AWS SagemakerでJupyterを使ったり、独自機能を使う
AWS SagemakerでJupyterを使ったり、独自機能を使う
AWS SagemakerでのJupyterの使用例と、工夫すべき点を示します
また、JupyterのPythonに内蔵されているsagemakerで他のコンテナサービスと連携して、SageMakerにユニークな機能であるRandom Cut Forestによる異常検知の使用例を示します。
個人でデータサイエンスコンペとかやるのにJupyterをさくっと立てて使いたいニーズがあるのと、会社でのセキュリティを担保した環境でのJupyterを利用できるユースケースを想定して、GW中に自分の個人契約のAWSで一通りのサーベイを行いました。
目次
- AWS sagemakerとは
- anacondaにモジュールを追加する
- SageMakerのOSとusernameとpermission
- インスタンスのスケール調整
- ディスクの制限をEFSで回避する
- セキュリティグループの扱い
- ディスクの制限をS3で回避する
- Random Cut Forestの異常値検知アルゴリズム
- 論文
- アルゴリズム概要
- タクシーの乗車数の異常検知
- 想定されるユースケース
AWS sagemakerとは
EC2インスタンス等を立てることなく、JupyterNotebookやTensorFlowやSpark等を扱うことができます。
もう一つの機能として、モデルの作成と予想などの重い操作のとき、専用に、ハイパワーのコンテナを確保して行うことでリソースを必要分を動的に確保して学習する機能が備わっています(この延長線上にデプロイメントの作業も置くことができます)。
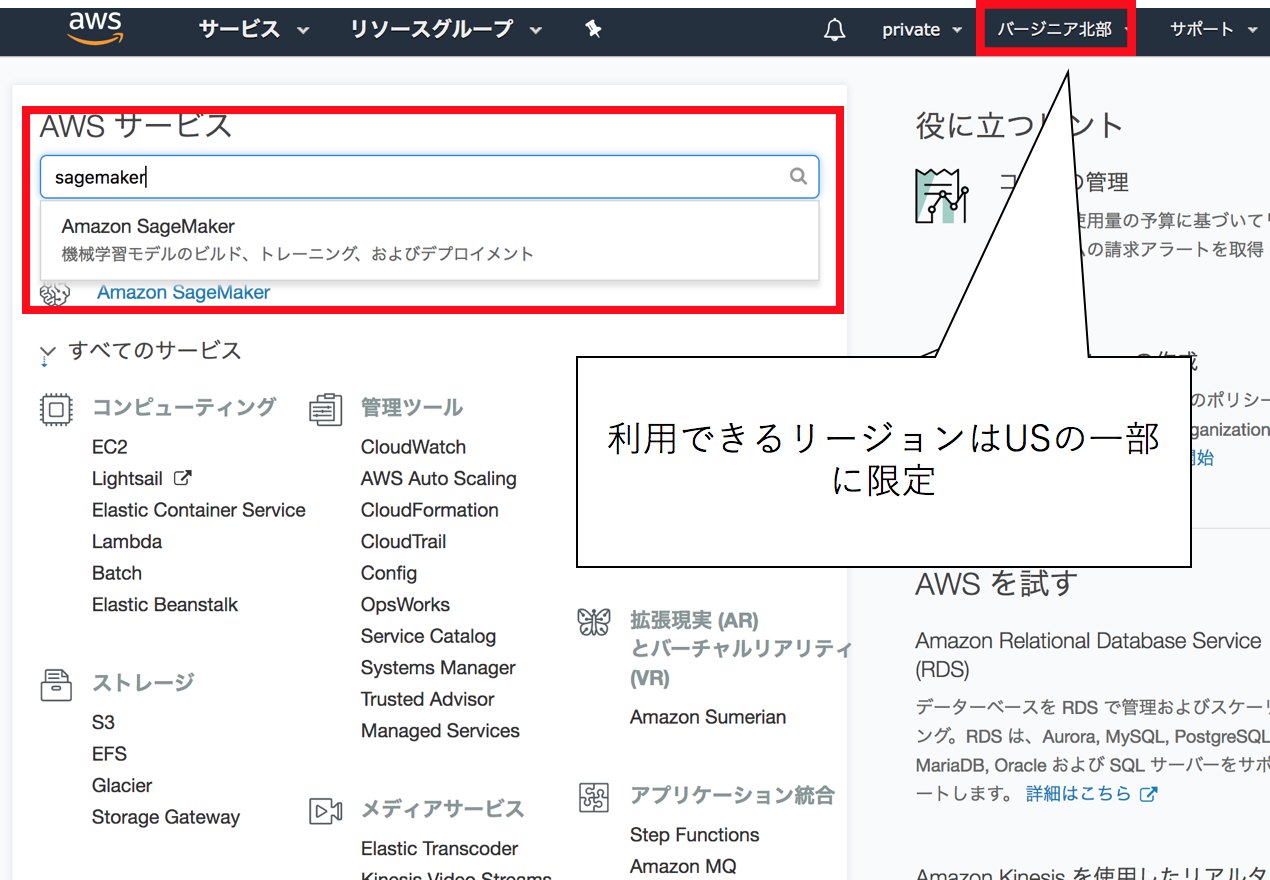
図1. SageMakerのサービスに入る

図2. JupyterNotebookのインスタンス作成&起動
図3. フルサイズのJupyterが立ち上がります

図4. 対応しているカーネルはSpark各種と、mxnet, tensorflow, anaconda
anacondaにモジュールを追加する
Jupyterはユーザ権限で動作しているので、Jupyterの中から直接、モジュールをインストールできます
%%sh conda install -c conda-forge lightgbm
import lightgbm as lgb # OK!
SageMakerのOSとusernameとpermission
JupyterNotebookなので、terminalが使えます。
Linuxの種類とversionは2018/5時点でこのようになっています。
sh-4.2$ less /etc/system-release Amazon Linux AMI release 2017.09
usernameは以下の通りでsudoする権限が与えられています
sh-4.2$ whoami ec2-user
インスタンスのスケール調整

図5. インスタンスを停止して、編集をクリックします

図6. インスタンスのサイズを変更できます
ディスクの制限をEFSで回避する
AWS SageMakerは5GByteの容量制限があるために、大規模なデータを扱う際には外部ディスクとの接続が必要になります。
オフィシャルサイトでもその手法は紹介されていますが、EFSというネットワーク経由のディスクをマウントする際に気をつけるべき点があります。
- EFSとSageMakerのセキュリティグループは同じである
これを気づかずに数時間とかしました。。。
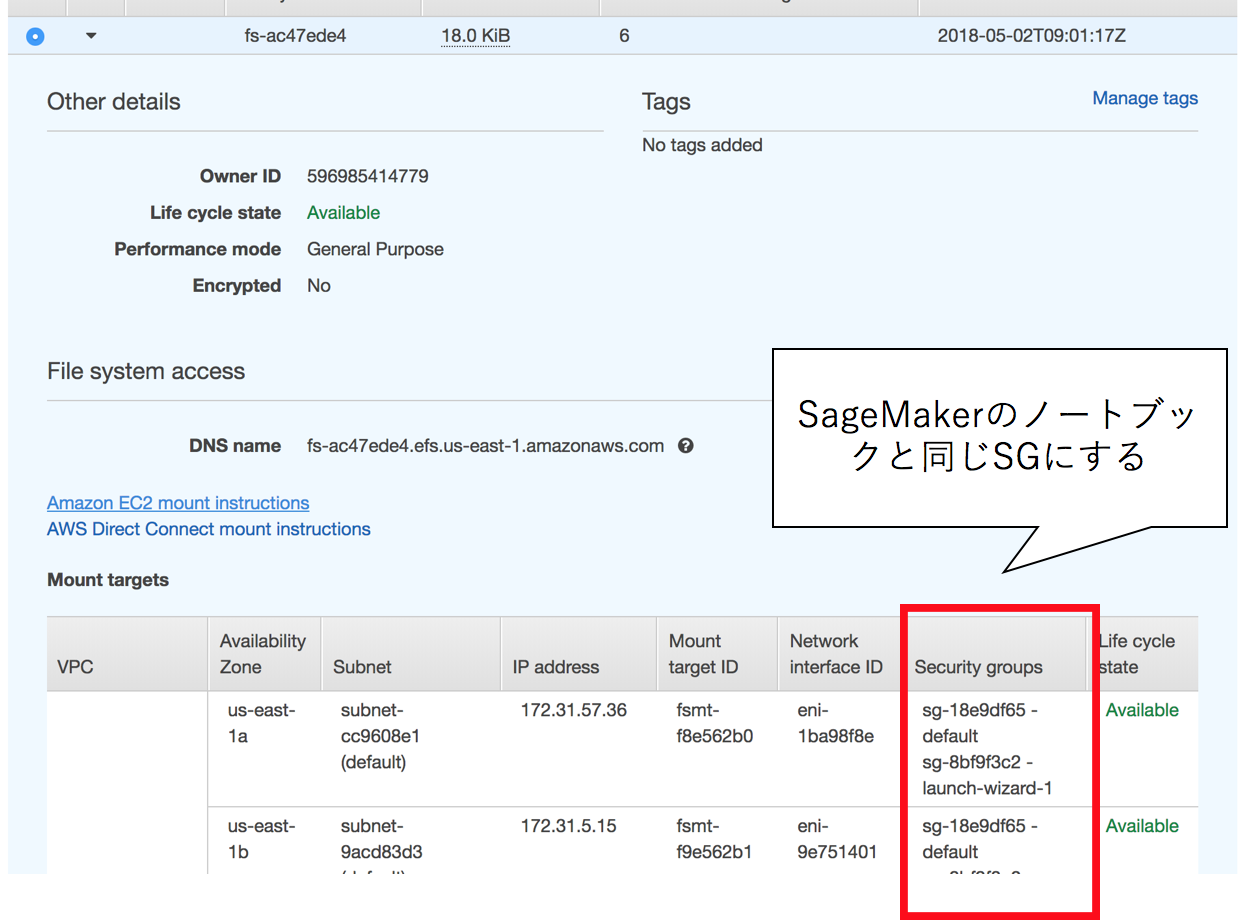
図7. EFSのセキュリティグループをSageMakerのインタンスのものと同じにしておきます
SageMakerも一旦インスタンスを作成してしまうと、セキュリティグループ等を変更できないので、要注意です。
Jupyterでshを有効にするか、terminalに入って、以下のコマンドでEFSをマウントできます。
$ cd SageMaker
$ mkdir efs
$ sudo mount -t nfs4 -o nfsvers=4.1,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2 ${MOUNT_TARGET_IP}:/ efs
$ sudo chown -R uc2-user efs
複数のインスタンスでアクセスでき、後述するS3をマウントするアプローチよりだいぶ速度的にマシだったりして、選択としてありだと思います。
ディスクの制限をS3で回避する
マウントするにはgoofysというgoでS3を透過的にマウントする仕組みが便利です。
Linux用のバイナリがすでにコンパイルされて公開されているので、それを利用します。
goofysのバイナリを設置して、credencialsを設定します
$ cd SageMaker
$ mkdir bin
$ cd bin
$ wget http://bit.ly/goofys-latest
$ chmod +x goofys-latest
$ cat ~/.aws/credencials
[default]
aws_access_key_id = ${AKID1234567890}
aws_secret_access_key = ${MY-SECRET-KEY}
必要なバイナリ、fusermountが含まれていないので、別途インストールします
$ sudo yum install fuse
マウントします
$ /bin/goofys-latest gk-sagemaker-test-01 s3
これでs3で作業するには容量制限を受けませんし、お安いのですが、遅いので、コスパ重視の設定になります
Random Cut Forestの異常値検知アルゴリズム
AWS SageMakerの売りとしてAWSのハイパワー仮想化コンテナを利用することで、JupyterNotebookが動作しているコンテナでなくても、高速に学習・予想することが可能なようです。
Random Cut Forestというあまり名前を聞かない異常検知アルゴリズムです。
ノンパラメトリックの異常値検知アルゴリズムで使い勝手は良さそうです。
論文
論文自体は2016年に発表されたもので比較的新しめです。
AWS whitepaperの中に紛れて公開されており、誰でも参照できます。
アルゴリズム概要
論文(というなのwhite paper)をよんでいった感想なのですが、やろうとしていることとしては、決定木系のアルゴリズムで、異常値を含むと、 なんらかモデルが複雑になるという発想から来ているようです。
つまり、正常な状態より、異常な状態は予想が困難で複雑であるということから、その複雑度を見ていくことで異常度を定義しようという発想に見えました。
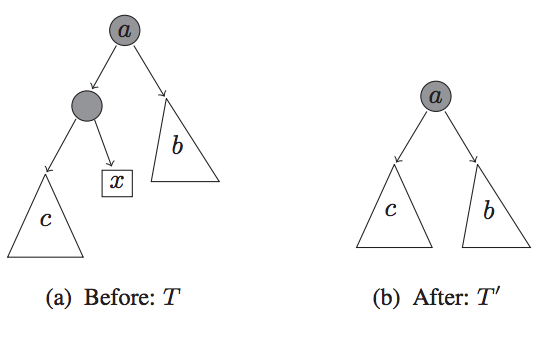
図8. 決定木の複雑度を減らす操作

式1. 簡略化したモデルから複雑なモデルとの誤差をもとに評価を決定
お気持ちとしてはモデルの複雑度(この場合は決定木の深さ)が、しきい値を超えたら、何らかの異常値があるとみなす、という流れです。
各系列で、様々に複雑度を見ていって、これをscoreとして、scoreの平均値と標準偏差の和などをしきい値として、しきい値が偏差を超えたら異常値と定義するなどで使えます。
タクシーの乗車数の異常検知
ニューヨークの日々のタクシーの利用者数をtime seriesで格納されたデータを用いて、異常値検知を行っていますが、2018/05/01に投稿されたはずなのポストですが、動作しませんでした。
追試したところ、以下のようにコードを変更する必要がありました。
変更前
rcf.set_hyperparameters(
num_samples_per_tree=200,
num_trees=50,
feature_size=1)
変更後
rcf.set_hyperparameters(
num_samples_per_tree=200,
num_trees=50,
feature_size=1)
一通り実行した内容のjupyterがあるので、必要に応じて参照してください
感想としては、これは、パラメータ調整次第で、prophetで扱えない高次元の入力となる系列情報も対応かのうそうで、問題によっては使う意義がありそうです。
想定されるユースケース
インスタンスを建てないでJupyterで分析, MLする。
AWSと密に運用されたサービスでモデルの学習とデプロイを行う
SageMakerのモジュールのIF自体が微妙にわかりにくく、学習コストがそれなりに掛かるので、必要でなければ、ScikitLearnとかでローカルで動作させてしまったほうが楽かなと思いました。
dask.distributedで分散処理
dask.distributedで分散処理
dask.distributedの使い方と、具体例集です
dask.distributedの簡単な理解
一種の分散処理フレームワークになっており、便利です。
ドキュメントやgithubはdaskからdask.distributedは分割されており、DataFrameの取扱以外のより汎用的な分散処理を含んでいるようです。
Celeryとかでもやったことをがあるのですが、dask.distributedはRemote Procedureのそれよりまともでより整理された方法で、concurrent.futureのリモート版とも考えられます。

dask.distributedのインストール
pip経由でのdaskのインストール
$ sudo pip3 install dask $ sudo pip3 install distributed
ubuntuでのインストール
注:パッケージが微妙に古くてpip経由の方がいいです
$ sudo apt install python3-distributed
Dask SchedulerとWorkerのセットアップ
Schedulerは分析を実行するマシン、クライアントマシンなど任意のマシンでいいはずです
(今回はschedulerを起動するマシンは192.168.14.13のIPアドレスを持つとしています)
$ dask-scheduler Start scheduler at 192.168.14.13:8786
portのチェック
$ nc -v -w 1 192.168.14.13 -z 8786
Workerは命令を受け実際に計算するマシンなので、別のマシンになります
${SCHEDULER}にはschedulerを起動したマシンのIPが入ります
nprocsオプションで最大のworkerでの並列数(同時に関数が走る数)を指定できます
$ dask-worker ${SCHEDULER}:8786 --nprocs 12
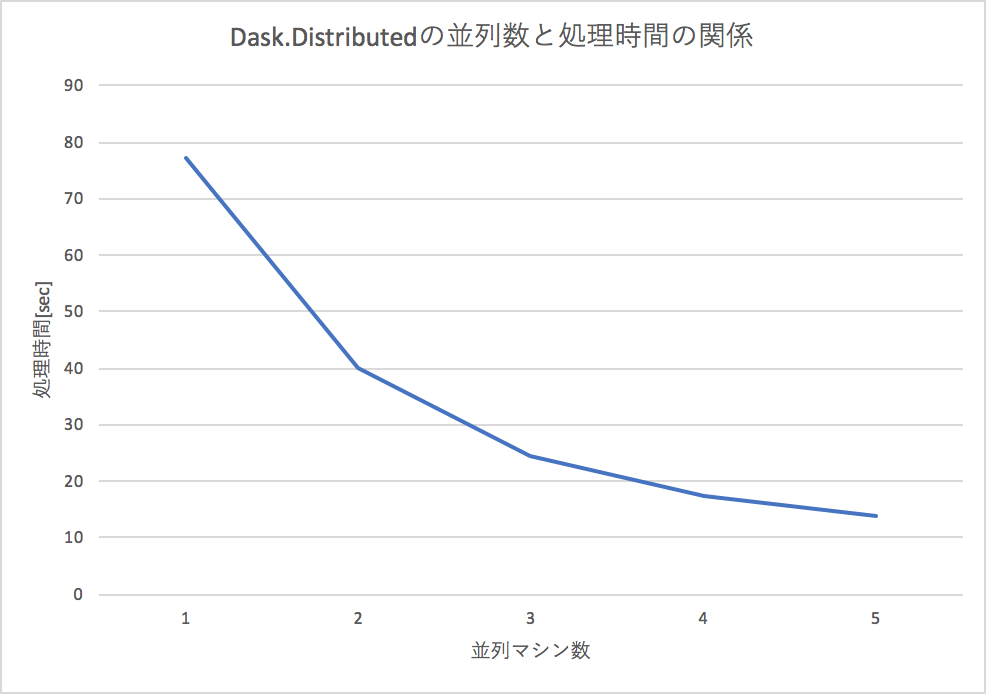
Dask.Distributedの並列マシン数と、速度の関係
下記にある簡単な足し算を並列マシン(worker数の増加)でやろうとすると、処理時間がほぼ反比例の関係で下がるので、効率的に分散処理できていることが確認できます。
分散した命令の結果を受け取る2つの方法
clientにmapされた命令はschedulerが管理して分散処理されますが、内部で、マシン台数かに分割されており、速度的には、一気に結果を見る(gather)のも、個別にみる(result)のもあまり変わりがないようです。
gatherという関数で一気に集められますが戻り値が多いときには、オンメモリにするのが難しいので、挙動が不安です。
L = client.map(inc, range(1000)) ga = client.gather(L)
resultで一個一個取っていく方法は、一件の処理結果のみ返すので、メモリ節約にはなりそうです
L = client.map(inc, args) for l in L: print(l.result())
例に用いたコード
簡単な例:数字を増やすだけ
簡単な命令で、数字を足し合わせて行くだけのプログラムですが、100回引数を変えて行おうとすると、計算時間がかかります。
今回、5台のマシンで一台あたり12並列数で行うので、合計60並列で処理します。
ClientでschedulerのIPアドレスとportを指定して、以下のようなコードを実行するだけで、複数のマシンで並列計算をすることができます。
from distributed import Client client = Client('192.168.14.13:8786') def inc(x): for i in range(10000000): x += i return x L = client.map(inc, range(1000)) ga = client.gather(L) print(ga)
複雑な例:機械学習のモデルのグリッドサーチでも便利
機械学習のパラメータを少しずつ変えながらもっとも、パフォーマンスが良いパラメータを総当りで探すグリッドサーチというものあって、マシンパワーでゴリ押ししてしまうのが都合がいいのです。
複数台のworkerでグリッドサーチさせると、そのマシンの台数分だけ減らせます
dask.mllibを使うとscikit-learnをラップして使うことができますが、任意のライブラリでも動かしたいので、特にdask.mllibは使いません
代表的なUCIのadult incomeデータセットでランダムフォレストでパラメータを2x10x10x15=3000通りという膨大なパラメータサーチであっても、割と早く終わらせることができます。
以下のコードの例では、パラメータの組み合わせを作って、分散処理で評価させています。
関数doはworkerで実行されて、ホームディレクトリ以下のデータセットを読み込んで、引数に与えられたRandomForestのパラメータを適応して学習し、テストデータでの精度を見ています。
def do(param): dataset = pickle.load(open(f'{os.environ["HOME"]}/dataset.pkl', 'rb')) Xs, ys, Xst, yst = dataset criterion, n_estimators, max_features, max_depth = param model = RandomForestClassifier(n_estimators=n_estimators, criterion=criterion, max_features=max_features, max_depth=max_depth) model.fit(Xs, ys) ysp = model.predict(Xst) acc = accuracy_score(yst, ysp) print(acc) return [acc, list(param)] params = [] for cri in ['gini', 'entropy']: for n_esti in range(5,15): for max_features in range(10,20): for max_depth in range(4, 20): params.append( (cri, n_esti, max_features, max_depth) ) L = client.map(do, params) ga = client.gather(L)
adult incomeのデータを学習可能かデータに変換
$ python3 parse-adult.py
出力されたdataset.pklを各workerのホームディレクトに配置
関数の引数に学習用のデータを含めると、遅くなったり、警告がでたりするので、大規模なデータの際はscpで転送する、S3, GCSを利用するなどが良いようです。
workerの台数で分散処理してグリッドサーチ
$ time python3 adult.py ... real 2m24.923s user 0m5.950s sys 0m0.951s
10分以上かかる処理が2分半程度に圧縮できました!
progress barの表示
client.map, client.submitをprogress関数でラップすることで、進捗を確認することができます
L = client.map(do, params) progress(L) # このようにする ga = client.gather(L)

dask.distributedで注意すべき点
dask.distributedで関数の引数に大きすぎるデータ(100MByte)を超えるものを投入すると警告が出るし、転送も早くありません。
そのため、なんらかローカルで対象となるデータを共有している必要があり、scpでファイル転送、HDFSやS3, cloudstrageなどとは相性がよい設計です。
S3とかに格納されchunkされたデータを一気に処理するときなど、便利そうです
金銭的な比較
今現在、私の個人サーバは6core 12threadのRyzen 1600Xが5台あって、30core 60threadで動作します。
2018/03現在、これはおおよそ2万円なので、10万円程度でこの仕組が購入できたことになります。
同等のスペックであるEpyc 7551pは$2100なので、おおよそ20万円で、半額程度で手に入れることができました。
もちろん、分散させないで一大のマシンで処理するメリットとかあると思うのですが、こんな大規模計算は稀だし、必要なときにdask-workerを立ち上げてクラスタに組み込めるのはメリットです。
Dask(+Dask.Distributed)の使い所
Apche Sparkと競合するような位置づけですが、Daks.Distributedのその簡単にデプロイできることと、Apache Sparkを用意するまででもないときとかよいんではないか、みたいに言われているようです。
私は、HadoopやDataFlow(Apache Beam)が結構好きで得意なので、Sparkをあんまり使わないですが、ここまで大げさに分散処理する必要が無いときにDask(+Dask.Distributed)は良さそうですね。
DeepLearningでアップサンプリングする
DeepLearningでアップサンプリングする
オーディオ界隈はオカルトっぽく見えていたので、今までどうしようと思っていたのですが、簡単な感じで結果がでました
世の中、音のアップサンプリングや音質がよくなるような細工に本当に余念がないのですが、ディープラーニングでも簡単に対応することは可能です。
世の常としてA/D変換されたデータは元のデータが欠落するから、音の復元は無理だと言われ[3]てきましたが、機械学習を使えばその制限は突破できます。
High Resolution
ハイレゾは96kHz/24bitという高いサンプリング数と、高い解像度を誇ります。
通常、YouTubeでは44kHz/16bitで音楽が再生されるので、及ばないのですが、22kHz/16bitの音源を44kHz/16bitに引き上げてみます。

図1. 今回やりたいこと
この中間を補填するロジックに深層学習を組み込みます。
今回使用したネットワーク
幾つかやり方にはコツがあって、実は音の16bit値をfloatに変換したのでは、うまく行きません。これは、DNNがあまりにも小さい値には反応しないし、この小さなさが、音の善し悪しを分けたりするからです。
そのため、16bitをバイナリ(2進数)表記に変換して、音のある波形の前後25サンプルを切り出します。
25サンプルから、44kHzで本来存在していただろう、音の波形を補完します。
人の声や楽器など、ある程度のレンジを取って音波をみることで、楽器や声などの音の並ごとに特性が獲得できるとの仮説があるからです。
ネットワークでは、双方向のLSTMのネットワークを用いました。

図2. 全体のデータの流れ
コードで書くと、こんな感じです。(Bi=Bidirection, TD=TimeDistribute)
input_tensor1 = Input(shape=(50, 16)) x = Bi(CuDNNLSTM(300, return_sequences=True))(input_tensor1) x = TD(Dense(500, activation='relu'))(x) x = Bi(CuDNNLSTM(300, return_sequences=True))(x) x = TD(Dense(500, activation='relu'))(x) x = TD(Dense(20, activation='relu'))(x) decoded = Dense(1, activation='linear')(x) print(decoded.shape) model = Model(input_tensor1, decoded) model.compile(RMSprop(lr=0.0001, decay=0.03), loss='mae')
実験
ボーカロイドの曲である「wave」をreworuさんが歌ったものを利用しました
YouTubeからwaveファイルを取り出すことはできるので、ダウンロードしたら、入力用に22kHzにダウンサンプルします。(著作権の関係で音源は添付しませんのでご自身でご用意してください)
$ python3 10-scan.py
オリジナルの曲と、ダウンサンプルした曲のペアのデータ・セットを作成してnumpyに変換します
$ python3 20-make-dataset.py
学習
GTX1080Tiで二時間程度です
(音楽の前8割を学習に使い、残り2割を評価に回します)
$ python3 rnn-super-resolution.py --train
アップサンプリング
$ python3 rnn-super-resolution.py --predict
結果(誤差評価)
ぶっちゃけ、聞いても定性的な評価になってしまうというのが本音なので、テストデータにおけるMean Absolute Error(平均絶対誤差)をみて良くなっていることを確認します。
$ python3 eval.py オリジナルデータ 0.0 22kHzデータ 1260.0746398721526 ディープラーニングでアップサンプリングしたデータ 610.2184827578526
値が少ないほうがいいのですが、たしかに、22kHzのデータそのものより音質は改善していることがわかりました。
結果(聞いてみる)
オリジナル44khz .
https://soundcloud.com/sgemuj01eczp/origin
ダウンサンプル22kHz
https://soundcloud.com/sgemuj01eczp/degradation-1
https://soundcloud.com/sgemuj01eczp/yp-orig-5
よく聞き分けると、ノイズのような音源が、ところどころ機械学習では混じっていることがわかるかと思います(課題)
まとめ
ネットワークの大きさや、出力を工夫することで、44khz -> 88khzも可能だと思うし、単純なフィルタを超えたアップサンプリングが可能だと思います。
オーディオ沼は怖いのでほどほどにしておきたいですが、簡単にできるので、やってみる価値はあるかもしれません。
最後に実は全然別で、audio super resolutionというものをやってらっしゃる方を発見して、これは、音を画像のように捉えてアップサンプリングするようです[2]。
参考文献&オカルト
[1] mp3音源を“アップサンプリング”で高音質化できるか試してみた (データフォーマットを変形しただけでアップサンプリングできていないように見える)
文章をBlockChainで管理する
文章をBlockChainで管理する
今更感がありますが、BlockChainについて、技術的な点について結構曖昧であったので、調べなおしたりしました。
P2Pの多数決の理屈ばかり強調されますが、実際のところどうなっているのか、自分で実際に実装を行いながら、ブロックチェーンを組んでみて確認してみました。
BlockChainとは
- BitCoinに代表される仮想通貨の分散データベースシステム
- ハッシュアルゴリズムにより、事実上の改竄が不可能
- ドキュメントによっては、合意形成や、ブロックチェーンが意図しない方向にチェーンが伸びてしまった場合の取扱まで含んだりする
(今回のスコープはp2pは含まず、オフラインで検証しました)
BlockChainを理解するには何を知っていると便利か
- hash関数
- hash関数を使った応用例各種
- 簡単なP2P
コンピュータにおけるhashの使い方
hashはいろいろな値(文字列やなんでも)を、特定の数値の範囲にうまくエンベッティングする技術で、この仕組を使うと、キーからバリューの引き出しがO(1)の計算量で行えます。

図1. HashMapの構造
hashによる分散化はあらゆるところで行われており、エンジニアにとって馴染みのあるものでは、hashmap, KVS, Hadoopなどがキーをハッシュ化することでうまくやっています。


図3. 国会で説明された様子[1]
BlockChainまで発展する
BlockChainはこのhashによる鎖を連ねることで、鎖が維持できるているかどうかで、データが正しいかどうかの検証が行えます。

図3. 正常系(不正がない場合)

図4. 異常系(なんらかの編集があった場合)(+電子証明が使われます)
単純なこの仕組に加えて、様々にP2Pで動作を確認と保証する仕組みをいれてBlockChainというらしいです(広義すぎるので分散台帳技術はちょっと和訳として不適切だと思う)
BitCoinにある採掘という作業
BitCoinには採掘という作業があって、GPUをゴリゴリ回してお金を得るみたいなことをやっている人たちがいます。これは、ハッシュ値の先頭が0000000〜とかになるように、データの中にnonceというフィールドを追加して調整しています。 最初に特定条件に一致するハッシュ値を計算できた人がインセンティブをもらい、次に繋がる鎖を生成します。これはマイニングしている人が、マイニングするモチベーションであり、ビットコインという通貨的特性と相性がいい理由でもあります。
P2Pでは同時に生成してしまう可能性がありますが、同時に生成してしまったら、後続に続く鎖の数が大きい方が優先されます。
国会で今話題になっている公文書偽造などの問題には転用可能でしょうか。
公文書管理におけるブロックチェーンの利用
この資料によると、費用対効果の視点でコストが嵩みすぎるという課題が挙げられていますが、それは、nonceによる採掘難易度に依存するし、衝突困難性は採掘と関係がないので、私はできると考えています。
また、直接、データをブロックチェーンに入れるのではなく、公文書のハッシュ値やフィンガープリントに該当するものをいれればいいはずだと思うのですが。
夏目漱石の小説をブロックチェーンに組み込む
このようなコードを作成しました。 前のhashの情報を記憶しつつ、データを持ち、nonceの条件を満たすものを探し、一致したら、ブロックをjsonで吐き出すものです。
def _gen_block(arg): source_host, data, prev_hash = arg now = time.time() loc = datetime.fromtimestamp(now) timestamp = loc.timestamp() while True: nonce = random.randint(0, 100000000000000) block = { \ 'timestamp':timestamp, \ 'source_host':source_host, \ 'data':data, \ 'prev_hash': prev_hash, \ 'nonce':nonce, } next_hash = hashlib.sha256(bytes(json.dumps(block),'utf8')).hexdigest() # 先頭のN字が"0"ならば、採用 size = 1 if next_hash[:size] == '0'*size: break open(f'cache/{next_hash}', 'w').write( json.dumps(block, indent=2, ensure_ascii=False) ) return block, next_hash start_block, next_hash = _gen_block(('http://localhost:1200', 'Ground Zero', hashlib.sha256(bytes('0', 'utf8')).hexdigest())) for line in open('stash/kokoro.txt'): line = line.strip() block, next_hash = _gen_block(('http://localhost:1200', line, next_hash) )
nonce値の難易度による夏目漱石の「坊っちゃん」を全部ブロックチェーン化するまでの計算時間
先頭が0一個、0二個、0三個、0四個と評価しました。
わかりきっていたことですが、だいぶ計算時間が違います。
CPU
CPU MHz: 1550.000 CPU max MHz: 3800.0000 CPU min MHz: 1550.0000AMD BogoMIPS: 7585.48en 5 1500X Quad-Core Processor
$ uname -a Linux PrintzEugen 4.13.0-32-generic #35-Ubuntu SMP Thu Jan 25 09:13:46 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux

図5. 計算の難易度ごとの必要計算時間
インセンティブが働かない公文書管理などの環境では、nonce値はないか、小さい値でいいのではないかと考えいています。
過去への遡及
BlockChainはその名の通り、鎖状になっているので、偽造されたものでない限り、最初の発行者のデータにたどり着けるような仕組みになっています。
坊っちゃんの最後のセリフから、最初データまで辿ってみましょう。
最後のセリフ
hash => 00ce7c3a81315250d7abc2d99f177b2ffb442334644044ea89f1d6e435845d86 っtimestamp': 1521708677.710969, 'source_host': 'http://localhost:1200', 'data': '私は私の過去を善悪ともに他ひとの参考に供するつもりです。しかし妻だけはた唯た一人の例外だと承知して下さい。私は妻には何にも知らせたくないのです。妻が己おのれの過去に対してもつ記憶を、なるべく純白に保存しておいてやりたいのが私の。一ゆいいつの希望なのですから、私が死んだ後あとでも、妻が生きている以上は、あなた限りに打ち明けられた私の秘密として、すべてを腹の中にしまっておいて下さい 」', 'prev_hash': '072c69c315bc6c2839122f1b5566df41dfb64f9c489b44441056bab8b0ed9104', 'nonce': 18180102876915}
最初まで遡ります
$ python3 phyllis.py 私は私の過去を善悪ともに他ひとの参考に供するつもりです。しかし妻だけはたった一人の例外だと承知して下さい。私は妻には何にも知らせたくないのです。妻が己おのれの過去に対してもつ記憶を、なるべく純白に保存しておいてやりたいのが私の唯一ゆいいつの希望なのですから、私が死んだ後あとでも、妻が生きている以上は、あなた限りに打ち明けられた私の秘密として、すべてを腹の中にしまっておいて下さい。」 しかし私は今その要求を果たしました。もう何にもする事はありません。この手紙があなたの手に落ちる頃ころには、私はもうこの世にはいないでしょう。とくに死んでいるでしょう。妻は十日ばかり前から市ヶ谷いちがやの叔母おばの所へ行きました。叔母が病気で手が足りないというから私が勧めてやったのです。私は妻の留守の間あいだに、この長いものの大部分を書きました。時々妻が帰って来ると、私はすぐそれを隠しました。 私が死のうと決心してから、もう十日以上になりますが、その大部分はあなたにこの長い自叙伝の一節を書き残すために使用されたものと思って下さい。 ... (中間の表現) ... 私わたくしはその人を常に先生と呼んでいた。だからここでもただ先生と書くだけで本名は打ち明けない。これは世間を憚はばかる遠慮というよりも、その方が私にとって自然だからである。私はその人の記憶を呼び起すごとに、すぐ「先生」といいたくなる。筆を執とっても心持は同じ事である。よそよそしい頭文字かしらもじなどはとても夏目漱石と私ない。 こころ Ground Zero
Ground Zeroとは、今回、作成したblockchainの最初の値になるシードのデータです。
様々なブロックチェーンの応用例
このように、情報が正しければ遡及を行え、すべてのレコードを引き出すことも可能になります。
改竄されていたりすると、不自然なところで遡ることができなくなったり、改竄されたデータを元にブロックチェーンをつなげてしまったと解釈できそうです。
この特徴を利用して、食品安全の仕組みに組み込むことで、肉などの偽装や、安全管理などが行えることが期待できます[3]。
またブロックチェーンの偽装が難しい問題で、戸籍などをブロックチェーン化してしまうのもあるようです[4]。
作成したコード
offline.py 単一マシンで、文章のブロックチェーンを構築します。 ハードコードされたsizeで計算の難易度を指定できます
$ python3 offline.py
phyllis.py ブロックチェーンのハッシュ値から過去のブロックを辿って、ルートまで逆引きするプログラムです
$ python3 phyllis.py