万枚を利用して、テスト用に5万枚を利用した
モデル
様々なパラメータ探索を行なったが、収束速度と学習の安定性の観点から学習済みのVGG16のモデルを改良して用いるとパフォーマンスが良かった
input_tensor = Input(shape=(224, 224, 3)) vgg_model = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor) for layer in vgg_model.layers[:6]: # default 15 layer.trainable = False x = vgg_model.layers[-1].output x = Flatten()(x) x = BN()(x) x = Dense(5000, activation='relu')(x) x = Dropout(0.35)(x) x = Dense(5000, activation='sigmoid')(x) model = Model(inputs=vgg_model.input, outputs=x) model.compile(loss='binary_crossentropy', optimizer='adam')
結果
スナップショットして250epoch時点の結果を載せる
まだ計算すれば性能は上がりそうである

図2. ざくろ

図3. ビーチと人と馬(馬が検出できていない)

図4. ベトナムの夕日

図5. アステカのデザインパターン

図6. 水と花の合成写真
学習時の注意点
膨大な検証と試行錯誤を行なったのですが、KL Divを最小化するのもいいですが、Binary Cross Entropyの最小化でもどうにかなります
また、分布を真似するというタスクの制約からか、分布を似せようとしてくるので、必然的に頻出回数が多いSitiationに一致していまします。こういう時は単純な力技でデータ増やすこと汎化させているのですが、今回は100万枚を超えるデータセットが必要で大変データ集めに苦労しました(10万枚具体で見積もっていたら全然うまくいかなくて焦りました。。。)
プロジェクトのコード
学習済みのモデル
minioの自宅サーバにおいておきます(常時起動している訳でないので、落ちてることもあります) [models0]http://121.2.69.245:10002/minio/google-vision-distillation/keras-distillation/
使用した学習データセット
データセットを集める
pixabayなどをスクレイピングしたスクレイパーが入っているgithubのプロジェクトです
pixabayはデフォルトではタグ情報がロシア語であってちょっと扱いにくいのですが、これはこれで何かできそうです
(leveldbやBeautifulSoupなどの依存が必要です)
スクレイピング
$ python3 pixabay_downloader.py
Google Visonが認識できるサイズにリサイズする
$ python3 google_vision.py --minimize
GCPのGoogle Visionのキーを環境変数に反映させる(Pythonのスクリプトが認証に使用します)
export GOOGLE=AIzaSyDpuzmfCIAZPzug69****************
Google Visionによりなんのタグがどの程度の確率でつくか計算し、結果をjsonで保存
$ python3 google_vision.py --scan
学習に使用するデータセットを作ります
$ python3 --make_tag_index #<-タグ情報を作ります $ python3 --make_pair #<-学習に使用するデータセットを作ります
学習
任意のデータセットを224x244にして255でノーマライズした状態Yvと、タグ情報のベクトルXvでタプルを作ります タプルをpickleでシリアライズしてgzipで圧縮したファイル一つが一つの画像のデータセットになります
one_data = gzip.compress( pickle.dumps( (X, y) ) )
任意のデータセットでこのフォーマットが成り立つものをdatasetのディレクトリに納めていただき、次のコマンドで実行します
$ python3 distillation.py --train
予想
学習に使用したフォーマットを引数に指定して、predオプションをつけることで予想できます
$ python3 distillation.py --pred dataset/${WHAT_YOU_WANT_TO_PREDICT}.pkl
...
(タグの確率値が表示されます)
蒸留における法的な扱い
参考文献[1]に書いてある限りしか調査していないですが、蒸留や転移学習に関しては法的な解釈がまだ定まってないように見受けられました
既存の学習済みモデルのいわゆるデータコピーではないので,直ちに複製ということはできない。ただし,部分的に利用を行ったり,その結果を模したネットワークを再構築したりといった行為にあたるので,そもそも複製にあたるか否か,元の学習済みモデルの権利者(がもし存在すれば)との間でどのような利益の調整が行われるのか,許諾の要否,元のネットワークに課されていた権利上の制約(例えば,第 47 条の 7 の例外規定におけるデータベースの著作物の複製権の許諾等),といった論点がある。これらがどのように重み付けされて考慮されるかについては,文化的な側面,及び経済的な側面から,制度設計が必要であると考えられる。
ビジネスで使用するのは避けて、当面は、学術研究に留めておいた方が良さそうです。
コード
ライセンス
MIT