勾配ブースティングを利用した、KPIに効く特徴量のレコメンド
勾配ブースティングを利用した、KPIに効く特徴量のレコメンド
近況:おばあちゃんが亡くなった関係で、しばらく更新できませんでした。人間の一生とは改めて有限で、限られた時間で何をどうやるかを意識しないといけないなと思いました
意思決定をサポートする機械学習の必要性
機械学習は、マスメディアの中で語られるまるで人間の置き換えかのように表現されることが多いのですが、利用できる実態としては以下の側面が私が携わる案件で多いです。
- CTR予想など、KPIを自動で場合によっては高速に計算することで、人間が最適な意志決定しやすくする
- 膨大な経験に基づく必要がある一部の職人の仕事で、何がKPIなのかなどの特徴量重要度を把握し、定量的な値で意志決定することで、属人性をなくす
まだ私自身、キャリアとして、そんなに長くない機械学習エンジニアですが、主要な幾つか本質的な要素に還元すると、このようなものであることが多いです
いろんなシステムを作ってきましたが、意外とヒアリングしていると、システムに半自動でいいから意思決定を任せたい(もしくは施策が定量的にどの程度有効なのか知りたい)などが多く見受けられました
IBMのコグニティブコンピューティングの資料を引用しますと、コグニティブコンピューティングのDecision(レコメンド), Discovery(意思決定のサポート)の領域とも無理くり解釈できそうではあります

ワトソンの料理の新しいレシピのレコメンドからの発想
もともと、このKPIを最大化する特徴量群をレコメンドするという考えは、シェフ・ワトソン[1]の全く新しい食材の組み合わせで美味しいと言われているレシピをレコメンドするという機能を幾つかの状況証拠から仮説を立てて、導いたものです
IBMが長らく研究していたテーマとして、意味情報を演算可能にするというお題があったはずですが、これはちょっと別で、機械学習の最小化のアルゴリズムでいくつかこの特徴量とあの特徴量が同時に存在して、ある量以下(または以上)ならば、という膨大なルールセットを獲得し、その獲得した条件式が成立していれば、美味しいはずであるという発想に基づいているかと思います
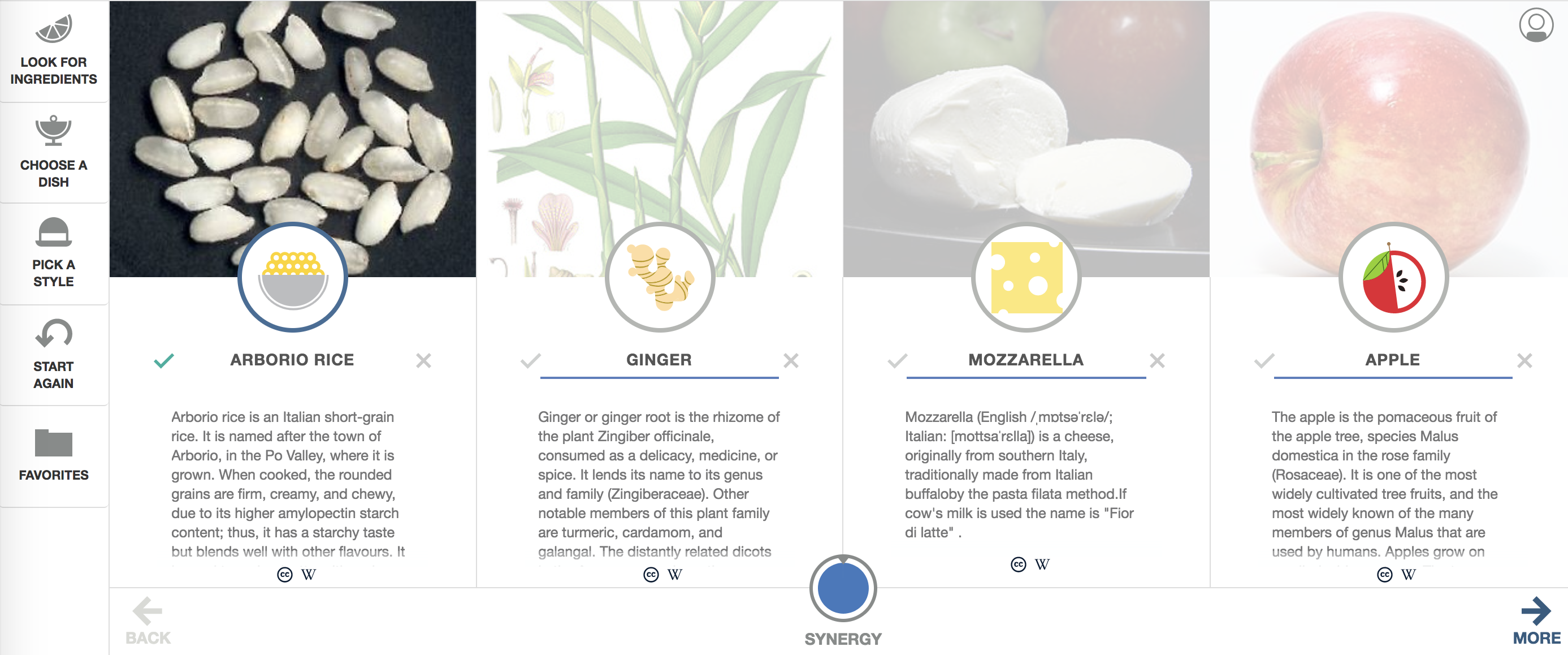
図1. 何品か、最初の条件となる、食品を選んで、他の何品かのレシピを自動でレコメンドします
今回はテキストの作りに着目し、テキストにどのような単語が含まれていたら、KPIの向上が望めるかのシステムを2chまとめサイトに対象にやってみたいと考えています
【実験】jin115.comのコメント数をどんな単語で記述したら数が増えるか予想する
jin115.comのデータセットをzip圧縮で17GByteもダウンロードしてしまったので、何か有効活用できないかと考えていたのですが、難しく、なんともKPIという軸で定量化できないので、 ある記事に対してつく、コメント数を増やすには、どんな単語選択が適切かという軸に切り替えて、分析してみました。
コードはgithubのレポジトリで管理しています
jin115.comでは、2chまとめが流行った時に大量のアクセスを受けていたという背景があり、一気にその時に成長したのですが、今はユーザ数はサチっているように見えます。
各月のユーザのコメント数を累積していくと、このようなグラフを書くことができました(2006年からやっているんですね。。すごい)

前処理
データセットダウンロード
Google Cloud Strageに大容量のスクレイピング済みのデータセットをzip圧縮したものがありので、追試等が必要な方は参照してください。
$ wget https://storage.googleapis.com/nardtree/jin115-20171125/jin115-20171125.zip
htmlコンテンツから必要なarticle, commentの数, 日時, タイトルのパース
ダウンロード済みのhtmlコンテンツから予想の元となる説明変数(article, title, date)と、目的変数であるcomment数をパースします
この捜査自体が極めて重いので、Google Data Strageからもダウンロードできます
$ python3 parser.py --map1
パースしたデータを分かち書きします
分かち書きして、形態素解析して、BoWとしてベクトル表現にできる状態にします
$ python3 wakati.py --verb
LightGBM, XGBoostで機械学習可能なデータセット(train, test)を作成します
まず最初に、予想するとしたKPIであるコメント数を予想するもモデルを構築することを目的とします
そのために、トレインとテストのデータセットを分割して、作成します
$ python3 make_sparse.py --terms # uniq単語をカウント $ python3 make_sparse.py --sparse # train, testデータセットを作成します
LightGBMで学習して、モデルを作成します
一般的に、言語のBoWは単語数に応じたベクトル時原まで拡大されますので、numpyなどで密行列で表現することには向いていません
そのため、デフォルトでスパースマトリックスを扱え、CUI経由で学習できるLightGBMのバイナリを直接実行してモデルを作成します
$ lightgbm config=train.conf
(LightGBMのインストールは、Githubからcloneして、cmake, make & sudo make installでシステムパスに追加しておくと便利です)
特徴量重要度を確認する
Gradient Boosting Machine系の特徴量重要度は、必ずしも、事象を説明する特徴量が支配的に記述されるわけではないのですが、どんな特徴量が効いているのか参考適度になります。
また、今回、どんな単語をアーティクルやタイトルに記述されていれば、KPIが向上するのかの選択候補を与えるために、これらの特徴量重要度が高い候補の単語から抽出します
特定の記事から、KPIを増加させるために、なんの単語群を選択すればいいのか
ここまでとても長かったのですが、ここからが本番で、クリエイティブを作る人は、書きかけの記事の単語選択や、表現に迷うことがあります。
一般的に単語や表現は組み合わせで初めて、価値を発揮することが多く、経験則的にはこのようなクリエイティブはKPIが異なるとされています
[もちもち した 美肌 ! 今なら 、 キャンペーン で 送料 無料 !]
[もちもち した 食感 ! 北海道産 、 まんじゅう ! 美味しい !]
liblinearや単純な重回帰では、「もちもち」は単独の特徴量として表現されて、「もちもち」+ 「美肌」 と「もちもち」+「まんじゅう」の組み合わせることで、別の特徴量だと考慮すべき点は見ることができません
Gradient Boosting MachineやDeep Learningなどは、組み合わせ表現の重要度を獲得可能なので、「美容」のクリエイティブを作成している時に、「美肌」という制約が入った状態で、最適などの単語を使うべきかをレコメンド可能になります
KPIを予想するモデルを移動する
$ mv LightGBM_model.txt best-term-combination-search/ $ cd best-term-combination-search/
元となるテキストをベクトル化する
デフォルトでは、学習データセットに用いなかったjin115.comの最新の記事を参照するようにしていますが、適宜必要なデータセットに変えてください
$ python3 make_init.py
モデルで判別するために獲得された単語群を作成する この単語があるから、KPIが変わった、という判別の閾値に用いられている、単語の一覧を得て、その単語群を組み合わせることで、よくなるのか、悪くなるか計算することができます
$ python3 check_importance.py
単語群を利用して、ランダムの組み合わせ表現100,000通りを作成する
レコメンドの候補となる単語群の組み合わせ10万通りを計算して、データセットを作成します
$ python3 calc_combinations.py > dump.dat
前処理で学習したモデルを利用して、KPI増加量が多い単語の組み合わせ表現を、昇順でランキングします
$ python3 upper_calc.py | less
(この例では、コメントするユーザのハッシュ値も予想の重要な特徴量になってしまっているので、名詞のみのモデルでランキングしています)
具体例
やはり、2chねらーとTwitterユーザは仲が悪のか、Twitterネタは炎上しやすい感じでした
三つの単語をレコメンドし、右側の数字のぶんだけ、KPIであるコメント投稿数が上がると期待されると解釈します
articleはコンテンツ中, h1は記事のタイトル中に含まれているべき単語です
article@頂点 article@SCEJ article@バリュー 354.4107576417173 article@マジモン article@東方 article@板 353.46575634371357 article@pr h1@ツイッター民 article@543 348.5449500051823 h1@バカッター article@老害 article@5W 345.9868295939084 article@商業 article@肯定 h1@ツイッター民 337.3307174323563 h1@ファイナルファンタジー15 article@安倍晋三 article@一位 330.16779109936283 article@2月27日 article@年収 h1@ツイッター民 315.97116550315286 article@ネトウヨ article@ただ h1@爆死 313.42247907534056 article@570 article@2013年 h1@ツイッター民 308.77429368376124 article@暗殺 h1@バカッター h1@赤字 304.52876971810906 article@ロゴ article@熊本県 h1@バカッター 302.28776850940653 h1@ソニー article@ガム h1@ツイッター民 294.8744340111921
では、KPIが下がってしまうようなコンテンツの組み合わせにするには、どんな単語にすればいいのでしょうか
article@テキスト article@デュラララ!! article@ドラマ -189.53177862790812 article@tenki h1@黒子のバスケ article@動向 -190.51400300682553 article@気象庁 article@165 h1@プロジェクト -190.59643895049328 h1@配信決定 article@30代 article@コンピュータ -190.85115503750387 article@3月20日 article@グランツーリスモSPORT article@舞台化 -191.62621800299712 article@怪獣 article@太鼓の達人 article@MP -191.65833548081196 article@子会社 article@DMM h1@2012 -192.6149488251317 article@逮捕 article@簡単 h1@2012 -193.43026190229068 article@カオス h1@配信決定 article@机 -194.11086374900992 article@売却 article@ギズモード・ジャパン article@新テニスの王子様 -194.42483360420647 article@ロケットニュース24 article@故郷 article@2005年 -194.87825375720115 h1@配信決定 article@音声 article@オンラインサービス -195.4315454292838 article@情報番組 h1@無料配信 article@よ -196.20890731778456 article@狂気 h1@2012 article@人間関係 -196.5040631720508 article@PS4 article@年寄り h1@2012 -197.5578885851079 article@アイドルマスター ミリオンライブ! h1@C article@Sony Computer Entertainment -198.7143092931767
一部の作品や層を狙った文章にすると、KPIが下がるとかそういうことだと思います
想定する使い方
今回は、記事全文の長文に対して重要な単語のレコメンドをやってみたのですが、それより、短い文章(例えばキャッチコピーや記事のタイトルなど)に部分的に適応するのが筋が良さそうに見えました
jin115.comさんに限らず、クリエイティブの作り方や、組み合わせのレシピなどで美味しくなるなどは、一定の傾向が存在し、それらを獲得することで、何かを最大化するレコメンドシステムは作れることが示せたかと思います
ディープラーニングではなく勾配ブースティングを用いたのは、スパースマトリックの扱いやすさからなので、適応例によっては、ディープラーニングでも同等の仕組みは作れると考えています
膨大にある意思決定のサポートの一側面のみの利用法なので、全てではないし、他のアプローチもありますが、この方法だと考えることが少なく、簡単に適応できます(簡単にできることはとても重要だと思います)