RocksDBをさまざまな言語(C++, Rust, Kotlin, Python)で利用する
RocksDBをさまざまな言語(C++, Rust, Kotlin, Python)で利用する
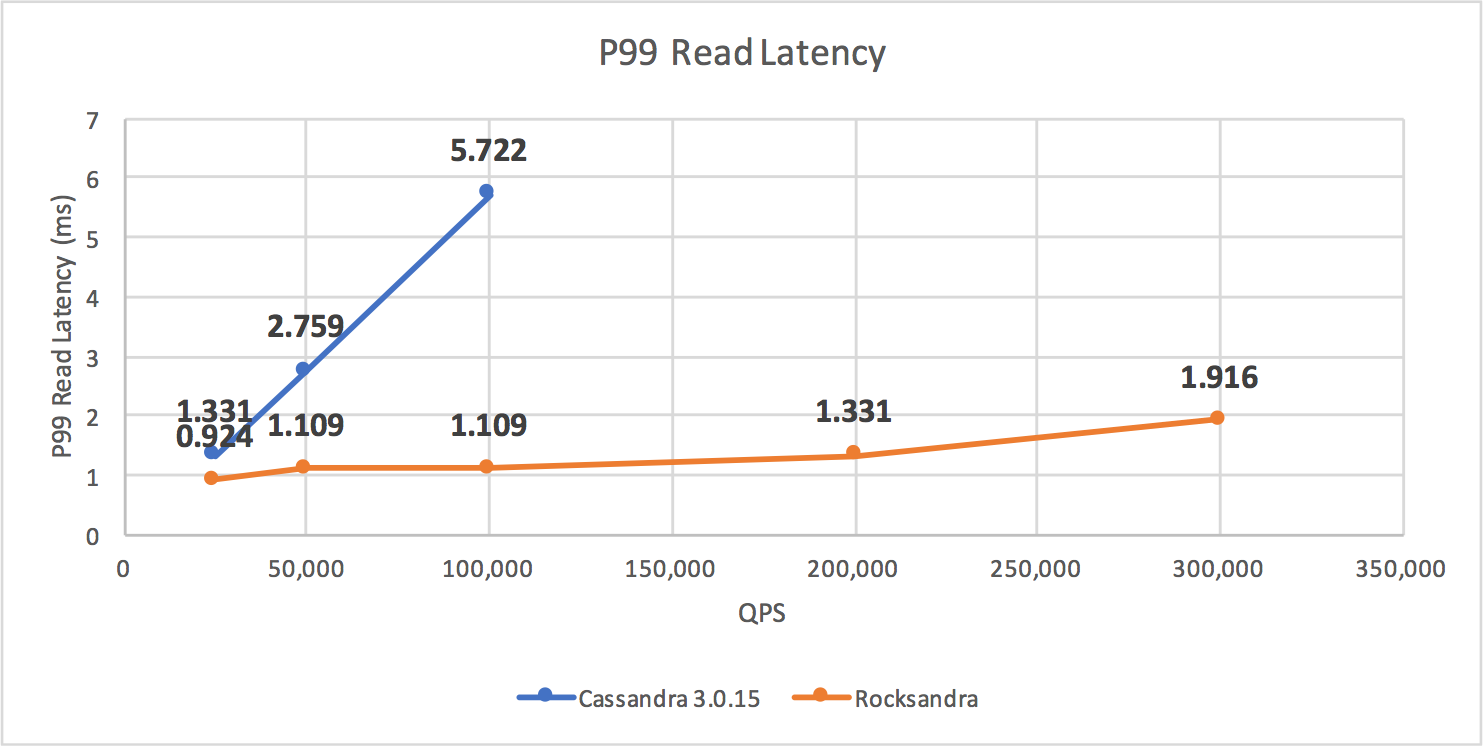
InstagramのCassandraのバックエンドをJVMベースのものから、RocksDBに切り替えたというニュースが少し話題になりました。
CassandraのJVMは定期的にガーベジコレクタが走って、よろしくないようです。
P99というテストケースではデフォルトのJVMからRocksDBに張り替えたところ10倍近くのパフォーマンスが得られたとのことです。
データ分析でもメモリ収まりきらないけど、Sparkのような分散システムを本格に用意する必要がない場合、NVMe上にLevelDB, RocksDBなどのKVSを用意して加工することがあります。
ローカルで動作させるには最強の速度だし、文句のつけようもない感じです。
LSMというデータ構造で動いており、比較対象としてよく現れるb-treeより書き込み時のパフォーマンスは良いようです[1]
LSMのデータ構造では挿入にO(1)の計算量が必要で、検索と削除にO(N)の計算量が必要です。
前提とやりたいこと
- RocksDBはSSDやnvmeで爆速を引き出すパーマネントKVSです
- LevelDB, RocksDBはPythonで分析するときの必勝パターンに自分のスキルの中に入っているので、ぜひともRocksDBも開拓したい
- RocksDBはC++のインターフェースが美しい形で提供さており、他言語とのBindingが簡単そう
もくじ
- 1. RocksDBのインストール(Linux)
- 2. Pure C++でのRocksDBの利用
- 3. C++ Bindingの方針
- 4. Rustでの利用
- 5. Kotlinでの利用
- 6. Python(BoostPython)での利用
これらのコードはこちらにあります。
1. RocksDBのインストール
Ubuntuですと標準レポジトリにないので、ビルドしてインストールする必要があります
(GCC >= 7.2.0, cmakeなどの基本的なbuild-toolsが必要なので、ご自身のOSに合わせて用意してください)
$ git clone git@github.com:facebook/rocksdb.git $ cd rocksdb $ mkdir build $ cd build $ cmake .. $ make -j12 $ sudo make install
2. Pure C++
注意 最新のClangでは構文エラーでコンパイラが通らないので、gcc(g++ >= 7.2.0)を利用必要があります
C++でRocksDBは記述されているので、C++でのインターフェースが最も優れています。
DBのopen, get, putはこのようなIFで提供されています
DB* db; Options options; // Optimize RocksDB. This is the easiest way to get RocksDB to perform well options.IncreaseParallelism(); // create the DB if it's not already present options.create_if_missing = true; // open DB string kDBPath = "test.rdb"; Status s = DB::Open(options, kDBPath, &db); assert(s.ok()); // Put key-value s = db->Put(WriteOptions(), "key1", "value"); assert(s.ok()); // get value string value; s = db->Get(ReadOptions(), "key1", &value); assert(s.ok()); assert(value == "value");
Pinableという考え方があり、Pinableを用いると、データのコピーが発生しない(memcpyは動作しない)ので、高速性が要求されるときなど良さそうです
PinnableSlice pinnable; s = db->Get(ReadOptions(), db->DefaultColumnFamily(), "key1", &pinnable); // メモリコピーコストが発生しない
3. C++bindings
C/C++でラッパーを書くことで任意のCのshared objectが利用できる言語とバインディングを行うことができます。
extern "C"で囲んだ範囲が外部のプログラムで見える関数になります。
extern "C" { void helloDB(const char* dbname); int putDB(const char* dbname, const char* key, const char* value); int getDB(const char* dbname, const char* key, char* value); int delDB(const char* dbname, const char* key); int keysDB(const char* dbname, char* keys); }
サンプルのshared objectを作成するコードを用意したので、参考にしていただけると幸いです。
$ cd cpp-shared
$ make
$ ls librocks.so
$ ldd librocks.so
linux-vdso.so.1 => (0x00007fff04ccd000)
librocksdb.so.5 => /usr/lib/x86_64-linux-gnu/librocksdb.so.5 (0x00007fdaf33ab000)
libstdc++.so.6 => /usr/lib/x86_64-linux-gnu/libstdc++.so.6 (0x00007fdaf3025000)
libgcc_s.so.1 => /lib/x86_64-linux-gnu/libgcc_s.so.1 (0x00007fdaf2e0e000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fdaf2a2e000)
libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0 (0x00007fdaf280f000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007fdaf24b9000)
/lib64/ld-linux-x86-64.so.2 (0x00007fdaf3e77000)
4. Rust
RustではC++のバインディングを利用してRocksDBにデータを格納したり取り出したりする方法を示します。
サンプルコードを動作させるには、以下のようにterminalを操作します。
$ cd rust $ export LD_LIBRARY_PATH=../cpp-shared/:$LD_LIBRARY_PATH $ make $ ./sample
Rustではstructで定義したものをimplで拡張していくのですが、例えば、putに関してはこのように設計しました。
C/C++などで文字の終了が示される\0が入らないため、このようなformatで文字を加工してC++に渡しています
pub struct Rocks { pub dbName:String, pub cursol:i32, } impl Rocks { pub fn new(dbName:&str) -> Rocks { let outName = format!("{}\0", dbName); unsafe { helloDB( outName.as_ptr() as *const c_char) }; Rocks{ dbName:outName.to_string(), cursol:0 } } } impl Rocks { pub fn put(&self, key:&str, value:&str) -> i32 { let dbName = format!("{}\0", &*(self.dbName)); let key = format!("{}\0", key); let value = format!("{}\0", value); let sub = unsafe { putDB( (&*dbName).as_ptr() as *const c_char, key.as_ptr() as *const c_char, value.as_ptr() as *const c_char) }; sub } }
5. Kotlin
Kotlin, JavaではGradleに追加することで簡単に利用可能になります。
compile group: 'org.rocksdb', name: 'rocksdbjni', version: '5.10.3'
Interfaceも整理されており、以下のように簡単に、put, get, iterate, deleteが行えます
import org.rocksdb.RocksDB import org.rocksdb.Options fun main(args : Array<String>) { RocksDB.loadLibrary() // DBをなければ作成して開く val options = Options().setCreateIfMissing(true) val db = RocksDB.open(options, "/tmp/kotlin.rdb") // データのput val key1 = "key1".toByteArray() val value1 = "value1".toByteArray() db.put(key1, value1) val key2 = "key2".toByteArray() val value2 = "value2".toByteArray() db.put(keygetvalue2) val bvalue = db.get(key1) println(String(bvalue)) // seek to end val iter = db.newIterator() iter.seekToFirst() while( iter.isValid() ) { println("${String(iter.key())} ${String(iter.value())}") iter.next() } // データの削除 db.delete(key1) db.delete(key2) db.close() }
実行
$ cd kotlin $ ./gradlew run -Dexec.args="" Starting a Gradle Daemon, 1 busy Daemon could not be reused, use --status for details :compileKotlin UP-TO-DATE :compileJava UP-TO-DATE :copyMainKotlinClasses UP-TO-DATE :processResources NO-SOURCE :classes UP-TO-DATE :runApp value1 key1 value1 key2 value2 BUILD SUCCESSFUL
6. Python
PythonはBoostPythonを用いると簡単にRocksDB <-> Pythonをつなぐことができます。
Python3とも問題なくBindingすることができて便利です。
ネット上のBoostPythonのドキュメントにはDeprecatedになった大量のSyntaxが入り混じっており、大変混沌としていたので、一つ確実に動く基準を設けて書くのが良さそうでした
CPPファイルの定義
CPPでRocksDBを扱うクラスを定義し、諸々実装を行います
#include <boost/python.hpp> #include <string> #include <cstdio> #include <string> #include <iostream> #include "rocksdb/db.h" #include "rocksdb/slice.h" #include "rocksdb/options.h" using namespace rocksdb; namespace py = boost::python; class RDB{ private: DB* db; public: std::string dbName; RDB(std::string dbName): dbName(dbName){ Options options; options.IncreaseParallelism(); options.create_if_missing = true; Status s = DB::Open(options, dbName, &(this->db)); }; RDB(py::list ch); void put(std::string key, std::string value); std::string get(std::string key); void dlt(std::string key); py::list keys(); }; void RDB::put(std::string key, std::string value) { this->db->Put(WriteOptions(), key, value); } ....
pythonの実装
Pythonで用いるのは簡単で、shared object名と同名のやつを読み出して、インスタンスを作成して、関数を叩くだけです(めっちゃ簡単)
from rdb import RDB # create drow instance db = RDB('/tmp/boost.rdb') # access the word and print it print( db.dbName ) db.put('key1', 'val1') val = db.get('key1') print(val) db.put('key2', 'val2') print(db.keys()) val = db.delete('key1')
NVMeとHDDとのパフォーマンスの違い
もっと決定的に処理速度の差が出ると思ったのですが、そんなに変わらないという感じでした。

まとめ
ユースケースとして、転置インデックスを巨大なデータ構造そのままで、力でゴリゴリ押ししようとしてもメモリ上に乗らなかったりするとき、KVSとしてデータをファイルに書き出すことで効率的に行えたりします。(例えばWikipediaの記事全量からtf-idfを計算するときなど)
Valueは任意のシリアライザーでシリアライズしておく必要があり、Pythonだとpickle, KotlinだとKotlinx.serialize, Rustだとserdeなどが便利です。
今まではLevelDB(RocksDBのFork元)を用いていたのですが、PythonとC++しか実用的な装系がなく、もっといろんな言語とBindingしようとすると、RocksDBのほうが便利だと思いました。