XGBoost fizzbuzz
XGBoostのFizzBuzzです
勾配ブースティングでもFizzBuzzできるという例を示します
やろうと思った動機
DeepLearningならばFizzBuzzの3の倍数と5の倍数と15の倍数の時に、特定の動作をするというルールを獲得することは容易なのですが、他の機械学習アルゴリズムはどうでしょうか
XGBoostはその決定木の性質と、勾配ブースティングの学習アルゴリズムを解析的に説明した論文の内容を見ると、特定のルールを獲得することは難しくないんじゃないかと思いました[1]
ただ、FizzBuzzを数値として扱ってしまうと、かなり厄介で、連続する値が大きい小さいなどで判別するのは容易ではありません
DeepLearning時と同じように、Character Levelで入力を扱います
具体的な数値データの取り扱い
数字を文字表現として皆して、各桁の数字を一つの特徴量として扱います

クラスの設定、目的関数の設定
クラスは"3の倍数の時のFizz",“5の倍数の時のBuzz”,“15の倍数の時のFizzBuzz”,“その他"の時の4つのクラスの分類問題にしました
softmaxではなくて、softprobを用いました
ドキュメントを読むと、各クラスの所属する確率として表現されるようです(クラスの数ぶん、sigmoidが配置されていると、同じ?)
学習データ
0〜99999までの数字の各FizzBuzzを利用します
この時、2割をランダムでテストデータに、8割を学習データに分割します
各種パラメータ
このようにしました、もっと最適な設定があるかもしれないので、教えていただけると幸いです
etaが大きいのは、極めてroundが多いので、これ以上小さくするとまともな時間に学習が完了しません
booster = gbtree objective = multi:softprob num_class = 4 eta = 1.0 gamma = 1.0 min_child_weight = 1 max_depth = 100 subsample = 0.8 num_round = 100000 save_period = 1000 colsample_bytree = 0.9 data = "svm.fmt.train" eval[test] = "svm.fmt.test" #eval_train = 1 test:data = "svm.fmt.test"
プログラムの解説
githubにコードが置いてあります
データセットの準備
$ python3 createDataset.py --step1 # データセットの作成 $ python3 createDataset.py --step2 # 前処理 $ python3 createDataset.py --step3 # libsvmフォーマットを作成
学習
(xgboost.binはubuntu linux 16.04でコンパイルしたバイナリです。環境に合わせて適宜バイナリを用意してください)
(学習には、16コアのRyzen 1700Xで2時間程度かかります)
$ ./xgboost.bin fizzbuzz.train.conf
予想
(必要に応じて、使用するモデルを書き換えてください)
$ ./xgboost.bin fizzbuzz.predict.conf
精度の確認
$ python3 predCheck.py
精度
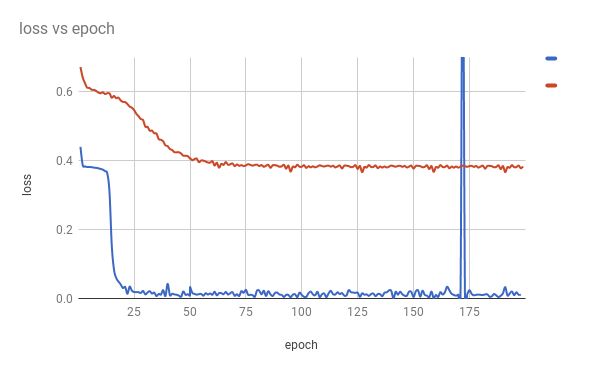
50000roundでテストデータで以下の精度が出ます
acc 0.9492
出力はこのようになります
12518 predict class = 3 real class = 3
42645 predict class = 2 real class = 0
15296 predict class = 3 real class = 3
47712 predict class = 3 real class = 1
1073 predict class = 3 real class = 3
66924 predict class = 1 real class = 1
82852 predict class = 3 real class = 3
26043 predict class = 1 real class = 1
96556 predict class = 3 real class = 3
81672 predict class = 1 real class = 1
44018 predict class = 3 real class = 3
16622 predict class = 3 real class = 3
79924 predict class = 3 real class = 3
15290 predict class = 2 real class = 2
25276 predict class = 3 real class = 3
class 2は15の倍数なのですが、これの獲得が難しいようです
liblinear(support vector classification)との比較
一応、違う機械学習との比較ともやるべきでしょう
L2-regularized L2-loss support vector classificationで動作する、liblinearで比較しました
$ ./train -s 1 svm.fmt.train ....*.* optimization finished, #iter = 52 Objective value = -56679.234880 nSV = 64068 .....* optimization finished, #iter = 51 Objective value = -56678.857821 nSV = 65083 ....*. optimization finished, #iter = 50 Objective value = -14306.576984 nSV = 17032 .....* optimization finished, #iter = 51 Objective value = -14305.608585 nSV = 16957
$ ./predict svm.fmt.test svm.fmt.train.model output Accuracy = 66.2298% (13240/19991)
精度が66%しか出ていません
やはり、XGBoostの精度で判別をすることはできないようです
まとめ
DeepLearningでは精度100%を達成できましたが、XGBoostでは95%程度の精度です
完全なルールの獲得は怪しいですが、それでもかなりいいところまで行っているようです
また、目的関数を複数ラベルを取れるようにするなど、うまく設計すれば、もっといけるでしょう(勾配ブースティングのマルチラベル分類、どうやるんだろう)