Kaggleを取り掛かるまでにやったこととと、モチベーションの維持のために必要だったこと
Kaggleを取り掛かるまでにやったこととと、モチベーションの維持のために必要だったこと
わたしの経験した、最初のKaggleの一歩と、実際にKaggleに対するモチベーションがそれなりに加熱するまでにやったことと、息切れしない心の持ち方です。
KaggleがDataScienceに携わるものの価値の可視化の基軸の一つになっていますが、まだ取り掛かれない or 心が折れそう人のために、私に必要だったきっかけと、私が行ったモチベーションコントロールを含めて記します。
まだまだkaggleは弱いですが、継続的に、日々の生活の中に組み入れるまでが大変でした。
目次
既存の機械学習関連の技術者にとってのKaggleの認識のあり方
競技プログラミングは業務コーディングで役に立たないロジックが、Kaggleの業務のデータ分析との関係にも成り立つか
挑み方(ブートアップ)
挑み方(Kernelにキャッチアップし続ける)
挑み方(ツール類)
挑み方(データ構造)
挑み方(魂のあり様)
人間性を捧げよ
1. 既存の機械学習関連の技術者にとってのKaggleの認識のあり方
私が面接する側に立ったこともそれなりにあるし、面接される立場になったこともそれなりにありますが、DSに関わる人のスキルや技能は面接で完全に納得行くまで把握し切ることが、かなり困難だと感じていて、一つの客観的な指標にKaggleが強いことなどのアウトプットが重要視されることがあります。
今までそれなりにやってきたという技術者や企業の意思決定をデータ的な側面で支えてきたデータサイエンティストたちも、過去の実績の資産だけでなく、現実に何ができるかということを、積極的に可視化することが求められている流れをひしひしと感じています。
忙しいから & 自信がないからやらないという言い訳がもはや通用しない所まで来ています。
2. すでに機械学習アルゴリズム(本人の主観で十全に)を知っているがやるべきか
やるべきです。理屈や概要を知っているだけでは、使いこなせないということを嫌というほど体感できるかと思います。
また、競技に向いたデータ分析手段もあり、スピード的、精度的に、高効率なものが多く、短期集中でアウトプットを出す良い訓練にもなるでしょう。
「自分は業績を示す論文があるから」や、「マイペースでやりたい」という人も多いのは承知なのですが、Kaggle的な方法もDSの一側面です。
言い訳している暇があればやったほうがいいように思われます。
3. 競技プログラミングは業務コーディングで役に立たないロジックが、Kaggleの業務のデータ分析との関係にも成り立つか
これも度々、ツイッターやいろんなメディアで話題になる類のお話ですが、競技プログラミングのデータ構造はデータ分析に使えますし、データ分析の構造を体系的に理解させてくれるコンテンツも見たことがないので、私自身は競技プログラミング、コードパズルは一定の意味があったと考えています。
しかし、SIでの開発ではこれらの技能よりわかりやすいオブジェクトを作るとか、ライブラリを綺麗に使うなどの側面で凝ったアルゴリズム的な側面でなく別の技能の側面が求めらます。チームでウォーターフォール開発の中で一人だけ生産性マックスであっても浮いてしまうでしょう。
Kaggleの側面にもそれと似たような問題はあると思います。組織のスタイルによって受け入れられるとか、そうでもないとか。
分析イディオムみたいなものはたくさん身につくので、イディオムで勝負できる案件に昇華できるかが、一つキーポイントな気がします。
4. 挑み方(ブートアップ)
まず、最初に取り掛かるのに、一人でやろうとすると、荷が重いので、だれかを巻き込みましょう。
だれかがやってるとモチベーションがし易いと感じるし、細かいインターフェースの英語で詰まったりしても、聞けば解決するかも知れないというのは案外馬鹿にできない要素であったりします。
Kaggleの課題とは本来なんの関係もないのですが、余計なところにエネルギーをかけないで済むとなると、人間、かなり進捗します。
ネットの世界ではSNSという便利ツールがあります。このツールを利用して、情報を広く集めるのも有力な手段です。
もし御社で、誰かがKaggleをやりたいと騒ぎ出したら、白い目で見るとか、馬鹿にするとかしないで、興味がなくても見守ってあげましょう。
物事を始めるのに必要なエネルギーがそれなりに必要です。彼ら彼女らなりに工夫して、初速を出そうとしているのだと思います。
5. 挑み方(Kernelにキャッチアップし続ける)
KernelというKaggle上で動作するJupyter Notebookがあるのですが、コンペティションが開始されると、いろんな人がKernelを投稿し、精度の良い例を示します。
競技としてのその性格により、コンペ終了間際で、投稿数が増えていき、かつ、精度自体も上がっていきます。
通常のKernelの進歩を考えない、初期だけ参照する例だとこのようにすればある程度の進捗を得ることができます。

図1. Kernelの進歩を考えない進捗モデル
最初の一月ぐらいは私は以下のような戦い方にしてしまって、過剰に消耗してしまいました。
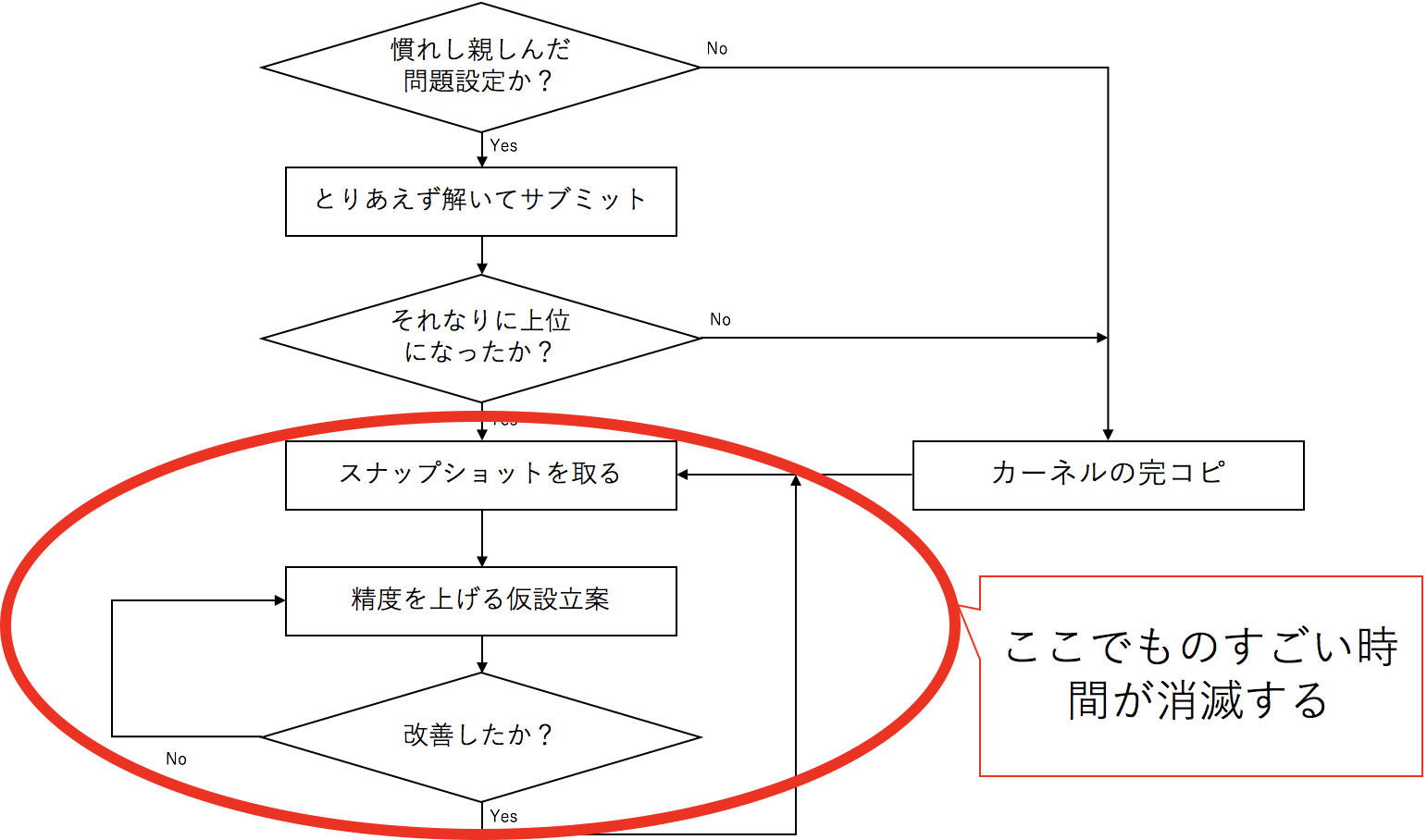
図2. 赤で囲まれたイタレーションを回しているうちに、コンペが終了してしまう
効率の悪い局所ループにハマった状態なので、なんとか、脱出しないといけません。
強化学習の知恵ですが、たまに、乱択を入れることで、ダイバーシティを維持することがあります。そんなこんなで、意識的にこのような経路に変更しました。 (α, βはコンペによって設定される 0 ~ 1の値)

図3. 例えば、外部のリソース参照の経路を確率的につくる
適切に外部の知恵を取り入れることで、進捗が出しやすく、煮詰まるということがなくなるのですが、今までの自分のリズムで進捗していくというスタイルを変更する必要があるので、ここでコストがかかります。
6. 挑み方(ツール類)
PythonかRのどちらを使うかまずは決めましょう。
Pythonでは、データ操作にPandasとNumpyが圧倒的に使われます。
以下のライブラリとソフトウェアをよく見ます
- Python3
- Pandas
- Numpy
- ScikitLearn
- lightgbm
- xgboost
- keras
また、データ量の多いコンペティションもたくさん出題されていて、普通に全量を扱おうとすると、BigQueryなどのSQLが使えるビッグデータ処理基板が必要になります。
MapReduce系のアーキテクチャとは、後述するデータ構造の関係で、行志向と列志向だと、Kernelが列志向のイメージと処理フローなので、行志向のMapReduceとはあまり相性がよくありません(Kaggle TalkinData Detectionでこれで大いに爆死しました。。)
Kernelに登場しない処理方法 - BigQuery
7. 挑み方(データ構造)
Pandasのデータ構造が列志向という方法を採用しており、この方法を理解していると、便利です。
列志向は、分散処理に向かないという側面がありますが、なんだかんだで直感的にデータを操作できて便利です。
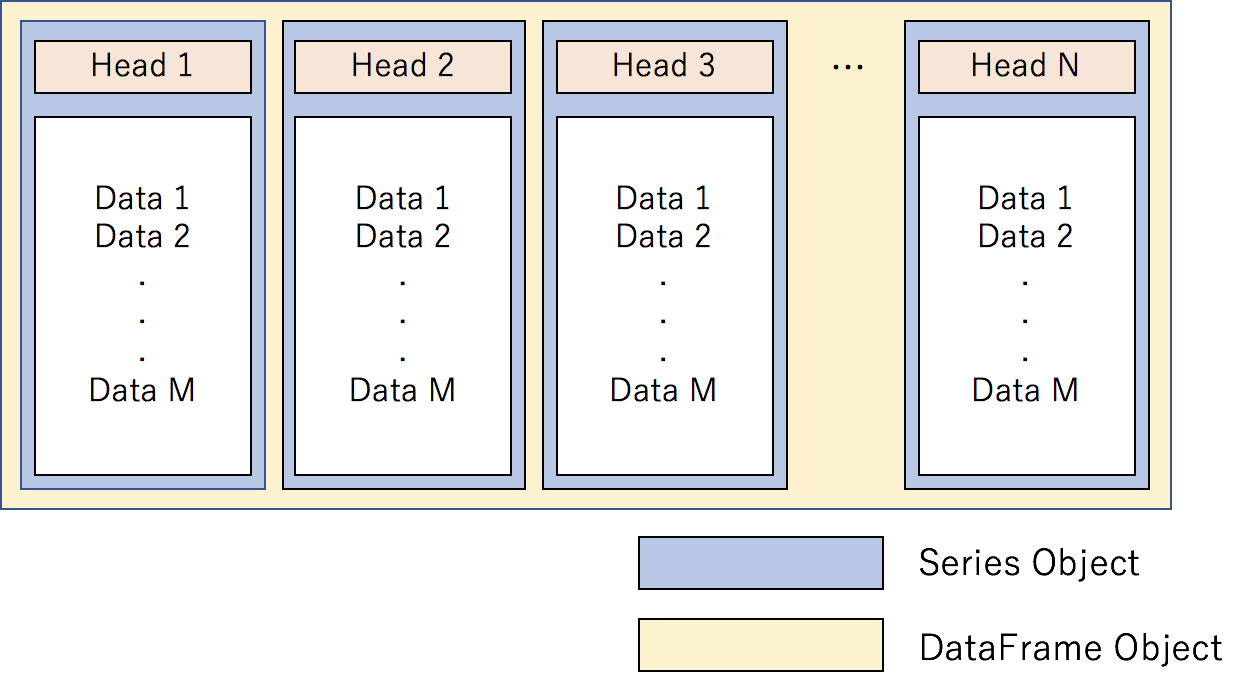
図4. PandasのDataFrameはSeriesのオブジェクトを束ねた列志向になっています
列志向は、Pandas作者のWes McKinnyがよく使う方法で、Apache Arrowなどの処理基板方式を横断したDataFrameを推進していらっしゃいます。
なんらかのKeyを必要としない処理方式なので、Map ReduceなどKeyをハッシングして、大規模分散する発想とは違ったものです。
幾つかプリミティブな動作を示します。これらの組み合わせて殆どのデータマニピュレーションが可能になります。
KaggleのOpenDataのDonorsChoose.orgのドナーのデータセットの例で示します。

図5. KaggleのDonorDataset
pandasのDataFrameをcolumn名をListで投入して、スライシングすると、DataFrame Objectが帰ります
dfslice = df[ ['Donor ID', 'Donor City'] ] # カラム名 Donor ID, Donor Cityでスライスする(スライスされたDataFrameが帰る) isinstance(dfslice, pd.DataFrame) >> True
今度はDataFrameをcolumnをstrで指定して、スライシングすると、Series Objectが帰ります
donor_series = df[ 'Donor ID' ] # カラム名 Donor IDのSeriesが帰る isinstance(donor_series, pd.Series) >> True
Seriesに対する操作は、変換関数を定義して、変換することができます。
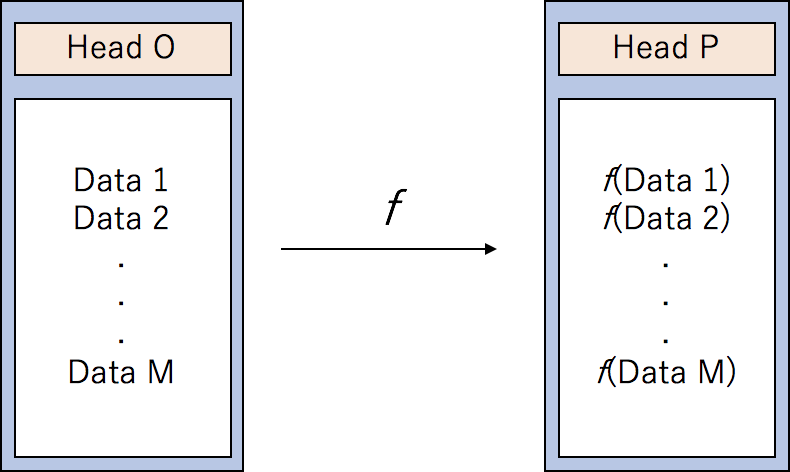
図6.
ZIP Codeをintに変換でき、かつ、偶数なら2倍し、奇数ならばそのままで、文字列ならば、-1にする例です。
def f(x): try: x = int(x) if x%2 == 0: return x*2 else: return x except Exception as ex: return -1 df['Donor Zip'] = df['Donor Zip'].fillna(0) df['Donor Zip'] = df['Donor Zip'].apply(lambda x:f(x)) df.head()
図7. 変換後のデータフレーム
Pandasドキュメントが不足しているのが、groupbyです。groupbyは特定のキーで小さなデータフレームに分割して、共通のキーの中で様々なオペレーションができます。
gp = dfslice.groupby('Donor City') isinstance(gp, pd.core.groupby.DataFrameGroupBy) # パッケージの名前空間からしてわかりにくい... >> True

図8. 設定したキーで小さいDataFrameで分割されてGroupByで更にまとめている
Pandasのgroupbyを利用して、indexで分散して、小さいDataFrameを作成して、multiprocessingを行うこともできます。
import concurrent.futures df['index'] = df.index df['distribute'] = df['index'].apply(lambda x: x%16) dfs = [ _df for key, _df in df.groupby('distribute') ] def pmap(df): # do something. pass with concurrent.futures.ProcessPoolExecutor(max_workers=16) as exe: exe.map(pmap, dfs)
8. 挑み方(魂のあり様)
多少なりとも機械学習に自己のアイデンティティを置いている人は、得意分野以外のフィールドで評価されるリスクを避けようとする心理が働くかと思います。
ここで、少し落ち着いて見ましょう。そのように評価されてあなた自身の価値は毀損しますか? 周りの人をイメージすると良いです。
少なくとも、新しいことにチャレンジしてうまくいかないことが原因で見下されるような場合、その組織は新しい必要な投機を認める文化が醸造されていません。そのような文化体系が支配的であれば、私はその組織に在籍する必要がないように思います。
また、必ず成功しようという意気込みからか、勝利を確実にするためにリソースを投下し続けるの問題でして、人間、できることには限界があり、生活のQoLが下がらないように調整する必要があります。
自己のプライドや主観的な価値の軸を、メタ的な認知である程度自由に動かせることが、必要になってきます。
メタ認知の一種を行うと良いでしょう。
9. 人間性を捧げよ
最近流行り(一部界隈だけ?)の「人間性を捧げよ」について、個人の意見の感想を述べさせてください。
私は「ダークソウル」と「ダークソウル3」のゲームが好きで、人間性という曖昧なもの(実態は何かわからない)が、この物語でキーになっています。

図9. ダークソウルでの人間性。謎の影で、アイテムであり、人間らしさ(正気度のようなパラメータでもある)
「人間性を捧げよ」は、ダークソウル1のキャッチフレーズで、ものすごい難しいゲームなのですが、ボス戦で、体力の削り合いみたいな事になってしまします。
まともにプレイしていると死にまくって、攻略ができないのですが、「人間性」というアイテムを消耗すると、HPが全回復して、ボスと殴り合いを継続できて、人間性でゴリ押しすることも可能です。
この人間性はゲーム中で限られた個数しか取得することができなくて、人間性を消耗すると、ストーリーをすすめることができなくなって、実質上、積んでしまいます。
C++を勉強してたときはものすごい勉強をして覚えたのですが、まさしく、人間性を捧げて、通常の安定した生活を遺棄して、効率のために、様々な最適化を行う努力をしました。
強い人が言う、「人間性を捧げてください」は、まさしくこのようなことだと思います。
やりすぎると病気になったり、精神がおかしくなり、人生というゲームが積んでしまうので、人間性を消費するタイミングはよく考えてください。