K8Sで機械学習の予想システムを作成
K8Sで機械学習の予想システムを作成
目次
- 機械学習の最小粒度としてのDocker, Dockerのデプロイ先としてのk8s
- テキストを評価するAPIのDockerコンテナの作り方
- DockerコンテナのGoogle Cloud Container Registryへの登録
- K8Sへのデプロイ
- 実際にアクセスする
- まとめ
機械学習の最小粒度としてのDocker, Dockerのデプロイ先としてのk8s
コンテナのオーケストレーションツールがk8sが他のツールを押しのけて、優位にたった状況からしばらく経過し、ドキュメントやユースケースが揃ってきました。
GCPではコンテナを使ったデプロイメントサービスはKubernetes Engineがデフォルトであり、WebUIやCUIでの操作例を示したドキュメントも充実してきました。
k8sは、ローリングリリースが簡単にできたり、分析者からDocker Fileやコンテナが適切に受け渡しが開発者に行われれば、デプロイまでの時間的労力的消耗を最小化できたりします。
また、Micro Serviceのデザインパターンとして、Dockerが一つの管理粒度になり、そこだけで閉じてしまえば、自分の責任範囲を明確にし、役割が明確になり、「分析 -> モデルの評価&作成 -> IFの定義 -> コード作成 -> Dockerに固める」というプロセスに落とすことができ、進捗も良くなります。
今回はjson形式で日本語の自然言語を受け取り、映画のレビューの星がいくつなのがを予想するトイプロブレムをk8sに実際にデプロイして使ってみるまでを説明します。
今回のk8sのデザインはこのようなスタイルになります。

テキストを評価するAPIのDockerコンテナの作り方
トイプロブレムの予想モデルの要件
- 任意のテキストをhttp経由でjsonを受け取る
- テキストを分かち書きし、ベクトル化する
- ベクトル化した情報に基づき、テキストが映画レビューならば、レビューの星何個に該当するか予想する
- 予想した星の数をhttp経由でjsonで返却する
- 以上の挙動をする仕組みをDockerコンテナとして提供する
HTTPサーバは私の以前のJSONでサーバクライアント間のやりとりのプロジェクトを参照しています。
予想システムは映画.comさまのコーパスを利用して、LightGBMでテキストコーパスから星の数の予想を行います。学習と評価に使ったスクリプトとコーパスはこちらになります。
Dockerコンテナに集約する
以前作成した何でもごった煮Dockerがコンテナがあり、それを元に編集して作成しました。
本来ならば、Docker Fileを厳密に定義して、Docker Fileからgithubからpullして、システムの/usr/binに任意のスクリプトを配置する記述をする必要があります。
それとは別に、アドホックなオペレーションをある程度許容する方法も可能ではあり、Dockerの中に入ってしまって、様々な環境を構築して、commitしてしまうのもありかと思っています(というか楽ですので、それで対応しました)
ベストプラクティスは様々な企業文化があるので、それに従うといいでしょうが、雑な方法についてはこちらで説明しているので、参考にしていただければ幸いです。
作成したDockerコンテナはこちら
動作はこのようにローカルでも行えます。
$ docker pull nardtree/lightgbm-clf $ docker run -it nardtree/lightgbm-clf 40-predict.py
挙動のチェック
ポジティブな文を投入してみる
$ curl -v -H "Accept: application/json" -H "Content-type: application/json" -X POST -d '{"texts":"すごい!最高に興奮した!楽しい"}' http://localhost:4567/api/1/users
{"score": 4.77975661771051}
(星5が最高なので、ほぼ最高と正しく予想できている)
ネガティブな文を投入してみる
$ curl -v -H "Accept: application/json" -H "Content-type: application/json" -X POST -d '{"texts":"この映画は全くだめ、楽しくない。駄作"}' http://localhost:4567/api/1/users
{"score": 1.2809874000768104}
(星1が最低と、正しく予想できている)
DockerコンテナのGoogle Cloud Container Registryへの登録
Cloud Container Registryへの登録は、タグが、asia.gcr.io/${YOUR_PROJECT_NAME}/${CONTAINER_NAME}となっている必要があるので、
このようにコミットして、実行中のコンテナに対して、別のタグを付けます。
$ docker commit 44f751eb4c19
sha256:5a60e4460a156f4ca2465f4eb71983fbd040a084116884bcb40e88e3537cdc38
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
<none> <none> 5a60e4460a15 2 minutes ago 8.39GB
...
$ docker tag 5a60e4460a15 asia.gcr.io/${YOUR_PROJECT_NAME}/${CONTAINER_NAME}
gcrへコンテナのアップロード
$ gcloud docker -- push asia.gcr.io/${YOUR_PROJECT_NAME}/${CONTAINER_NAME}:latest
今回は、CONTAINER_NAMEはlightgbm-clfとしました
※docker hubに置いてあるので参考にしてください
K8Sへのデプロイ
K8Sへのデプロイは、コマンドだと、デプロイ時の進捗の情報が充分に見れないのでWebUIで行う例を示します。
GCPのKubernetes Engineにアクセスし、クラスタを作成します。
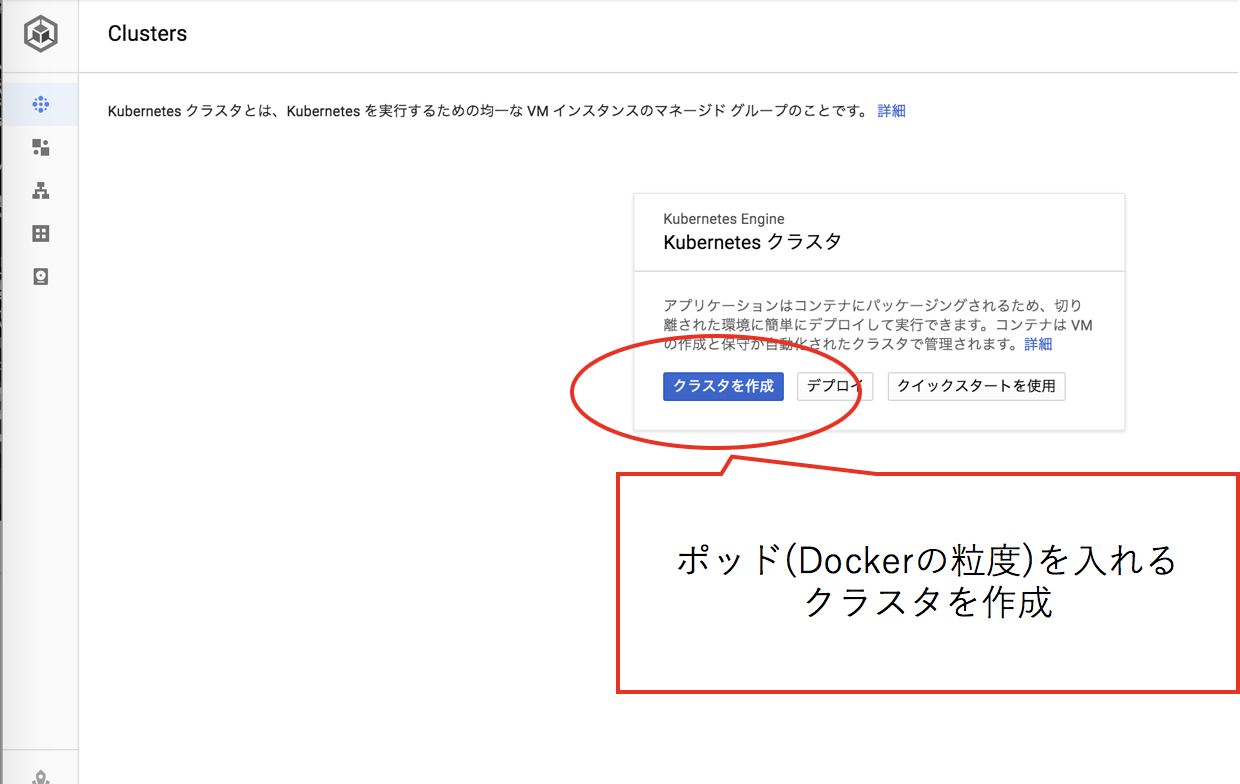
Hello World程度であれば少ないリソースでいいのですが、少し余裕を持って多めのリソースを投下します。
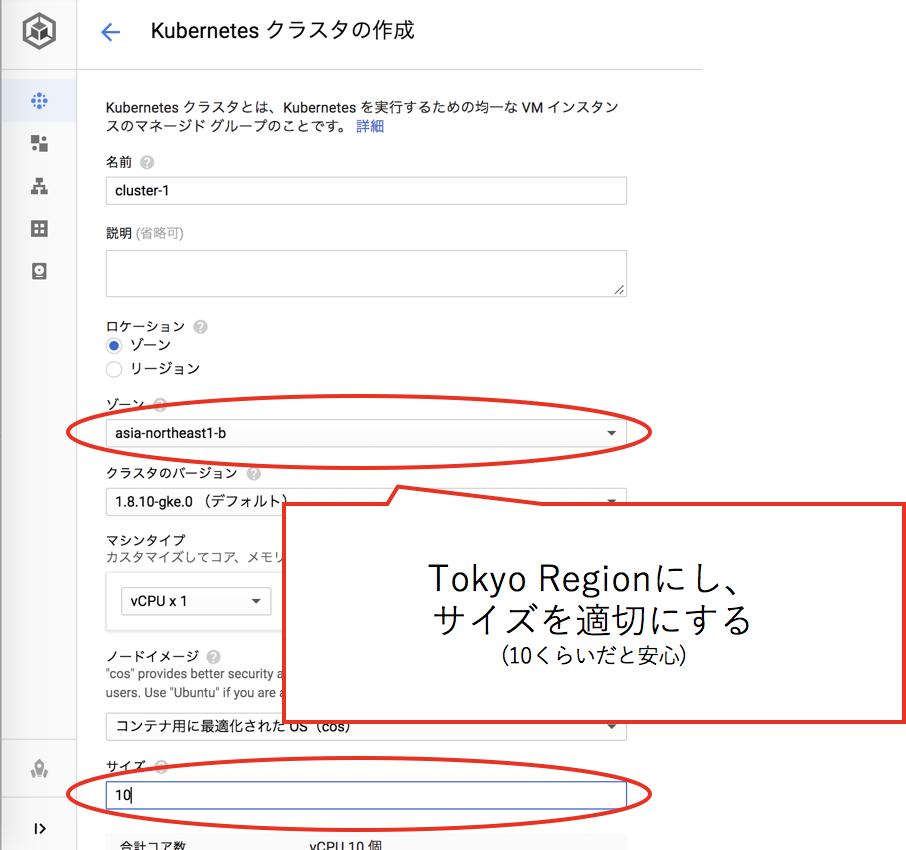
クラスタの作成にはしばらくかかるので、しばらく待ちます。
コンテナレジストリに登録したご自身のDockerコンテナを指定し、このコンテナのサービスの実行に必要な引数を入力します。
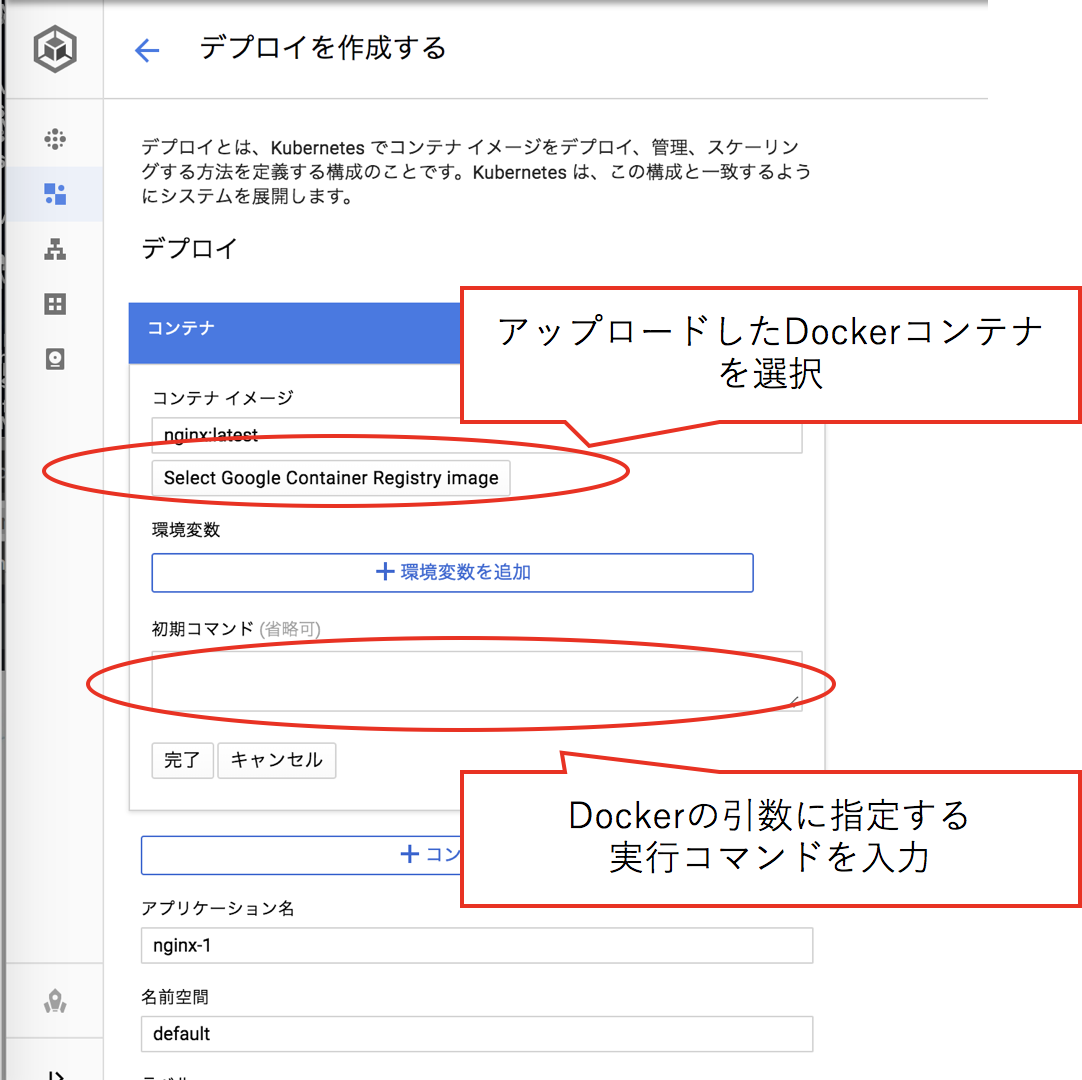

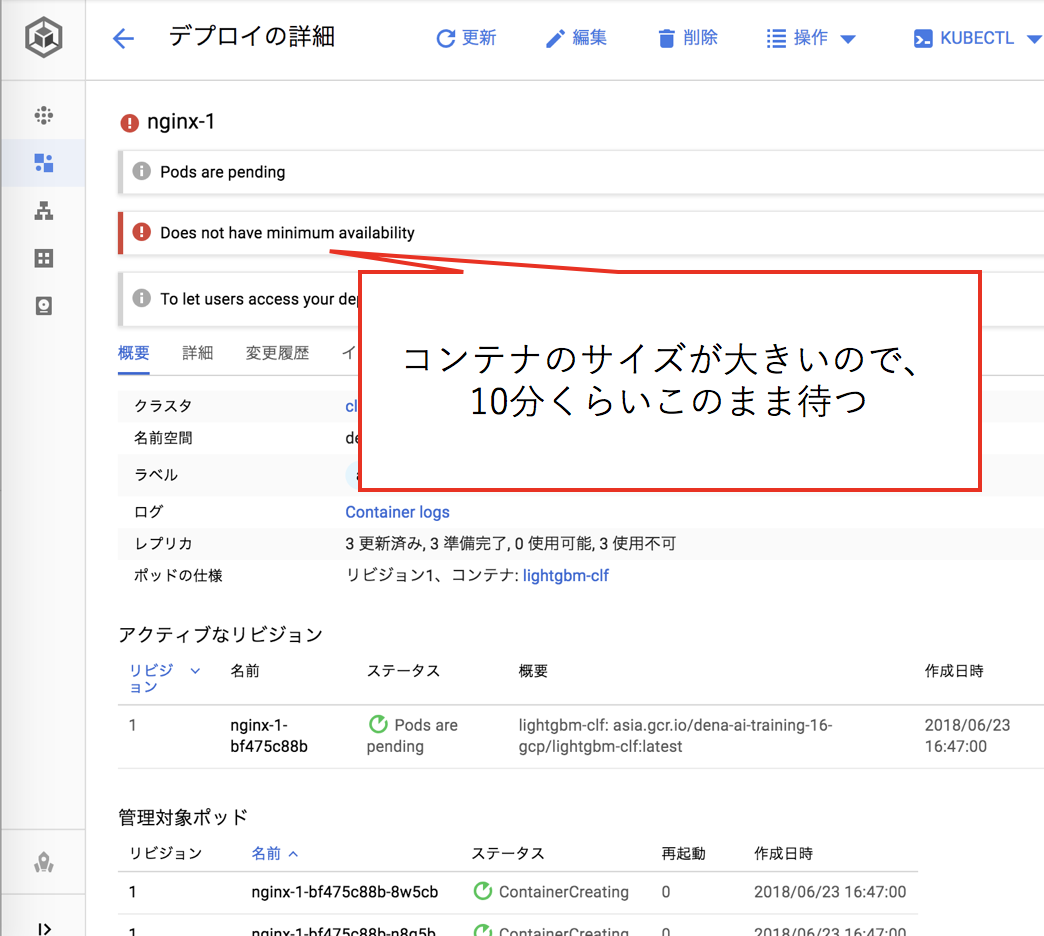
機械学習のモデルと各種依存ライブラリを含んだDockerコンテナはサイズが大きいので、ダウンロードが完了しデプロイが終わるまでしばらく待ちます(10分程度)
外部に公開するために、IPの割当とPortのマッピングを行います。
このとき、サービスタイプはロードバランサーを選択します。

外部IPが得られるので、次の項で、実際にアクセスしてみましょう。

実際にアクセスする
今回はマイクロサービスのデザインパターンにのっとり、jsonでデータをやり取りし、任意のテキスト情報から、そのテキストの映画のレビューとしての星の数を予想します。
stress-testing.pyで1000件の自然言語のコーパスに対して、負荷テストを行っています。
K8Sの特性としてか、SLAを大幅に超過したときに、httpサーバが応答しなくなってしまうので、これは実運用の際にはよく考えたほうが良さそうです。
GCP K8Sで予想する
$ DOCKER=35.189.146.153 python3 stress-testing.py
...
{"score": 4.059278052177565} 特殊な映画 クリストファー・ノーランらしさ全開だと感じました。この緊迫感、絶望感、暗さ。ダークナイトを思い出します。昼のシーンが多く画面や映像が暗い訳ではないのですが、な
んとなく雰囲気が暗い。でもこの暗さがいい味を出してます。分かりやすい娯楽映画ばかり観ている人には理解しにくいかも。
elapsed time 18.113281965255737
ローカルのDOCKERで予想する
$ DOCKER=localhost python3 stress-testing.py
...
{"score": 4.059278052177565} 特殊な映画 クリストファー・ノーランらしさ全開だと感じました。この緊迫感、絶望感、暗さ。ダークナイトを思い出します。昼のシーンが多く画面や映像が暗い訳ではないのですが、な
んとなく雰囲気が暗い。でもこの暗さがいい味を出してます。分かりやすい娯楽映画ばかり観ている人には理解しにくいかも。
elapsed time 5.5899786949157715
何もチューニングしない状態では、ローカルのほうが早いですね(それはそう)
まとめ
Dockerで簡潔にかつ素早くサービスを提供する仕組みを提供する仕組みとしてとてもよさそうです。
小さい案件を一瞬で終わらせるデザインパターンとして、有益なように思います。
kubeflowではなくてk8sをやった理由
フレームワークを利用しないことによる、圧倒的に高い自由度と、ベースとなるDockerコンテナをそれなりにちゃんと整えていたので、kubeflowのワークフローに乗せるメリットは今回の設定では少なかったです。そのため、生のk8sを利用しました。
参照したドキュメント
- Machine Learning Toolkit for Kubernetes
- Mercari ML Ops Night Vol.1 を開催しました
- 機械学習ではじめるDocker
- ML Ops on AWS
実際に使用したコードはこちら