KerasのRNNでFizzBuzzを行う(+ Epochスケジューラの提案)
KerasのRNNでFizzBuzzを行う(+ Epochスケジューラの提案)
ディープラーニングをやるようになって半年程度経ちました
ある程度ならば、文章や画像判別モデルならば、過去の自分の資産をうまく活用することと、外部からState of the Artな手法を導入することで、様々なネットワークを組むことが可能になってまいりました
しかし、基礎の基礎であるはずの、Fizz Buzzをやるのを忘れていたのです
やるしかありません
先行研究
全結合のモデルでの、Fizz Buzzの評価のようです
提案
RNNでも、FizzBuzzは可能なのではないでしょうか
全結合層のモデルのみで、1000 ~ 5000程度のデータで学習させることが多いですが、20万件のデータセットで学習させることで、より大きな数字にも対応させることを目標とします
カリキュラム学習という学習法があり、簡単な問題設定から初めて、徐々に難しくしていくことで、早く安定的に学習できるそうです[1]
この時、人間がカリキュラムを意図して簡単な問題を用意して学習させるのではなく、学習のデータを最初のうちは限定したデータセットにて学習させ、限定したデータを覚えてきたらデータを拡大し、様々なケースを学習させて、汎化性能を獲得していくという学習方法をとります
具体的には、データセットとepochにスケジューラを組み込むことで実現します
モデル
‘1:Fizz, 2:Buzz, 3:Fizz Buzz, 4:そのまま(Path)'と4値の判別問題を全結合層2層でといている問題設定が多いが、 '1:Fizz, 2:Buzz, 3:Path'の3値のそれぞれの状態を求める問題設定とする

図1. 使用したモデル
コードはKerasを利用した モデルとスケジューラは、非常に小さく、わかりやすいです モデル
inputs = Input(shape=(10, 11)) encoded1 = Bi( GRU(256, activation='relu') )(inputs) encoded1 = Dense(512, activation='relu')( encoded1 ) encoded1_1x = Reshape((1,512,))(encoded1) decoded = Dense(3, activation='sigmoid')( Flatten()(encoded1_1x) ) fizzbuzz = Model(inputs, decoded) fizzbuzz.compile(optimizer=Adam(), loss='binary_crossentropy')
スケジューラ(初期のデータセットは、epochを多く学習し、後半になるにつれ一回のみにスケジューリングしている)
class CURRICULUM: EPOCH = [50, 30, 20, 10, 5, 1] @staticmethod def GET(): if len(CURRICULUM.EPOCH) > 0: return CURRICULUM.EPOCH.pop(0) else: return 1 ... fizzbuzz.fit(Xs, Ys, epochs=CURRICULUM.GET(), callbacks=[batch_callback]) ...
コードや日本語では伝えるのに私の貧困なコミュ力では難しかったので、画像を添付しますと、このような差があります

図 2. スケジューリングなし

図 3. スケジューリングあり
このように、学習初期に置いて、学習するデータを非対称にして、最初のデータは多めに繰り返し学習させます
実験
200,000件のFizz Buzzのデータセットを、スクリプトで作成し、5000件ずつ、データセットを分割し40個のデータセットを学習させる
この時、スケジューリングモデルAは、任意のデータセットをランダムで選択し、以下のepoch回、学習する
{ 1回目:50epoch, 2回目:30epoch, 3回目:20epoch, 4回目:10epoch, 5回目:5epoch }
このスケジューリングが完了した後は、残りのデータセットを1epochで学習する
スケジューリングモデルBは特にスケジューリングは行わず、全てのデータセットを平等に学習していく。なお、この方法は、全てのデータセットをメモリ上に乗せて順番に学習していく方法と変わらない
評価
スケジューリングモデルA(青)とモデルB(赤)で大きな差がでた
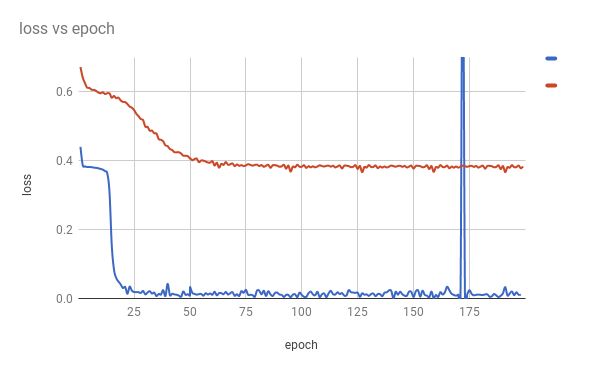
図4. trainデータのepochごとのlossの変化
ニューラルネットワークの初期値の依存性を考慮しても、この差は大きく、スケジューリングを行うことが、まともに収束するしないなどの差を担っているように思われる
モデルAはテストデータにおける精度100%であった
モデルBは68%であった
なお、出力はこのようになっている 左から、入力値、人手による結果、予想値、正解だったかどうか、である(PATHとは、そのまま出力するという意味にしました) ほぼ100%あっていることが確認できた
64170 original result = Fizz Buzz , predict result = Fizz Buzz , result = True
9791 original result = Path , predict result = Path , result = True
54665 original result = Buzz , predict result = Buzz , result = True
118722 original result = Fizz , predict result = Fizz , result = True
97502 original result = Path , predict result = Path , result = True
186766 original result = Path , predict result = Path , result = True
153331 original result = Path , predict result = Path , result = True
7401 original result = Fizz , predict result = Fizz , result = True
117939 original result = Fizz , predict result = Fizz , result = True
22732 original result = Path , predict result = Path , result = True
73516 original result = Path , predict result = Path , result = True
144774 original result = Fizz , predict result = Fizz , result = True
32783 original result = Path , predict result = Path , result = True
67097 original result = Path , predict result = Path , result = True
116715 original result = Fizz Buzz , predict result = Fizz Buzz , result = True
21195 original result = Fizz Buzz , predict result = Fizz Buzz , result = True
コード
https://github.com/GINK03/keras-rnn-fizzbuzz-on-dev
テストデータを作成する
$ python3 data_utils.py --step1
学習する(全体の8割を学習します)
$ python3 fizzbuzz.py --train
予想する(テストデータから予想します)
$ python3 fizzbuzz.py --predict
感想
データによってはまともに収束してくれないものあり、RNNではその傾向が特に顕著です 精確にロス率の違いなどを測ったことがなかったのですが、Epochをいじることによって、安定して学習させることができることがあるということでした