dask.distributedで分散処理
dask.distributedで分散処理
dask.distributedの使い方と、具体例集です
dask.distributedの簡単な理解
一種の分散処理フレームワークになっており、便利です。
ドキュメントやgithubはdaskからdask.distributedは分割されており、DataFrameの取扱以外のより汎用的な分散処理を含んでいるようです。
Celeryとかでもやったことをがあるのですが、dask.distributedはRemote Procedureのそれよりまともでより整理された方法で、concurrent.futureのリモート版とも考えられます。

dask.distributedのインストール
pip経由でのdaskのインストール
$ sudo pip3 install dask $ sudo pip3 install distributed
ubuntuでのインストール
注:パッケージが微妙に古くてpip経由の方がいいです
$ sudo apt install python3-distributed
Dask SchedulerとWorkerのセットアップ
Schedulerは分析を実行するマシン、クライアントマシンなど任意のマシンでいいはずです
(今回はschedulerを起動するマシンは192.168.14.13のIPアドレスを持つとしています)
$ dask-scheduler Start scheduler at 192.168.14.13:8786
portのチェック
$ nc -v -w 1 192.168.14.13 -z 8786
Workerは命令を受け実際に計算するマシンなので、別のマシンになります
${SCHEDULER}にはschedulerを起動したマシンのIPが入ります
nprocsオプションで最大のworkerでの並列数(同時に関数が走る数)を指定できます
$ dask-worker ${SCHEDULER}:8786 --nprocs 12
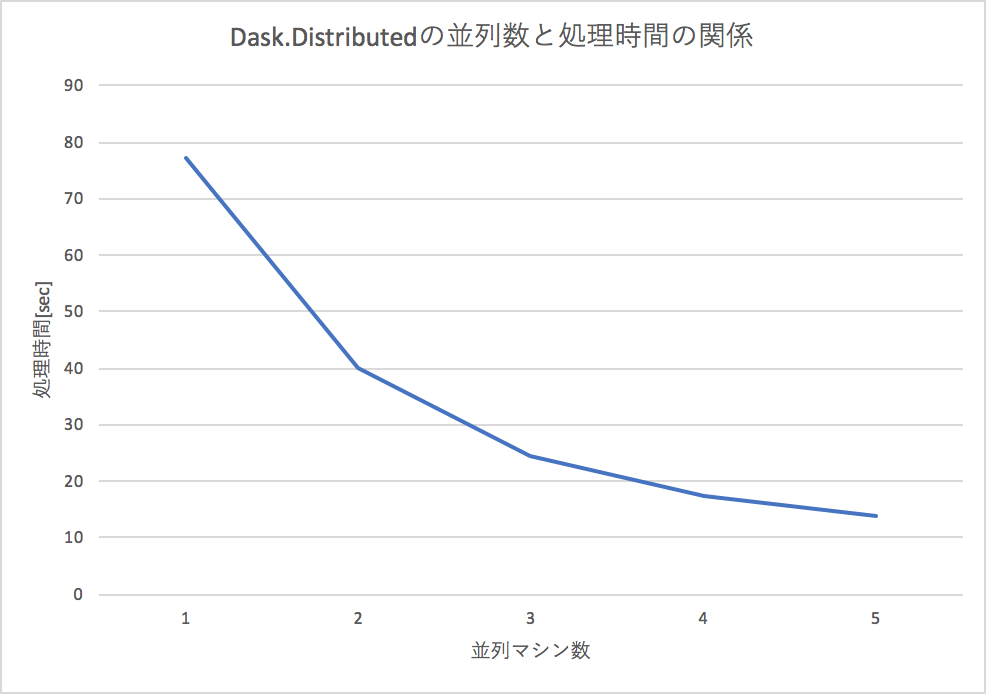
Dask.Distributedの並列マシン数と、速度の関係
下記にある簡単な足し算を並列マシン(worker数の増加)でやろうとすると、処理時間がほぼ反比例の関係で下がるので、効率的に分散処理できていることが確認できます。
分散した命令の結果を受け取る2つの方法
clientにmapされた命令はschedulerが管理して分散処理されますが、内部で、マシン台数かに分割されており、速度的には、一気に結果を見る(gather)のも、個別にみる(result)のもあまり変わりがないようです。
gatherという関数で一気に集められますが戻り値が多いときには、オンメモリにするのが難しいので、挙動が不安です。
L = client.map(inc, range(1000)) ga = client.gather(L)
resultで一個一個取っていく方法は、一件の処理結果のみ返すので、メモリ節約にはなりそうです
L = client.map(inc, args) for l in L: print(l.result())
例に用いたコード
簡単な例:数字を増やすだけ
簡単な命令で、数字を足し合わせて行くだけのプログラムですが、100回引数を変えて行おうとすると、計算時間がかかります。
今回、5台のマシンで一台あたり12並列数で行うので、合計60並列で処理します。
ClientでschedulerのIPアドレスとportを指定して、以下のようなコードを実行するだけで、複数のマシンで並列計算をすることができます。
from distributed import Client client = Client('192.168.14.13:8786') def inc(x): for i in range(10000000): x += i return x L = client.map(inc, range(1000)) ga = client.gather(L) print(ga)
複雑な例:機械学習のモデルのグリッドサーチでも便利
機械学習のパラメータを少しずつ変えながらもっとも、パフォーマンスが良いパラメータを総当りで探すグリッドサーチというものあって、マシンパワーでゴリ押ししてしまうのが都合がいいのです。
複数台のworkerでグリッドサーチさせると、そのマシンの台数分だけ減らせます
dask.mllibを使うとscikit-learnをラップして使うことができますが、任意のライブラリでも動かしたいので、特にdask.mllibは使いません
代表的なUCIのadult incomeデータセットでランダムフォレストでパラメータを2x10x10x15=3000通りという膨大なパラメータサーチであっても、割と早く終わらせることができます。
以下のコードの例では、パラメータの組み合わせを作って、分散処理で評価させています。
関数doはworkerで実行されて、ホームディレクトリ以下のデータセットを読み込んで、引数に与えられたRandomForestのパラメータを適応して学習し、テストデータでの精度を見ています。
def do(param): dataset = pickle.load(open(f'{os.environ["HOME"]}/dataset.pkl', 'rb')) Xs, ys, Xst, yst = dataset criterion, n_estimators, max_features, max_depth = param model = RandomForestClassifier(n_estimators=n_estimators, criterion=criterion, max_features=max_features, max_depth=max_depth) model.fit(Xs, ys) ysp = model.predict(Xst) acc = accuracy_score(yst, ysp) print(acc) return [acc, list(param)] params = [] for cri in ['gini', 'entropy']: for n_esti in range(5,15): for max_features in range(10,20): for max_depth in range(4, 20): params.append( (cri, n_esti, max_features, max_depth) ) L = client.map(do, params) ga = client.gather(L)
adult incomeのデータを学習可能かデータに変換
$ python3 parse-adult.py
出力されたdataset.pklを各workerのホームディレクトに配置
関数の引数に学習用のデータを含めると、遅くなったり、警告がでたりするので、大規模なデータの際はscpで転送する、S3, GCSを利用するなどが良いようです。
workerの台数で分散処理してグリッドサーチ
$ time python3 adult.py ... real 2m24.923s user 0m5.950s sys 0m0.951s
10分以上かかる処理が2分半程度に圧縮できました!
progress barの表示
client.map, client.submitをprogress関数でラップすることで、進捗を確認することができます
L = client.map(do, params) progress(L) # このようにする ga = client.gather(L)

dask.distributedで注意すべき点
dask.distributedで関数の引数に大きすぎるデータ(100MByte)を超えるものを投入すると警告が出るし、転送も早くありません。
そのため、なんらかローカルで対象となるデータを共有している必要があり、scpでファイル転送、HDFSやS3, cloudstrageなどとは相性がよい設計です。
S3とかに格納されchunkされたデータを一気に処理するときなど、便利そうです
金銭的な比較
今現在、私の個人サーバは6core 12threadのRyzen 1600Xが5台あって、30core 60threadで動作します。
2018/03現在、これはおおよそ2万円なので、10万円程度でこの仕組が購入できたことになります。
同等のスペックであるEpyc 7551pは$2100なので、おおよそ20万円で、半額程度で手に入れることができました。
もちろん、分散させないで一大のマシンで処理するメリットとかあると思うのですが、こんな大規模計算は稀だし、必要なときにdask-workerを立ち上げてクラスタに組み込めるのはメリットです。
Dask(+Dask.Distributed)の使い所
Apche Sparkと競合するような位置づけですが、Daks.Distributedのその簡単にデプロイできることと、Apache Sparkを用意するまででもないときとかよいんではないか、みたいに言われているようです。
私は、HadoopやDataFlow(Apache Beam)が結構好きで得意なので、Sparkをあんまり使わないですが、ここまで大げさに分散処理する必要が無いときにDask(+Dask.Distributed)は良さそうですね。