実践的な分散処理を利用して処理を高速化
実践的な分散処理を利用して処理を高速化
GCPやAWSで膨大な計算を行う際に、オーバーヘッドを見極めて、大量のインスタンスを利用し、半自動化して、より効率的に運用するテクニックです。
Kaggle Google Landmark Recognition + Retrievalで必要となったテク
Kaggleでチームを組んで皆さんのノウハウと勢いを学ぶべく、KaggleのGoogle Landmark RecognitionとRetrievalのコンペティションにそれぞれチームで、参加しました。
メンツは、キャッシュさん、yu4uさん、私という激強のお二人に私が計算リソースの最適化で参加しました。画像のことはディープ以降の知識レベルであったので、大変勉強になったコンペです。結果は銀メダル2個です。
「ディープの特徴量」 + 「局所特徴量」の両方を取り出し、マッチングを計算するという問題で、これが大量の画像に対して適応しようとすると、とても重いものでした。
これを様々な計算リソースを投入し、並列で計算した方法がかなり極まっていたのと、これは知らないと難しいかも、、、と思い、よい機会なのでまとめました。
大量のクラウドの一時的なインスタンスをかりて、SSHFSというファイルシステムで一つのマシンをマウントし、各インスタンスに処理の命令を送り、オーバーヘッドを見極めて、アルゴリズム的改善を行い、改善した処理プロセスを行う、というPDCAのような流れをおこうなのですが、各要素について説明したいと思います。
目次
- ファイルシステム
- GCP Preemtipbleインスタンスを用いた効率的なスケールアウト
- MacBookからGCPのインスタンスに命令を送る
- Overheadを見極める
- Forkコスト最小化とメモ化
- まとめ
1. ファイルシステム:SSHFSがファイルの破損が少なくて便利
sshfsはssh経由で、ファイルシステムをマウントする仕組みですが、安定性が、他のリモート経由のファイルシステムに対して高く、一つのハードディスクに対して、sshfs経由で多くのマシンからマウントしても、問題が比較的軽微です。
また、ホストから簡単に進捗状況をチェックすこともできます。
この構造のメリットは、横展開するマシンの台数に応じて早くできることと、コードを追加で編集することなく、分散処理できます。
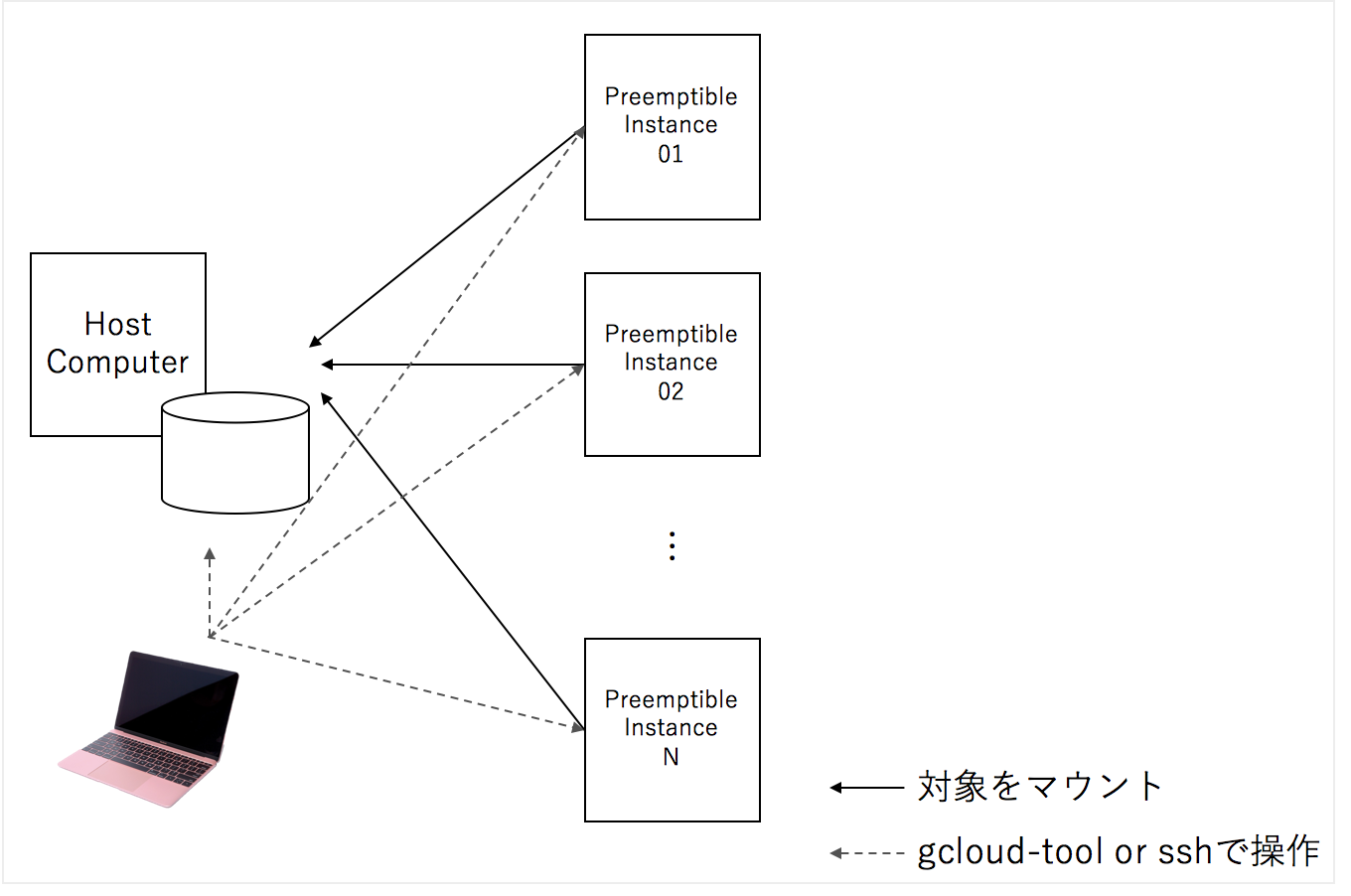
図1.
処理粒度を決定して、処理したデータはなにかキーとなる値か、なければ処理したデータのhash値でファイルが処理済みかどうかを判断することで、効率的に分散処理することtができます。
sshfs上の処理粒度に対してすでに、処理済みであれば、処理をスキップします。
(sshfs上で行ったものは二度目はファイルが共有され、二度目は、処理されないので、効率的に処理できます)
from pathlib import Path import random from concurrent.futures import ProcessPoolExecutor as PPE def deal(path): target = Path( f'target_dir/' + str(path).split('/').pop() ) if target.exists(): # do nothing return # do some heavy process target.open('w').write( 'some_heavy_output' ) paths = [path for path in Path('source_dir/').glob('*')] random.shuffle(paths) # shuffle with PPE(max_workers=64) as exe: exe.map(deal, paths)
2. GCP Preemptible Instance(AWSのSpot Instance)を用いた効率的なスケールアウト
計算ノードは、非同期で運用できるので、途中で唐突にシャットダウンされても問題がないです。そのため、安いけどクラウド運営側の都合でシャットダウンされてしまう可能性があるが、1/10~1/5の値段程度に収まるGCP PreemptibleインスタンスやAWS Spotインスタンスを用いることができます。
Preemptibleインスタンスはgcloudコマンドで一括で作成できますが、このようにPythonなどのスクリプトでラップしておくとまとめて作成できて便利です。
Preemptible インスタンスをまとめて作成
import os type = 'n1-highcpu-64' image = 'nardtree-jupyter-1' for i in range(0, 3): name = f'adhoc-preemptible-{i:03d}' ctx = f'gcloud compute instances create {name} --machine-type {type} --image {image} --preemptible' os.system(ctx)
このスクリプトは、自分で作成した必要なライブラリがインストールされた状態のイメージ(nardtree-jupyter-1)からハイパフォーマンスのインスタンスを3台作成します。
3. MacBookからGCPのインスタンスに命令を送る
google cloud toolをインストールし設定することで、GCPのインスタンスに対して命令(コマンド)を送ることができます
Premptible インスタンスに必要なソフトをインストールして、sshfs経由でマウント
クライアントマシン(手元のMacBookなど)から、コマンドを実行させることができます。
このオペレーションのなかに、手元のマシンから任意の前処理,学習のスクリプトを実行することもできます。
(GCP_NAME, GCP_KEY_NAMEは手元のパソコンの環境変数に設定しておくとよいです)
import os GCP_NAME = os.environ['GCP_NAME'] GCP_KEY_NAME = os.environ['GCP_KEY_NAME'] names = [f'adhoc-preemptible-{i:03d}' for i in range(0, 3)] # commandsのところに任意の処理を書くことができます commands = [ 'sudo apt update', \ 'sudo apt-get install sshfs', \ 'mkdir machine', \ f'sshfs 35.200.39.32:/home/{GCP_NAME} /home/{GCP_NAME}/machine -o IdentityFile=/home/{GCP_NAME}/.ssh/{GCP_KEY_NAME} -o StrictHostKeyChecking=no' ] for name in names: for command in commands: base = f'gcloud compute ssh {GCP_NAME}@{name} --command "{command}"' os.system(base)
4. Overheadを見極める
高速化の余地があるプログラムの最適化はどうされていますでしょうか
私は、以下のプロセスで全体のプロセスを最適化しています。


図2.
図2の例では、CPUは空いており、コードとこの観測結果から、DISKのアクセスが間に合ってないと分かります。オンメモリで読み込むことや、よりアクセスの速いDISKを利用することが検討されます。
5. Forkコスト最小化とメモ化
マルチプロセッシングによるリソースの最大利用は便利な方法ですが、spawn, fork, forkserverの方法が提供されています。
使っていて最もコスト安なのはforkなのですが、これでうまく動作しないことが稀にあって、spawnやforkserverに切り替えて用いることがあります。spawnが一番重いです。
forkでは親プロセスのメモリ内容をコピーしてしまうので、大きなデータを並列処理しようとすると、丸ごとコピーコストがかかり、小さい処理を行うためだけにメモリがいくら高速と言えど、細かく行いすぎるのは、かなりのコストになるので、バッチ的に処理する内容をある程度固めて行うべきです。 cent

例えば、次のランダムな値を100万回、二乗するのをマルチプロセスで行うと、おおよそ、30秒かかります。
from concurrent.futures import ProcessPoolExecutor as PPE import time import random args = [random.randint(0, 1_000) for i in range(100_000)] def normal(i): ans = i*i return ans start = time.time() with PPE(max_workers=16) as exe: exe.map(normal, args) print(f'elapsed time {time.time() - start}')
$ python3 batch.py elapsed time 32.37867593765259
では、単純にある程度、データをチャンクしてマルチプロセスにします。
すると、0.04秒程度になり、ほぼ一瞬で処理が完了します
これはおおよそ、もとの速度の800倍です
from concurrent.futures import ProcessPoolExecutor as PPE import time import random data = [random.randint(0, 1_000) for i in range(100_000)] tmp = {} for index, rint in enumerate(data): key = index%16 if tmp.get(key) is None: tmp[key] = [] tmp[key].append( rint ) args = [ rints for key, rints in tmp.items() ] def batch(rints): return [rint*rint for rint in rints ] start = time.time() with PPE(max_workers=16) as exe: exe.map(batch, args) print(f'elapsed time {time.time() - start}')
$ python3 batch2.py elapsed time 0.035398244857788086
メモ化、キャッシュを利用する
同じ内容が出現し、結果を保存できる場合、計算の多くを共通で占める箇所を、特定のキーで保存しておいて、再利用することで、高速に処理することができます。
特定の入力の値を10乗して、返すというあまりない問題ですが、わかりやすいので、これで示すと、チャンクして処理するものが、このコードになり、4秒程度かかります。
import time import random import functools data = [random.randint(0, 1_000) for i in range(10_000_000)] tmp = {} for index, rint in enumerate(data): key = index%16 if tmp.get(key) is None: tmp[key] = [] tmp[key].append( rint ) args = [ rints for key, rints in tmp.items() ] def batch(rints): return [functools.reduce(lambda y,x:y*x, [rint for i in range(10)]) for rint in rints ] start = time.time() with PPE(max_workers=16) as exe: exe.map(batch, args) print(f'elapsed time {time.time() - start}')
$ python3 batch2.py elapsed time 3.9257876873016357
これをメモ化して、ある程度の最適化を入れると、倍以上の速度になります
from concurrent.futures import ProcessPoolExecutor as PPE import time import random import itertools data = [random.randint(0, 1_000) for i in range(10_000_000)] tmp = {} for index, rint in enumerate(data): key = index%16 if tmp.get(key) is None: tmp[key] = [] tmp[key].append( rint ) args = [ rints for key, rints in tmp.items() ] def batch(rints): mem = {} result = [] for rint in rints: if mem.get(rint) is None: mem[rint] = itertools.reduce(lambda y,x:y*x, [rint for i in range(10)] ) result.append( mem[rint] ) return result start = time.time() with PPE(max_workers=16) as exe: exe.map(batch, args) print(f'elapsed time {time.time() - start}')
$ python3 batch3.py elapsed time 1.4659481048583984
5.5 コード
6. まとめ
並列処理はMapReduceという分析スタイル以外のものもたくさん存在し、微妙な勘所の最適化がないとそもそも目的に対して間に合わないということも十分にありえます。
sshfsを共通のファイルシステムとして持ち、Preemptibleインスタンスをたくさん用意して、 gcloudで任意のコマンドを送信することで、一つの問題を膨大な計算リソースで処理することができるようになります。
計算量での押し切りは、最後に粘りがちになるえる技能でもあるので、そこそこ重要なのだと思います。