KerasのRNNでFizzBuzzを行う(+ Epochスケジューラの提案)
KerasのRNNでFizzBuzzを行う(+ Epochスケジューラの提案)
ディープラーニングをやるようになって半年程度経ちました
ある程度ならば、文章や画像判別モデルならば、過去の自分の資産をうまく活用することと、外部からState of the Artな手法を導入することで、様々なネットワークを組むことが可能になってまいりました
しかし、基礎の基礎であるはずの、Fizz Buzzをやるのを忘れていたのです
やるしかありません
先行研究
全結合のモデルでの、Fizz Buzzの評価のようです
提案
RNNでも、FizzBuzzは可能なのではないでしょうか
全結合層のモデルのみで、1000 ~ 5000程度のデータで学習させることが多いですが、20万件のデータセットで学習させることで、より大きな数字にも対応させることを目標とします
カリキュラム学習という学習法があり、簡単な問題設定から初めて、徐々に難しくしていくことで、早く安定的に学習できるそうです[1]
この時、人間がカリキュラムを意図して簡単な問題を用意して学習させるのではなく、学習のデータを最初のうちは限定したデータセットにて学習させ、限定したデータを覚えてきたらデータを拡大し、様々なケースを学習させて、汎化性能を獲得していくという学習方法をとります
具体的には、データセットとepochにスケジューラを組み込むことで実現します
モデル
‘1:Fizz, 2:Buzz, 3:Fizz Buzz, 4:そのまま(Path)'と4値の判別問題を全結合層2層でといている問題設定が多いが、 '1:Fizz, 2:Buzz, 3:Path'の3値のそれぞれの状態を求める問題設定とする

図1. 使用したモデル
コードはKerasを利用した モデルとスケジューラは、非常に小さく、わかりやすいです モデル
inputs = Input(shape=(10, 11)) encoded1 = Bi( GRU(256, activation='relu') )(inputs) encoded1 = Dense(512, activation='relu')( encoded1 ) encoded1_1x = Reshape((1,512,))(encoded1) decoded = Dense(3, activation='sigmoid')( Flatten()(encoded1_1x) ) fizzbuzz = Model(inputs, decoded) fizzbuzz.compile(optimizer=Adam(), loss='binary_crossentropy')
スケジューラ(初期のデータセットは、epochを多く学習し、後半になるにつれ一回のみにスケジューリングしている)
class CURRICULUM: EPOCH = [50, 30, 20, 10, 5, 1] @staticmethod def GET(): if len(CURRICULUM.EPOCH) > 0: return CURRICULUM.EPOCH.pop(0) else: return 1 ... fizzbuzz.fit(Xs, Ys, epochs=CURRICULUM.GET(), callbacks=[batch_callback]) ...
コードや日本語では伝えるのに私の貧困なコミュ力では難しかったので、画像を添付しますと、このような差があります

図 2. スケジューリングなし

図 3. スケジューリングあり
このように、学習初期に置いて、学習するデータを非対称にして、最初のデータは多めに繰り返し学習させます
実験
200,000件のFizz Buzzのデータセットを、スクリプトで作成し、5000件ずつ、データセットを分割し40個のデータセットを学習させる
この時、スケジューリングモデルAは、任意のデータセットをランダムで選択し、以下のepoch回、学習する
{ 1回目:50epoch, 2回目:30epoch, 3回目:20epoch, 4回目:10epoch, 5回目:5epoch }
このスケジューリングが完了した後は、残りのデータセットを1epochで学習する
スケジューリングモデルBは特にスケジューリングは行わず、全てのデータセットを平等に学習していく。なお、この方法は、全てのデータセットをメモリ上に乗せて順番に学習していく方法と変わらない
評価
スケジューリングモデルA(青)とモデルB(赤)で大きな差がでた
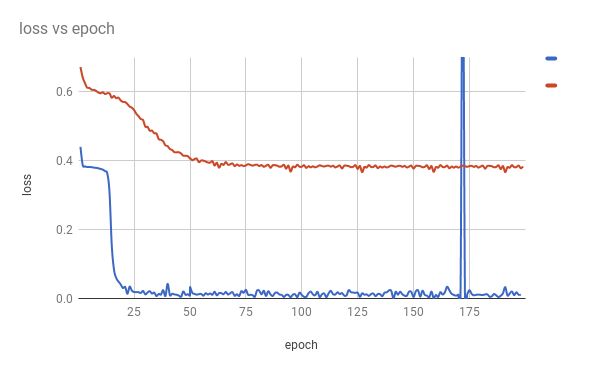
図4. trainデータのepochごとのlossの変化
ニューラルネットワークの初期値の依存性を考慮しても、この差は大きく、スケジューリングを行うことが、まともに収束するしないなどの差を担っているように思われる
モデルAはテストデータにおける精度100%であった
モデルBは68%であった
なお、出力はこのようになっている 左から、入力値、人手による結果、予想値、正解だったかどうか、である(PATHとは、そのまま出力するという意味にしました) ほぼ100%あっていることが確認できた
64170 original result = Fizz Buzz , predict result = Fizz Buzz , result = True
9791 original result = Path , predict result = Path , result = True
54665 original result = Buzz , predict result = Buzz , result = True
118722 original result = Fizz , predict result = Fizz , result = True
97502 original result = Path , predict result = Path , result = True
186766 original result = Path , predict result = Path , result = True
153331 original result = Path , predict result = Path , result = True
7401 original result = Fizz , predict result = Fizz , result = True
117939 original result = Fizz , predict result = Fizz , result = True
22732 original result = Path , predict result = Path , result = True
73516 original result = Path , predict result = Path , result = True
144774 original result = Fizz , predict result = Fizz , result = True
32783 original result = Path , predict result = Path , result = True
67097 original result = Path , predict result = Path , result = True
116715 original result = Fizz Buzz , predict result = Fizz Buzz , result = True
21195 original result = Fizz Buzz , predict result = Fizz Buzz , result = True
コード
https://github.com/GINK03/keras-rnn-fizzbuzz-on-dev
テストデータを作成する
$ python3 data_utils.py --step1
学習する(全体の8割を学習します)
$ python3 fizzbuzz.py --train
予想する(テストデータから予想します)
$ python3 fizzbuzz.py --predict
感想
データによってはまともに収束してくれないものあり、RNNではその傾向が特に顕著です 精確にロス率の違いなどを測ったことがなかったのですが、Epochをいじることによって、安定して学習させることができることがあるということでした
参考文献
教師なし画像のベクトル化と、ベクトルからタグを予想したり類似度を計算したりする
教師なし画像のベクトル化と、ベクトルからタグを予想したり類似度を計算したりする
はじめに
ISAI2017でPCAnetと呼ばれる、教師なし画像の特徴量の抽出方法が紹介されていました
味深い実装になっており、CNNをバックプロパゲーションで結合の太さを学習していくのではなく、予めフィルタを組み込んでおき、使うことで、高い精度を達成しているようです[1]
これを見ていて、AutoEncoderでも同等のことができるのではないかと思いました
AutoEncoderでは、ディープラーニング学習する必要がありますが、やはり、教師データは必要ないです。画像だけあれば良いです。
AutoEncoder

図1. Auto Encoderの図
GANに似ています。GANはこの、図のDecoderを入力との直接の誤差の最小化ではなく、判別機を騙すことで達成しますが、今回はもとの情報が近い方が良いと思ったので、AutoEncodeを利用しました
画像の特徴量をVAEで取り出す方法もあり、僅かにヒントを与えることと出力を工夫することで、より高精度ので分布が取り出せる方法も各種提案されています[2]
余談ですが、単純な、画像生成という視点では、GANに比べて彩度や繊細さがダメっぽくて、画像生成としては色々工夫が必要だなと思いました。
Encoderから特徴量を取り出す
Encoderから任意の次元に圧縮した特徴量を取り出すことができる

図2. Encoderによる特徴量の取り出し
このベクトルは200次元(配列の長さだと、v.size == 200程度)であり、これからディープラーニングは元の画像に近い画像を復旧できたということは、何らか画像を説明する、重要な特徴量がつまっていると考えられます。
このベクトルをVとすると、なんらかのディープラーニング以前のSVMなどのアルゴリズムで機械学習ができそうではあります
また、XGBoostの登場と、DeepLearningの流行りが同時期であったので、これらが得意とする分野が重ならず、併用する文化があまりなかったので、DeepLearningとXGBoostのコンビネーションをやってみようと思いました。
ディープラーニングの現実的な制約とその解決
画像から、属性を予想するプログラムは過去、何回か書かせていただきました。
最初からわかる問題としては、DeepLearning単体ではタグ情報が固定長までしか対応する事ができず、ネットワークを巨大にしても4000次元の出力で、オンライン学習が難しい(新たにタグが発生したときに学習が難しい)などのデメリットがあります
これらを解決する手段としてAutoEncoder, Variable AutoEncoderなどが使える次第です
画像そのもの情報がベクトル化されるので、これらの情報からXGBoostなどに繋げば、新しいタグが発生した祭などに、容易に学習ができます
AutoEncoderのモデル
学習用のコードはgithubにあります
Kerasで書きました。わかりやすいことは一つの正義ではあります。もちろん微細な制御ができるChainerなども正義です
用途と目的によって使い分ければいいかなって思います
input_img = Input(shape=(28*BY, 28*BY, 3)) # adapt this if using `channels_first` image data format x = Conv2D(64, (3, 3), activation='relu', padding='same')(input_img) x = Conv2D(64, (3, 3), activation='relu', padding='same')(x) x = MaxPooling2D((2, 2), padding='same')(x) x = Conv2D(128, (3, 3), activation='relu', padding='same')(x) x = Conv2D(128, (3, 3), activation='relu', padding='same')(x) x = MaxPooling2D((2, 2), padding='same')(x) x = Conv2D(256, (3, 3), activation='relu' , padding='same')(x) x = Conv2D(256, (3, 3), activation='relu' , padding='same')(x) x = BN()(x) x = MaxPooling2D((2, 2), padding='same')(x) x = Conv2D(512, (3, 3), activation='relu' , padding='same')(x) x = Conv2D(512, (3, 3), activation='relu' , padding='same')(x) x = Conv2D(512, (3, 3), activation='relu' , padding='same')(x) x = BN()(x) x = MaxPooling2D((2, 2), padding='same')(x) x = Flatten()(x) z_mean = Dense(196)(x) encoder = Model(input_img, z_mean) """ dec network """ dec_0 = Reshape((7,7,4)) dec_1 = Conv2D(32, (3, 3), padding='same') dec_2 = LeakyReLU(0.2, name="leaky_d1") dec_3 = UpSampling2D((2, 2)) dec_4 = Conv2D(64, (3, 3), padding='same') dec_5 = LeakyReLU(0.2) dec_6 = UpSampling2D((2, 2)) dec_7 = Conv2D(128, (3, 3), padding='same') dec_8 = LeakyReLU(0.2) dec_9 = UpSampling2D((2, 2)) dec_10 = Conv2D(128, (2, 2), padding='same') dec_11 = BN() dec_12 = LeakyReLU(0.2, name="leaky_d5") dec_13 = UpSampling2D((2, 2)) dec_14 = Conv2D(3, (2, 2), padding='same') dec_15 = LeakyReLU(0.2, name="leaky_d6")
実験に用いるデータセット
Pixiv社のデータを利用させていただきました
400万件を取得し、そのうち、200万件をAutoEncoderの学習に用いました。
残り200万件をAutoEncoderのEncoderに通すことで、タイトルとベクトルとその画像のタグ状を取得します
データ構造的には以下のようになります
title1 -> ([v1, v2, ...], [Tag1, Tag2, ...]), title2 -> ([v1, v2, ...], [Tag1, Tag2, ...]), ...
XGBoostの設定
何のタグが付くかの確率値を出したいという思惑があるので、binary, logisticを使います その他の詳細な設定は、以下の通りです
param = {'max_depth':1000, 'eta':0.025, 'silent':1, 'objective':'binary:logistic' }
num_round = 300
これを、すべてのタグに対して予想します タグの種類は30000を超えており、つまり、タグ一つに対して一つモデルを作るので、30000個ものモデルができます このようにいくらでもスケールできることが強みになますね
実験
AutoEncoderのチューニングにはGTX1080にギリギリ入るモデルが必要でした(やはりでかいモデルのほうが性能がいい) 比べて、後半のタスクであるXGBoostでの学習は、CPUです。Ryzen16コアを2つ持っているのですが、持ってなかったら死んでた…
- Pixivのイメージ200万枚を112x112にリサイズして、AutoEncoderで学習
- Encoderのみを取り出し、200万枚をベクトル化
- タグをXGBoostで学習
- 任意の入力の画像に対して、適切にタグが付与されるか
結果
学習に用いてないデータでの検証を行いました 予想できるタグは30000種類を超えており、多様性の視点では既存のDeepLearningを超えているかと思います

図3. 入力画像と予想出力値(下のタグの画像が真)
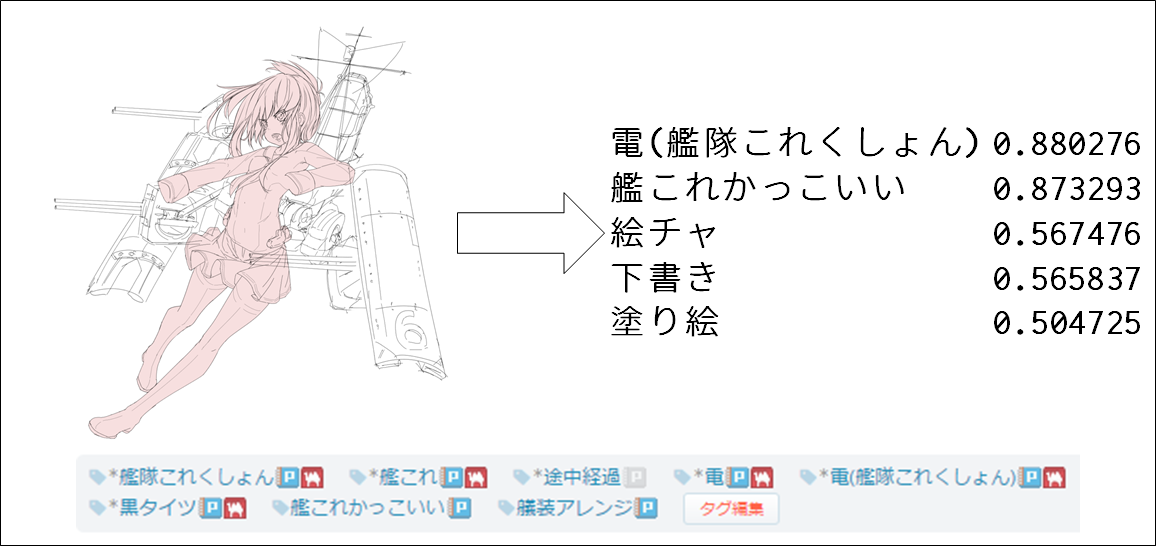
図4. 入力画像と予想出力値(下のタグの画像が真)

図5. 入力画像と予想出力値(下のタグの画像が真, 人物は間違った)
ある程度予想していたのですが、やはり、キャラクターの特定は、Pixiv社のタグの数の個数制限があり、なかなか難しかったです
そのかわり強いなって思ったのが、夜空・星空・下絵・海・ハートなど、全体の世界観などモヤッとしたものをつかむがうまかったです
Appendix.類似度
なお、このAutoEncoderの情報をうまく使えば、画像の類似度検索にも用いることができます 200次元程度なので、ある程度、意味のある類似度検索をすることができ、cosine類似度や、ユークリッド距離を図ったりしていたが どちらも、同等のパフォーマンスで、ランキングに大きな変動がなかったため、計算が早いユークリッドを用いました

図6. 一番上が検索クエリで、2,3番めが検索結果
illustration2vecと同様に、画像自体を検索クエリとすることができます 高速なマッチングも幾つか考案しましたが、余裕があるときにまたご紹介したいと思います
コード
AE. VAEは基礎的な特徴の研究から初めて、なんとか、いろいろ引き上げて使えるようにした感じです
keras-tiny-vaeがオートエンコーダ系で、特にこのPixivのタスクに限定したものではないコードですが、AE, VAEで特徴量を取り出します
PixivTagPredictorがタグを学習・予想するXGBoostのプログラムです
参考文献
ドメインにより意味が変化する単語の抽出
ドメインにより意味が変化する単語の抽出
立命館の学生さんが発表して、炎上した論文を、わたしもJSAI2017に参加していた関係で、公開が停止する前に入手することができました
論文中では、幾つかのPixivに公開されているBL小説に対して定性的な分類をして、終わりという、機械学習が入っていないような論文でしたので、わたしなりに機械学習を使ってできることを示したいという思いがあります。(そんなに大変な問題でないように見えて、かつ、問題設定も優れていたのに、なぜ…)
炎上に対して思うところ(主観です)
PixivのBLのコンテンツを参照し、論文にハンドル名を含めて記述してしまっており、作家の方に精神的な不可をかけてしまうという事件がありました。
非常にRTされている代表的なツイートは、以下のようになっています。
(該当ツイートは盗用との指摘を受けたので消しました、検索すれば出るものなで、大乗だと思います)
多くの人がいろいろなことを言っており、情報は混沌としています。
わたしが解決すべき問題と捉えているのは、二点です。
- 引用することで、不利益を被る人の対応と配慮 - 転載と引用の混同を正す
解決できるように鋭意、TPOをわきまえて話しましょう。良い未来が開けることを期待しています。
(アダルトドメインなどにおける)意味が変化する単語とは
元論文では、バナナなどの意味が変化するとされていますが、もう少し詳細に考えていましょう
文脈によって意味が変化するということが成り立つとき、たとは、「冷たい」とあっただけであっても、以下のような文脈依存で意味が変化しているようにみえることがあります。
例1.
アイスコーヒーを頼んだ。冷たい。こんなに夏の熱い日に、カフェで飲むコーヒーは最高だ。
例2.
事務的な口調で支持される。冷たい。彼はこんなに人間性に乏しかっただろうか。
温度が冷たいのか、人の人格が冷たいのか、文脈で人間なら簡単に理解できます。
人間だからこの文脈によりなにかしら、意味というか、感じ方が違うものをうまくピックアップすることはできないでしょうか
実はskip thoughtなどに代表される文章のベクトル化などの技術を使うとできるということを示します。
ドメインや文脈により意味が変化する語を抽出する
ドメインという粒度だと、多分ニュースサイトと、小説サイトでは、同じ単語を持っていても微妙にニュアンスが異なるかと思います。 skip gram的な考え方だと、周辺にある単語の分布を見ることで意味が決定すると言う仮説があります。その応用例がword2vecで馴染み深い物かもしれません。

図1. skip gram
Word2Vecではエンピリカルな視点から、意味がベクトル化されているということがわかっています
今回の提案では、これをより拡張して、単語の意味が周辺の文脈から何らかの影響を受けていると仮定して、モデルを作ります。

図2. 文脈により相対位置を決定
文脈を定義する
単語より大きな粒度である、文脈というものを明確に定義する必要があります
文脈の粒度を、文としました。文をベクトル化するのに、skip thought vector[1]や、doc2vec[2], fastText[3]などが利用できます
このベクトルに意味らしきものが含まれるかという議論ですが、ICML2016のtext2imageによると、文章ベクトルから画像の生成に成功していることから鑑みて、なんらかの特徴が内包されているかとわかります[4]

図3. Sentence Vectorizer
文章をベクトル化して、そのベクトルからの相対位置を決めるのは計算量的に面倒なので、量子化する
前後の文脈から、単語がどのようになるかは、求めることができそうのはわかりましたが、ベクトルの位置から計算していくというのは少々厄介なので、ベクトルを教師なしクラスタリング(kmean)で量子化します。 クラスタリングすると、文章がどのクラスに属するのか唯一に決まり、計算が楽です。

図4. 量子化
幅を決めて前後の文脈から単語を表現していく
単語をベクトル化するにはWindwos幅を決めて、前後を単語を見ていきますが、これにならない、前後の文章をみて単語に対してどのような文脈が偏在しているか、求めます。 今回は、前後の文章を三つ見ていきます。

図5. プログラム内部でのデータ構造のイメージ

図6. 文脈によりエンベッティングされた単語
実験
長くなりましたが、仮説とそれに伴う理論の構築がすみましたので、実験です。 仮説に寄ると、ドメインが異なると、単語の文脈が変化し通常と異なる分布になることが期待できます。 二つのコーパスを利用しました
この二つのコーパスから、文脈を考慮した単語ベクトルを作成し、同じ単語のcosine similarityが近い、遠いを計算し、直接的でないアダルトドメインのみ固有で意味が変化するものが定量的に検知できます。
結果
結果は、概ね良好かなという印象です
ただ、もっとデータがあるべきだなぁと思いました
やはり計算には膨大な時間が必要で、全データセットを計算して結果を得るのに24時間ぐらいの計算時間を要したので、それなりにパワーのあるマシンで計算することをおすすめします
CPU: Ryzen1700x Memoery: 48GByte
意味が変化する(consine similarityが遠い)単語トップ10です。
| 単語 | consine similarity |
|---|---|
| 肉 | 0.00152 |
| 増し | 0.00130 |
| 指 | 0.00130 |
| 発射 | 0.00122 |
| 喉 | 0.00116 |
| 繋がっ | 0.00103 |
| 熱い | 0.00101 |
| 当たる | 0.00095 |
| たっぷり | 0.00093 |
| 回し | 0.00093 |
| 握っ | 0.00050 |
表1. 文脈が変化している単語 top 10
また、意味が逆にそんなに遠くないものです。
| 単語 | cosine similarity |
|---|---|
| 思考 | 0.03889 |
| 原因 | 0.03745 |
| かつて | 0.03451 |
| 脳 | 0.03083 |
| 足首 | 0.03005 |
| 怪我 | 0.02739 |
| 無事 | 0.02721 |
| その間 | 0.02608 |
| 部下 | 0.02531 |
| 維持 | 0.02514 |
表2. 文脈が変化していない単語 top 10
考察
仮説を一個立てる必要がありましたが、既存のword2vec等が動作している仮説を担保としているため、間違いが無いように思います
このように、ドメインによって意味やニュアンスが異なる単語は、定量的なアプローチで分析することができるので、小説を定性的な視点から分析する価値をあまり感じなかったのですが、人によりアプローチは色々あると思います
今書いているコンテンツに応じて簡単にフィルタリングするべき単語などの抽出ができることが、分かりました
具体的な方法としては、基準となるドキュメントで生成した単語の文脈の分散表現と、ドメイン依存した暗喩や比喩などの分散表現は分布が異なるので、cosine similarityが遠くなることが期待できます
ソースコード
https://github.com/GINK03/DomainDependencyMemeJsai2017
deal.pyに一連の処理が記してありますが、コメントを要所にいれましたが、とにかく工程が多いので、どうしても解説が必要な方はツイッター等で聞いていただければ幸いです(アカデミアの方に限ります)
参考文献
[1] Sent2Vec
[2] Doc2Vec
[3] fastText
[4] ICML2016, text2image
[5] ノクターンノベルズ(R18です、注意してください)
Deep Furiganaを機械学習で自動でふる
Deep Furiganaを機械学習で自動でふる
注:今回、JSAI2017において、立命館大学の学生が発表した論文が、一部の小説家の方々の批判を浴びたそうですが、この内容はgithubにて炎上前から管理されていたプロジェクトであり、無関係です。
Deep Furiganaは、日本語の漢字に特殊な読み方を割り当てて、中二心をくすぐるものです
特殊な読み方(発音でなく文脈的な表現を表している)とすることが多く、外国人にとって日本語の学習の障害になっているということです。

図1. Fate Grand Orderのアルテラの場面、生命と文明を(おまえたち)と呼ばせる
つまりどういうことなのか
Deep Furiganaがある文脈の前後にて、生命と、文明と、おまえたちは、同等の意味を持っていると考えられます。 意味が等しいか、近しい中二っぽい単語をDeepFuriganaとして適応すればよいということになりそうです
ほかの例として、「男は故郷(ルビ:テキサス)のことを考えていた」これは、Deep Furiganaですが、これが書かれている小説の作中では、この”テキサス”と”故郷”には同じような単語の周辺分布を持つはずです。
1. 故郷とテキサスは、似た意味や用法として使われるのではないかという仮説が立ちます。
2. Deep Furiganaを多用するコンテンツは中二病に深く罹患したコンテンツ(アニメ・ゲーム・ラノベ等)などがアメリカの4chan掲示板で多いと報告されています
課題
Deep Furiganaは本来、発音する音でないですが、文脈的・意味的には、Deep Furiganaに言い換えられるということがわかりました。
しかも、言い換えたコンテンツが中二病的な文章になっているという制約が入っていそうです。
Deep Furiganaをコンピュータに自動的に振らせることは可能なのでしょうか。いくつかの方法を使えば可能なように思わます。
1(文脈的に使用法が類似しており)かつ2(できるだけ中二っぽい単語の選択)が、最もDeep Furiganaらしいといえそうです
普通のニュースなどの文章にDeep Furiganを振ってみましょう。
機械学習でやっていきます。
説明と、システム全体図
やろうとしていることは、手間は多いですが、単純です。
- fastTextのセンテンスベクタライザで、小説家になろうの文章と、Yahoo Newsの文章をベクトル化します。
- 小説家になろうの文章をLabel1とし、Yahoo Newsの文章をLabel2とします
- このラベルを当てられるようにliblinearでlogistic-regressionで学習していきます
- ロジスティック回帰は確率として表現できるので、確率値で分類できるモデル*1を構築します
- 任意の文章の単語を(マルコフ)サンプリングで意味が近いという制約を課したまま、小説家になろうの単語に変換*2します
- このサンプリングした変換候補の文章の中からもっとも小説家になろうの文章であると*1を騙せた文章を採択します
- 再帰構造になっており、*2に戻ります
これをプログラムに落としたら、多くの前処理を含む、巨大なプロシージャになってしまいました。 理解せず、作ることが難しいシステムですが、全体の流れを正確に自分の中でイメージして、把握しておくことで、構築が容易になります。

図2. 各単語のベクトル化と、変換に使う候補である単語の一覧を作成

図3. Yahoo Newsとなろうの文章を文章全体でベクトル化して、判別問題に変換する

図4. 2,3で作成したモデルをもとに、変換候補の単語をサンプリング、なろうの確率が最大となる変換を見つける
実験環境
データセット
Yahoo News 100000記事 小説家になろう、各ランクイン作品40位まで
学習ツール
liblinear fastText
パラメータ等
liblinear( logistic, L2-loss ) fastText( nchargram=disable, dimentions=256, epoch=5 )
実行環境
- Ubuntu 17.04 - Core i5 - 16GByteMemory
実験結果
実際にこのプログラムを走らせると、このようになります
iterationごとの、なろう確率の変化
最初はあまりなろうっぽくないもととなる文章ですが、様々な単語選択をすることで、だんだん判別機を騙しに行けるようになってきます
これは、実はGANの敵対的学習に影響を受けており、SeqGANの知識を使いまわしています[1]。

図5. イテレーション(単語の探索をする)ごとに、判別機をだんだん騙せるようになっている
sample.1
基の文章が、このような感じ
大きな要因の一つにツイッターやフェイスブック、ブログの普及で、他者の私生活の情報が手に入りやすくな>ったことが挙げられるのではないでしょうか。以前よりも、他者と比べる材料がずっと増えたわけです。
なろうに可能な限り意味を保持し続けて、単語を置き換えた場合
大きな俗名の一つにツイッターやヴァイオレンス、絵日記の普及で、一片のコウウンキの情報が両手に入りやすくなったことが挙げられるのではないでしょうか。前回よりも、一片と比べる硝石がずっと増えたわけです。
これを連結すると
大きな要因<<俗名>>の一つにツイッターやフェイスブック<<ヴァイオレンス>>、ブログ<<絵日記>>の普及で、他者<<一片>> の私生活<<コウウンキ>>の情報が手<<両手>>に入りやすくなったことが挙げられるのではないでしょうか。以前<<前回>>よりも、他者<<一片>>と比べる材料<<硝石>>がずっと増えたわけです。
このようになります。 ちょっと中二チックですね。 Facebookがヴァイオレンス(暴力?)と近しいとか、まぁ、メンタルに関する攻撃といって差し支えないので、いいでしょう。 ブログを絵日記という文脈で言い換えたり、以前を前回と言い換えたりすると中二属性が上がります。
sample.2
もとの文章はこのようになっています
「ランサムウエア(身代金要求型ウイルス)」という名のマルウエア(悪意を持ったソフトウエア)がインターネット上で大きな話題になっている。報道によると、5月12日以来、ランサムウエアの新種「WannaCry」の被害がすでに150カ国23万件以上に及んでおり、その被害は日に日に拡大中だ。
変換後がこのようになる
「ランサムウエア(捕虜ヴェンデン型カイコ)」という片羽のマルブラトップ(敵意を持ったソフトウエア)が奈良公園で大きな話題になっている。命令違反によると、5月12日以来、ランサムウエアの冥界「WannaCry」の二次被害がすでに150カ国23万件半数に及んでおり、その二次被害は日に日に産地偽装オオトカゲだ。
これを連結すると
「ランサムウエア(身代金<<捕虜>>要求<<ヴェンデン>>型ウイルス<<カイコ>>)」という名<<片羽>>のマルウエア(悪意<<敵意>>を持ったソフトウエア)がインターネット上<<奈良公園>>で大きな話題になっている。報道<<命令違反>>によると、5月12日以来、ランサムウエアの新種<<冥界>>「WannaCry」の被害<<二次被害>>がすでに150カ国23万件以上<<半数>>に及んでおり、その被害<<二次被害>>は日に日に拡大<<産地偽装>>中<<オオトカゲ>>だ。
悪意が敵意になったり、新種が冥界になったり、以上が半数になったり、被害が二次被害になったりします。なろうでは、こういう単語が好まれるのかもしれません 拡大中が産地偽装オオトカゲとなったのは、作品に対する依存性があるのだと思います
まとめ
おお、これが、DeepFuriganaかって感動はちょっとずれた視点になりましたが、意味を維持しつつ、学習対象のラノベ等に近づけるという技も可能でした
例えば、判別機をCharLevelCNNにしてみると、より人間書く小説に近い文体になるということがあるかもしれません
学習データの作品に強く影響を受ける、かつ、特定の作品の特定のシーンに寄ることがあって、エッチな単語に言い換え続けてしまう方にだましに行ってしまうというのもありました
問題設定によってはDeepFurigana以外にも使えそうです
コード
githubにて管理しております。
前処理用のコード
$ python3 narou_deal.py {引数}
引数説明
- –step1: 小説家になろうをスクレイピング
- –step2: 小説家になろうを形態素解析
- –step3: Yahoo Newsを必要件数取得(ローカルに記事をダウンロードしている必要あり)
- –step4: なとうとYahooの学習の初期値依存性をなくすために、データを混ぜる
- –step5: fastTextで単語の分散表現を獲得
- –step6: fastTextの出力をgensimに変換する
- –step7: なろうとYahooの判別機を作るために、データにラベルを付ける
- –step8: テキスト情報をベクトル化するためのモデルを作ります
- –step9: なろうに存在する名詞を取り出して変換候補をつくります
- –step10: なろうと、Yahooのテキストデータをベクトル化します
- –step11: liblinearで学習します
- –step12: データセットが正しく動くことを確認します
DeepFuriganaを探索的に探していくプログラム
$ python3 executor.py
データセット
5.5GByteもあるのでDropboxは使えないし、どうしようと悩んでいたのですが、TwitterでBitTorrentのプロトコルを利用するといいみたいなお話をいただき、自宅のサーバを立ち上げっぱなしにすることで、簡単に構築できそうなので、TorrentFileで配布したいと思います。
日本ではまだアカデミアや企業の研究者が使えるトラッカーが無いように見えるので、いずれ、どなたかが立ち上げる必要がありますね。
(つけっぱなしで放っておけるWindowが今無いのでしばらくお待ちください)
$ {open what your using torrent-client} deep_furigana_vars.torrent
参考文献
[1] SeqGAN論文
[2] The Bittorrent P2P File-Sharing System: Measurements and Analysis